Wide and Narrow Dependencies in Apache Spark
Last Updated :
03 May, 2024
Apache Spark, a powerful distributed computing framework, is designed to process large-scale datasets efficiently across a cluster of machines. However, Dependencies play a crucial role in Spark’s performance, particularly concerning shuffling operations. Shuffling, which involves moving data across the network, can significantly impact latency and efficiency. Understanding dependencies helps anticipate when shuffling might occur. Wide and Narrow dependencies define how data is partitioned and transferred between different stages of a Spark job.

The degradation for the performance is primarily due to the nature of dependencies between RDDs (Resilient Distributed Datasets) in Spark transformations.
RDDs (Resilient Distributed Datasets) in Apache Spark are composed of four parts namely:
- Partitions : RDDs are divided into smaller, distributed chunks called partitions , and these partitions are distributed across multiple nodes in a cluster (the workers).
- Dependencies : They model relationships between a RDD and its partitions , with the RDD it was derived from.
- Functions : They represent operations applied to RDD partitions to derive new RDDs. (such as map or filter).
- Metadata : It contains information about partitioning scheme and placement of data within partitions.
In Apache Spark, understanding the concepts of wide and narrow dependencies is crucial for optimizing performance, especially when dealing with large-scale datasets. In this article we will focus on the dependencies in Spark.
Wide and narrow dependencies in Apache Spark
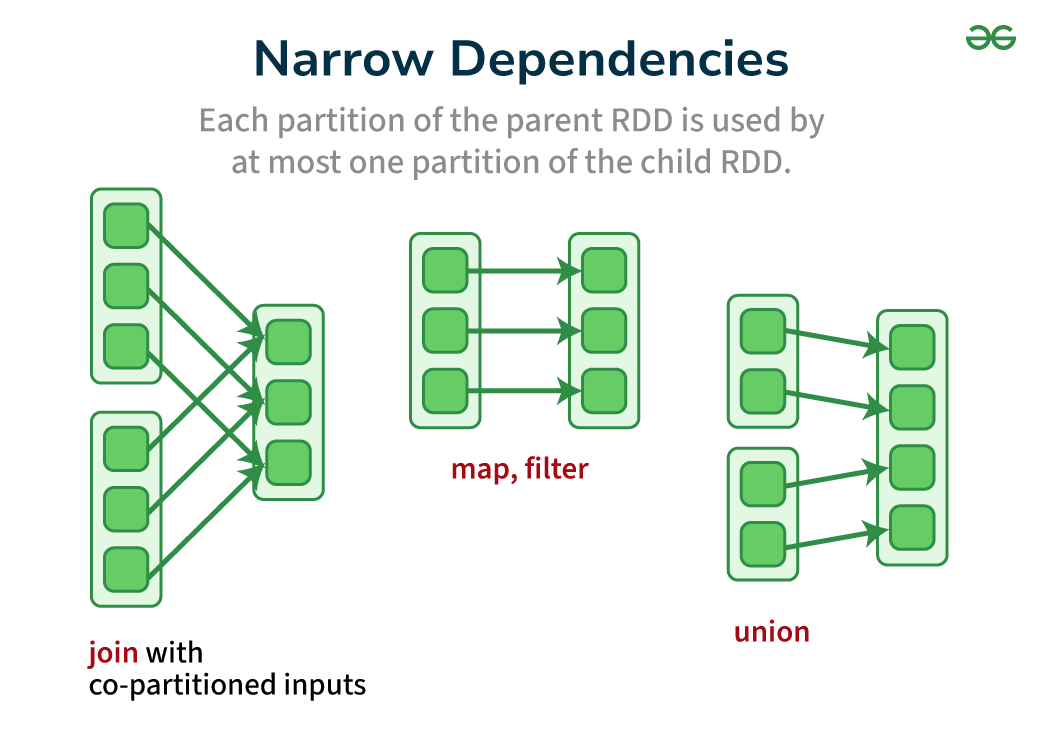
What is Narrow Dependency in Apache Spark?
In Apache Spark, a narrow dependency refers to a specific type of relationship between two Resilient Distributed Datasets (RDDs). It describes how partitions in a child RDD rely on data from the parent RDD.
- One-to-one Mapping: Each partition in the child RDD depends on at most one partition from the parent RDD. This means a child partition only processes data from a single corresponding parent partition.
- Faster Execution: Narrow dependencies enable optimizations like pipelining. In pipelining, the output of one transformation can be used as the input for the next transformation without waiting for the entire parent RDD to be processed. This improves efficiency.
- Reduced Shuffling: Since each child partition has a specific parent partition to access, there’s no need to shuffle data across the network. Shuffling refers to the movement of data between different worker nodes in the Spark cluster.
Examples of Transformations that create Narrow Dependencies in Apache Spark
- Map: Applies a function to each element in an RDD, resulting in a new RDD with one output element for each input element.
- Filter: Selects elements based on a predicate function, keeping only those that meet the criteria.
- Union: Combines two compatible RDDs into a single RDD.
- Join: Joins can be either wide or narrow depending on the partitioning scheme. If the parent datasets are partitioned on the join key, the join becomes a narrow dependency because each child partition only needs data from the corresponding partition of each parent.
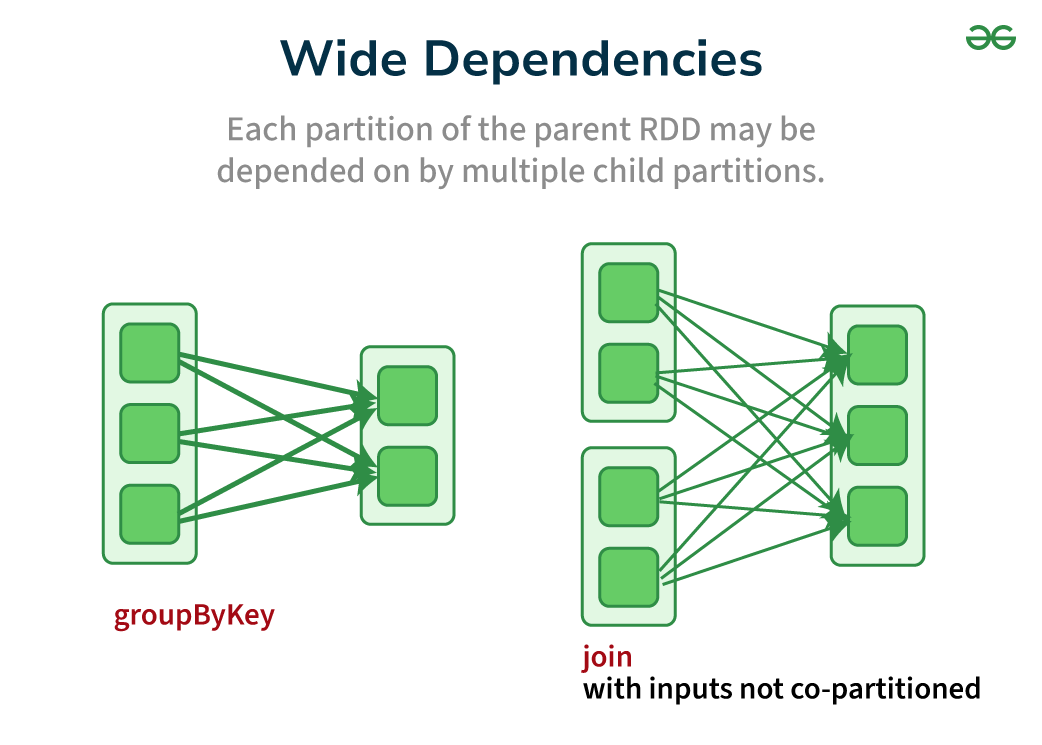
What is Wide Dependency in Apache Spark?
In Apache Spark, a wide dependency is the opposite of a narrow dependency. It describes a relationship between RDDs where a child RDD’s partitions depend on data from multiple partitions of the parent RDD.
- Many-to-One Mapping: Each partition in the child RDD might need data from several partitions of the parent RDD. This necessitates shuffling data across the network to bring the required data together.
- Slower Execution: Wide dependencies often involve shuffling, which can be a bottleneck. Shuffling data across the network takes time and resources, impacting the overall performance of your Spark application.
- Increased Complexity: Wide dependencies can make it more challenging to optimize Spark jobs. Pipelining becomes less efficient as transformations might need to wait for shuffled data before proceeding.
Examples of transformations that create Wide Dependencies
- GroupByKey: Groups elements in an RDD by a key, bringing elements with the same key together. Since elements with the same key can reside in different parent partitions, shuffling is needed.
- Join: Merges two RDDs based on a join condition. Similar to groupByKey, elements with matching join keys might be scattered across partitions, leading to shuffling.
- ReduceByKey: Applies a reduction function (like sum or count) to elements with the same key. This often involves shuffling to aggregate matching elements before reduction.
Best Practices for Performing Wide Dependency
While wide dependencies can be less performant, they are essential for various data processing tasks. Therefore, follow key factors to mitigate their impact:
- Data Partitioning: Strategically partitioning your data based on the operations you intend to perform can reduce shuffling. Pre-partitioning the data on the join key before a join operation can significantly improve efficiency.
- Caching: Caching intermediate results can help if they are reused across multiple transformations. This avoids redundant shuffling for the same data.
When to use: Wide vs Narrow dependencies in Apache Spark?
When to use Narrow Dependency?
- Use narrow dependencies when your transformations can be applied independently to each partition of the RDD without requiring data from other partitions.
- Narrow dependencies are suitable for simple transformations where each partition’s output depends only on the corresponding partition of the parent RDD.
- They are efficient for parallel execution, as Spark can process each partition independently without needing to shuffle or redistribute data across the cluster.
- If the data size is small or evenly distributed across partitions, narrow dependencies are usually more efficient.
When to use of Wide dependency?
- Choose wide dependencies when your transformations require data from multiple partitions of the parent RDD, such as joins, groupings, and aggregations.
- While wide dependencies introduce overhead due to data shuffling, they are necessary for operations that involve combining or reorganizing data across partitions.
- In the case of skewed data distribution or when dealing with large datasets, wide dependencies are useful.
Wide vs Narrow dependencies in Apache Spark
| Aspect |
Narrow Dependencies |
Wide Dependencies |
| Dependency Definition |
Each partition of parent RDD is used by at most one partition of child RDD |
Multiple child partitions depend on the same parent partition or data needs to be shuffled |
| Parallelism |
High parallelism, as operations can be performed independently on each partition |
Lower parallelism due to data shuffling and dependencies between partitions |
| Data Shuffling |
No data shuffling required |
Data shuffling across the network may be required |
| Examples |
map, filter, flatMap |
groupByKey, reduceByKey, join |
| Performance Impact |
Minimal performance impact |
Potential performance bottlenecks due to network I/O and data skew |
| Optimization |
Preferred for optimizing performance and resource utilization |
Should be minimized; optimize by partitioning, caching, and broadcasting |
In general, strive for narrow dependencies whenever possible for optimal performance. However, for specific operations like joins and aggregations, wide dependencies are necessary. By understanding the trade-offs and applying optimization techniques like data partitioning and caching, you can effectively manage wide dependencies and ensure your Spark applications run efficiently.
Conclusion
Understanding narrow and wide dependencies is fundamental for optimizing Spark application performance, especially when working with large datasets.
Narrow dependencies generally lead to faster execution due to minimal shuffling, while wide dependencies can introduce shuffling overhead. By strategically choosing transformations and applying techniques like data partitioning and caching, you can minimize the impact of shuffling and ensure your Spark jobs run efficiently.
Share your thoughts in the comments
Please Login to comment...