Voting Regressor
Last Updated :
25 Oct, 2023
In the family of ensemble learning, an efficient method for regression tasks in Machine learning is the voting regressor. The voting algorithm has two variants: Voting Classifier and Voting Regressor. The voting classifier is explicitly used for only classification tasks, while the voting regressor is used for regression tasks, but both work in similar ways with few logical changes. This ensemble method combines the predictions from multiple individual regression models (traditional or other ensemble methods) to make a final prediction by leveraging the wisdom of the crowd by simple averaging or weighted averaging of the predictions of its constituent models, which leads to more accurate and robust predictions compared to individual models. In this article, we will discuss the voting regressor and see how we can implement it.
What is a voting regressor?
A voting regressor can be defined as a special method that combines or ‘ensembles’ multiple regression models and overperforms the individual models present as its estimators. The mathematical concept of a voting regressor is quite easy and very similar to that of a voting classifier. If we consider a crowd of machine learning models as  then
then  each model will produce a prediction
each model will produce a prediction  for a given input data
for a given input data  . Now if we pass it through Voting Regressor then the final prediction will be
. Now if we pass it through Voting Regressor then the final prediction will be  . Now, we can choose simple average mode which uniformly distributes the total weight to all the models or we can choose custom-specified weights for each model which is called Weighted averaging.
. Now, we can choose simple average mode which uniformly distributes the total weight to all the models or we can choose custom-specified weights for each model which is called Weighted averaging.
For Simple average: 
For Weighted average:  where
where  is the custom weights assigned during training process.
is the custom weights assigned during training process.
But Mathematical expression or concept is not useful for a direct understanding of Voting regressor, so some key facts about it are discussed below:
- Diverse Models: It’s required to include diverse regression(like traditional ML models along with some other ensemble tree-based models) models in the ensemble. These models can have different strengths and weaknesses which can work a complement each other when passed through a Voting regressor.
- Simple Averaging vs. Weighted Averaging: The Voting regressor can use simple averaging in which equal weights are assigned for all models or weighted averaging where different weights are assigned to each model’s prediction. The weighted averaging allows us to emphasize the predictions of certain models which are expected to perform better on specific subsets of the data.
- Training and Prediction: The individual models are trained on the training data and during prediction, each model provides its own prediction which are then combined using the specified aggregation method (averaging) to form the final ensemble prediction. This is the main working principal of Voting Regressor for any kind of datasets or individual models.
- Performance improvement: The Voting Regressor is often used when we have several candidate models and want to improve overall prediction accuracy by smoothing out the noise introduced by each individual models and provide more stable and accurate predictions.
Step-by-step implementation
Importing required libraries
We will import all required Python libraries like NumPy, Pandas, Seaborn, Matplotlib and Sklearn etc.
Python3
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.svm import SVR
from xgboost import XGBRegressor
from sklearn.ensemble import VotingRegressor, RandomForestRegressor
from sklearn.metrics import mean_absolute_error, r2_score
import matplotlib.pyplot as plt
import seaborn as sns
|
Dataset loading and splitting
Now we will loaded the Boston Housing Dataset and split it into training and testing sets. After loading the raw data, we are performing data manipulation and splitting the dataset into training and testing sets using train_test_split.
Python3
raw_df = pd.read_csv(data_url, sep="\s+", skiprows=22, header=None)
data = np.hstack([raw_df.values[::2, :], raw_df.values[1::2, :2]])
target = raw_df.values[1::2, 2]
X_train, X_test, y_train, y_test = train_test_split(data, target, test_size=0.3, random_state=42)
|
Exploratory Data Analysis
Exploratory Data Analysis or EDA helps us to gain deeper insights about the behavior of the dataset.
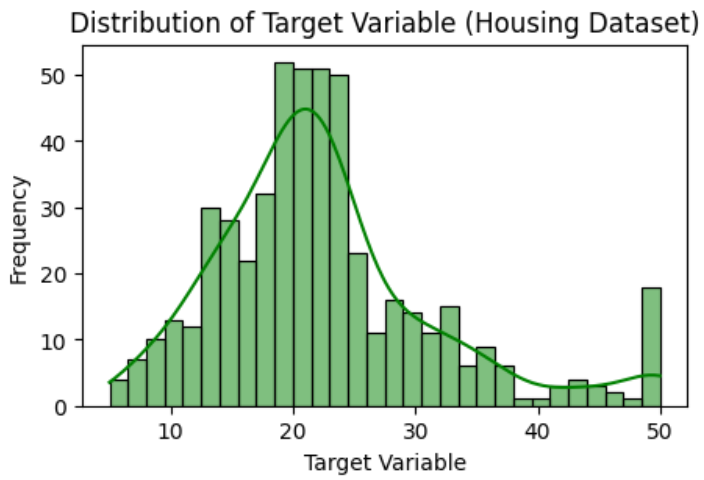
- Distribution of target feature: Visualizing distribution of variable for regression dataset helps us to know the nature of the target or any outlier is present or not.
Python3
plt.figure(figsize=(5, 3))
sns.histplot(target, kde=True, bins=30, color='green')
plt.xlabel('Target Variable')
plt.ylabel('Frequency')
plt.title('Distribution of Target Variable (Housing Dataset)')
plt.show()
|
Output:
Creating individual regression models
As discussed previously, Voting regressor ensembles multiple regression models. So, before implement Voting regressor we need to define individual models which will work as estimators in Voting algorithm. Here we will initialize two traditional machine learning models like Linear Regression, Support Vector Machine(SVM) and two tree based ensemble algorithms like XGBoost and Random Forest.
Python3
linear_reg = LinearRegression()
svr_reg = SVR(kernel='sigmoid')
xgb_reg = XGBRegressor(random_state=42)
rf_reg = RandomForestRegressor(random_state=42)
|
Voting Regressor model training
Now we will train the Voting regressor model. For that we need to specify some parameters–>
- estimators: This is a list of tuples where each tuple is the combination of unique identifier for each estimator( like ‘rf’ for Random Forest) and the corresponding individual regression models(specified model names present in the code) that will be the part of the ensemble.
- n_jobs: This parameter controls the number of CPU cores to use for parallel execution during the training phase of the ensemble which is set to 5 here to enable the usage of total 5 CPU cores for parallel execution during training.
- verbose: When it is set to ‘True’ it prints the training process. We have not specified it so it will take its default value as ‘False’. If you are initializing parallel execution(n_jobs>1) then this parameter will not print anything.
Python3
voting_reg = VotingRegressor(estimators=[('linear', linear_reg), ('svr', svr_reg), ('xgb', xgb_reg), ('rf', rf_reg)],
n_jobs=5)
voting_reg.fit(X_train, y_train)
|
Output:

Model evaluation
After training, we will evaluate our model’s performance in the terms of model performance metrics like MAE and R2-score.
Python3
pred = voting_reg.predict(X_test)
mae = mean_absolute_error(y_test, pred)
r2 = r2_score(y_test, pred)
print(f'Mean Absolute Error (MAE): {mae:.2f}')
print(f'R-squared (R2) Score: {r2:.2f}')
|
Output:
Mean Absolute Error (MAE): 2.61
R-squared (R2) Score: 0.80
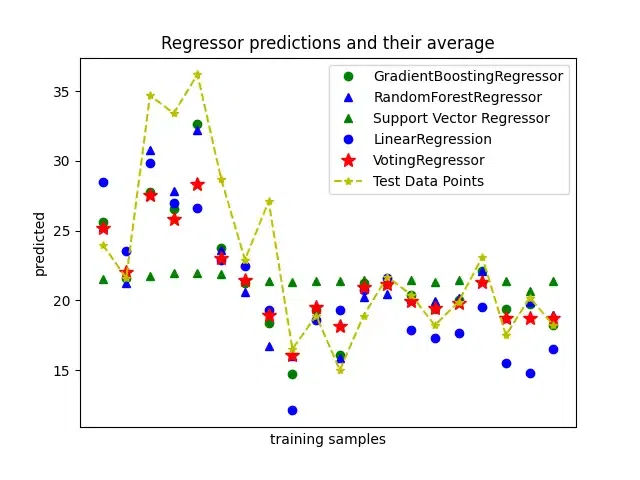
We’ll show the 20 predictions visually. The average prediction given by Voting Regressor is represented by the red stars.
We have coded for training multiple regression models (Linear Regression, Support Vector Regressor, XGBoost Regressor, and Random Forest Regressor) and then visualized their predictions along with a Voting Regressor.
Python3
xt = data[:20]
linear_reg.fit(X_train, y_train)
svr_reg.fit(X_train, y_train)
xgb_reg.fit(X_train, y_train)
rf_reg.fit(X_train, y_train)
voting_reg.fit(X_train, y_train)
pred_linear_reg = linear_reg.predict(xt)
pred_svr_reg = svr_reg.predict(xt)
pred_xgb_reg = xgb_reg.predict(xt)
pred_rf_reg = rf_reg.predict(xt)
pred_voting_reg = voting_reg.predict(xt)
plt.figure()
plt.plot(pred_xgb_reg, "go", label="GradientBoostingRegressor")
plt.plot(pred_rf_reg, "b^", label="RandomForestRegressor")
plt.plot(pred_svr_reg, "g^", label="Support Vector Regressor")
plt.plot(pred_linear_reg, "bo", label="LinearRegression")
plt.plot(pred_voting_reg, "r*", ms=10, label="VotingRegressor")
plt.plot( target[:20],"y*--", label = 'Test Data Points')
plt.tick_params(axis="x", which="both", bottom=False, top=False, labelbottom=False)
plt.ylabel("predicted")
plt.xlabel("training samples")
plt.legend(loc="best")
plt.title("Regressor predictions and their average")
plt.show()
|
Output:
Voting Regressor
Conclusion
We can conclude that Voting regressor can be effective for large datasets and where we need to abolish one model’s weakness to get better results. The estimators of Voting Regressor should be chosen cautiously to make a complementary combination where one model reduces another model’s weakness to get optimized results. Here, we have achieved 80% of R2-Score which is moderately well. For real-time datasets, we can choose more number of base models to achieve good results.
Share your thoughts in the comments
Please Login to comment...