CSES Solutions – Substring Distribution
Last Updated :
29 Apr, 2024
You are given a string of length N. For every integer between 1 to N you need to print the number of distinct substrings of that length.
Prerequisites to Solve this problem: Suffix arrays, LCP
Examples:
Input: str=”abab”
Output: 2 2 2 1
Explanation:
- for length n=1, distinct substrings: {a, b}
- for length n=2, distinct substrings: {ab, ba}
- for length n=3, distinct substrings: {aba, bab}
- for length n=4, distinct substrings: {abab}
Input: str=”abc”
Output: 3 2 1
Explanation:
- for length n=1, distinct substrings: {a, b, c}
- for length n=2, distinct substrings: {ab, bc}
Approach using Suffix array and Longest Common Prefix(LCP):
Suffix Arrays: A suffix array is a sorted array of all suffixes of a given string. The suffixes are usually represented as integers, which are the starting indices of the suffixes in the string.
Longest Common Prefix (LCP) Array: The LCP array is an auxiliary data structure that stores the length of the longest common prefix between any two consecutive suffixes in the sorted suffix array.
The below image shows how Suffix array and LCP array look for a string “BANANA”
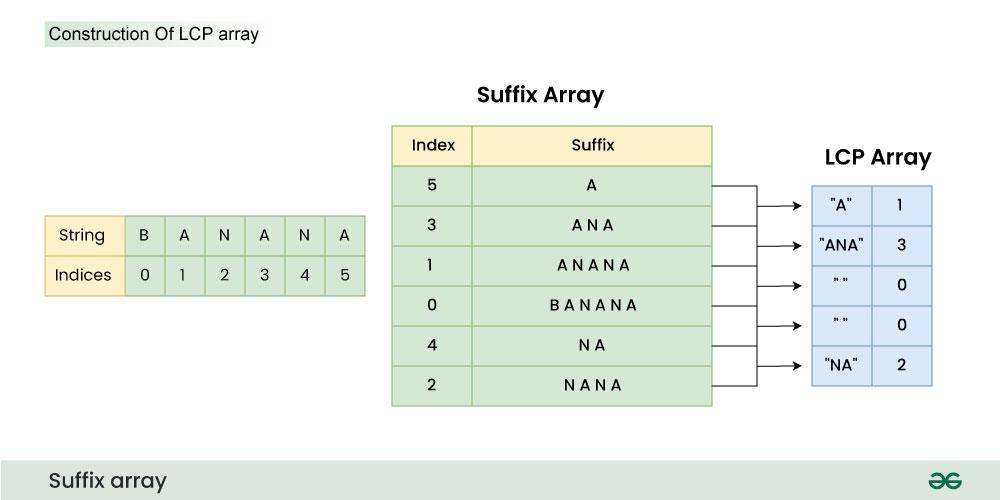
Key Observations:
- For string of length N, the contribution of unique substrings for given suffix at index i is Suffix[i] = N – Suffix[i] – LCP[i]
- Proof:
N - Suffix[i] represents the total number of substrings that do not start from index i (including substrings that start from previous suffixes).- Now,
LCP[i] represents the number of substrings shared with the next suffix. Subtracting LCP[i] from N - Suffix[i] removes the common substrings shared with the next suffix, leaving only the unique substrings contributed by the suffix starting at index i - Therefore,
Suffix[i] = N - Suffix[i] - LCP[i] represents the number of unique substrings contributed by the suffix starting at index i.
- This means that for a given suffix, it will contain unique substrings of lengths from LCP[i]+1 to N – Suffix[i].
So, for each suffix in the suffix array, you can calculate the range of lengths of unique substrings it contributes, and update the count of substrings of those lengths accordingly.
Building Suffix Array: The buildSuffixArray function is used to build the suffix array for the input string. It starts by initializing the suffix array and the position array. Then it sorts the suffix array based on the characters at the current gap. The gap is initially 1 and is doubled in each iteration. The position array is updated in each iteration based on the sorted suffix array.
Building LCP Array: The buildLCPArray function is used to build the LCP array for the input string and its suffix array. It iterates over the suffix array and calculates the longest common prefix length for each pair of consecutive suffixes in the sorted suffix array.
Counting Distinct Substrings: After building the suffix array and the LCP array, the next step is to count the number of distinct substrings of each length. This is done by iterating over the LCP array and updating the prefix count array. For each index i in the LCP array, the number of distinct substrings of length greater than LCP[i] and less than or equal to the length of the suffix denoted by suffixArray[i] is incremented. The number of distinct substrings of length greater than the length of the suffix denoted by suffixArray[i] is decremented.
Step-by-Step algorithm:
- Take MAX_LENGTH as the maximum length of the string, suffixArray, position, temp, and longestCommonPrefix are arrays used in the algorithm, gap and stringLength are integers used to store the gap for comparison and the length of the string respectively, and str is the string for which the suffix array and LCP array are to be built.
- Comparator Function: The compare function is used to sort the suffix array. It compares two suffixes of the string based on their positions and the gap.
- Build Suffix Array: The buildSuffixArray function builds the suffix array for the string. It initializes the suffix array and position array, and then sorts the suffix array using the compare function. The position array is updated after each sort.
- Build LCP Array: The buildLCPArray function builds the Longest Common Prefix (LCP) array for the string. It calculates the longest common prefix length for each pair of consecutive suffixes in the sorted suffix array.
- Call the buildSuffixArray and buildLCPArray functions to build the suffix array and LCP array, and then calculates the prefix count for each prefix length. The prefix count is then printed.
Implementation of above approach
C++
#include <bits/stdc++.h>
using namespace std;
// Define constants and global variables
const int MAX_LENGTH
= 1e5 + 5; // Maximum length of the input string
int suffixArray[MAX_LENGTH], position[MAX_LENGTH],
temp[MAX_LENGTH], longestCommonPrefix[MAX_LENGTH];
int gap, stringLength; // Variables for building suffix
// array and LCP array
string str; // Input string
// Comparator function for sorting suffix array
bool compare(int x, int y)
{
// Compare the positions of suffixes
if (position[x] != position[y])
return position[x] < position[y];
x += gap;
y += gap;
// If both suffixes are within the string length,
// compare their positions
return (x < stringLength && y < stringLength)
? position[x] < position[y]
: x > y;
}
// Function to build the suffix array
void buildSuffixArray()
{
// Initialize suffix array and position array
for (int i = 0; i < stringLength; i++)
suffixArray[i] = i, position[i] = str[i];
// Build the suffix array using doubling technique
for (gap = 1;; gap <<= 1) {
// Sort the suffix array based on the current gap
sort(suffixArray, suffixArray + stringLength,
compare);
// Update temporary array for position calculation
for (int i = 0; i < stringLength - 1; i++)
temp[i + 1] = temp[i]
+ compare(suffixArray[i],
suffixArray[i + 1]);
// Update position array
for (int i = 0; i < stringLength; i++)
position[suffixArray[i]] = temp[i];
// Check if all suffixes are in lexicographically
// sorted order
if (temp[stringLength - 1] == stringLength - 1)
break;
}
}
// Function to build the LCP array
void buildLCPArray()
{
for (int i = 0, k = 0; i < stringLength; i++) {
if (position[i] != stringLength - 1) {
int j = suffixArray[position[i] + 1];
// Compute the length of common prefix between
// suffixes
while (str[i + k] == str[j + k])
k++;
longestCommonPrefix[position[i]] = k;
if (k)
k--; // Decrement k if it is non-zero
}
}
}
int prefixCount[MAX_LENGTH]; // Array to store cumulative
// count of distinct substrings
// Driver code
int main()
{
// Input string (change this to your desired input)
str = "abab";
// Compute suffix array and LCP array
stringLength = str.size();
buildSuffixArray();
buildLCPArray();
// Calculate the number of distinct substrings
int previous = 0;
for (int i = 0; i < stringLength; i++) {
prefixCount[previous + 1]++;
prefixCount[stringLength - suffixArray[i] + 1]--;
previous = longestCommonPrefix[i];
}
// Compute the cumulative count of distinct substrings
for (int i = 1; i <= stringLength; i++) {
cout << prefixCount[i] << ' ';
prefixCount[i + 1] += prefixCount[i];
}
return 0;
}
import java.util.HashSet;
import java.util.Set;
public class Main {
static Set<String> distinctSubstrings(String s) {
int n = s.length();
Set<String> substrings = new HashSet<>();
for (int i = 0; i < n; i++) {
for (int j = i + 1; j <= n; j++) {
substrings.add(s.substring(i, j));
}
}
return substrings;
}
static int[] countDistinctSubstrings(String s) {
Set<String> substrings = distinctSubstrings(s);
int[] counts = new int[s.length()];
for (String substring : substrings) {
counts[substring.length() - 1]++;
}
return counts;
}
public static void main(String[] args) {
String s = "abab";
int[] counts = countDistinctSubstrings(s);
for (int count : counts) {
System.out.print(count + " ");
}
}
}
def distinct_substrings(s):
n = len(s)
substrings = set() # Initialize an empty set to store the substrings
for i in range(n):
for j in range(i+1, n+1):
substrings.add(s[i:j]) # Add each substring to the set
return substrings # Return the set of substrings
def count_distinct_substrings(s):
substrings = distinct_substrings(s) # Get all distinct substrings
counts = [0] * len(s)
# Count the number of substrings of each length
for substring in substrings:
counts[len(substring)-1] += 1
return counts # Return the counts
def main():
s = "abab" # Define the string
counts = count_distinct_substrings(s)
print(*counts) # Print the counts
if __name__ == "__main__":
main()
function distinctSubstrings(s) {
const n = s.length;
const substrings = new Set();
for (let i = 0; i < n; i++) {
for (let j = i + 1; j <= n; j++) {
substrings.add(s.substring(i, j));
}
}
return substrings;
}
function countDistinctSubstrings(s) {
const substrings = distinctSubstrings(s);
const counts = new Array(s.length).fill(0);
substrings.forEach(substring => {
counts[substring.length - 1]++;
});
return counts;
}
function main() {
const s = "abab";
const counts = countDistinctSubstrings(s);
console.log(counts.join(" "));
}
// Calling the main function
main();
Time Complexity: O(nlogn)
Auxiliary Space: O(n)
Share your thoughts in the comments
Please Login to comment...