Create a Pipeline in Pandas
Last Updated :
17 Jan, 2022
Pipelines play a useful role in transforming and manipulating tons of data. Pipeline are a sequence of data processing mechanisms. Pandas pipeline feature allows us to string together various user-defined Python functions in order to build a pipeline of data processing. There are two ways to create a Pipeline in pandas. By calling .pipe() function and by importing pdpipe package.
Through pandas pipeline function i.e. pipe() function we can call more than one function at a time and in a single line for data processing. Let’s understand and create a pipeline by using the pipe() function.
Below are various examples that depict how to create a pipeline using pandas.
Example 1:
Python3
import pandas as pd
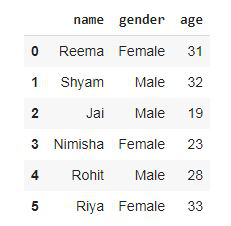
df = pd.DataFrame()
df['name'] = ['Reema', 'Shyam', 'Jai',
'Nimisha', 'Rohit', 'Riya']
df['gender'] = ['Female', 'Male', 'Male',
'Female', 'Male', 'Female']
df['age'] = [31, 32, 19, 23, 28, 33]
df
|
Output:
Now, creating functions for data processing.
Python3
def mean_age_by_group(dataframe, col):
return dataframe.groupby(col).mean()
def uppercase_column_name(dataframe):
dataframe.columns = dataframe.columns.str.upper()
return dataframe
|
Now, creating a pipeline using .pipe() function.
Python3
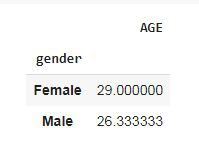
pipeline = df.pipe(mean_age_by_group, col='gender').pipe(uppercase_column_name)
pipeline
|
Output:
Now, let’s understand and create a pipeline by importing pdpipe package.
The pdpipe Python package provides a concise interface for building pandas pipelines that have pre-conditions. The pdpipe is a pre-processing pipeline package for Python’s panda data frame. The pdpipe API helps to easily break down or compose complex-ed panda processing pipelines with few lines of codes.
We can install this package by simply writing:
pip install pdpipe
Example 2:
Python3
import pdpipe as pdp
import pandas as pd
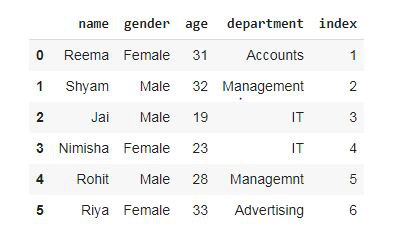
dataset = pd.DataFrame()
dataset['name'] = ['Reema', 'Shyam', 'Jai',
'Nimisha', 'Rohit', 'Riya']
dataset['gender'] = ['Female', 'Male', 'Male',
'Female', 'Male', 'Female']
dataset['age'] = [31, 32, 19, 23, 28, 33]
dataset['department'] = ['Accounts', 'Management',
'IT', 'IT', 'Management',
'Advertising']
dataset['index'] = [1, 2, 3, 4, 5, 6]
dataset
|
Output:
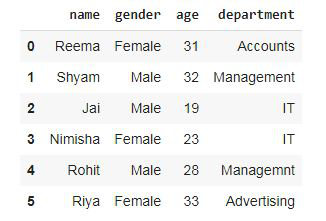
Removing a column from dataframe using pdpipe.
Python3
dropCol = pdp.ColDrop("index").apply(dataset)
dropCol
|
Output:
There is another way to drop columns through pdpipe.
Python3
dropCol2 = pdp.ColDrop("index")
df2 = dropCol2(dataset)
df2
|
Output:
Here, the column is dropped in two steps. In the first step, we created a pipeline and in the second step, we applied it to the dataframe.
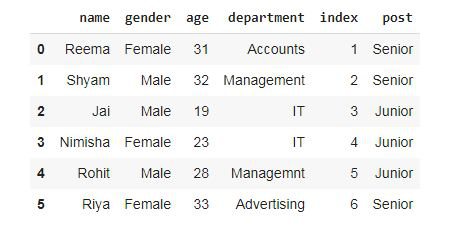
Example 3:
Now we are adding one column to dataframe using pdpipe.
Python3
import pdpipe as pdp
import pandas as pd
dataset = pd.DataFrame()
dataset['name'] = ['Reema', 'Shyam', 'Jai',
'Nimisha', 'Rohit', 'Riya']
dataset['gender'] = ['Female', 'Male', 'Male',
'Female', 'Male', 'Female']
dataset['age'] = [31, 32, 19, 23, 28, 33]
dataset['department'] = ['Accounts', 'Management',
'IT', 'IT', 'Management',
'Advertising']
dataset['index'] = [1, 2, 3, 4, 5, 6]
dataset
|
Output:
Now, dropping the values from dataframe.
Python3
df3 = pdp.ValDrop(['IT'],'department').apply(dataset)
df3
|
Output:
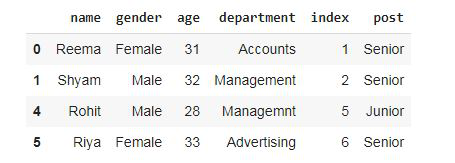
The row containing ‘ IT ‘ value is dropped.
Share your thoughts in the comments
Please Login to comment...