In this article, we will discuss the different types of Services in Kubernetes. Along with these three Services, we will also discuss Headless Service which is a very important Service through which clients can directly communicate with the Pods.
Kubernetes Service
The definition of Kubernetes services refers to a” Service which is a method for exposing a network application that is running as one or more Pods in your cluster.” Service is a static IP address or a permanent IP address that can be attached to the Pod. We need Service because the life cycles of Service and the Pod are not connected, so even if the Pod dies, the Service and its IP address will stay so we don’t have to change that endpoint every time the Pod dies.
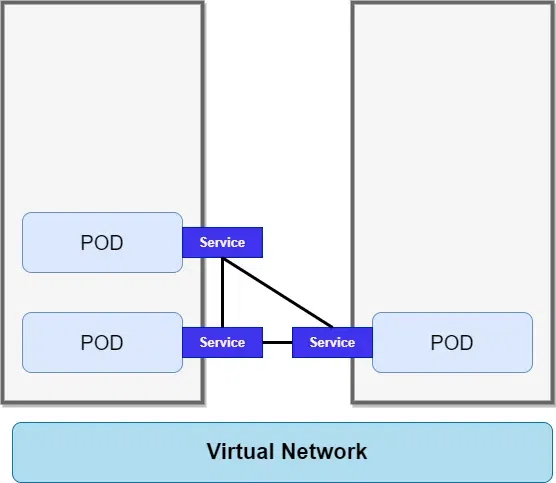
Therefore, what Service does is it provides stable IP address to the Pods. A Kubernetes Service also provides load balancing because when you have pod replicas, For example, three replicas of a microservice application. The Service will basically get request targeted to the application and forward it to one of those pods. Because of this now clients can call a single stable IP Address instead of calling each pod individually, so services are a good abstraction for loose coupling and for communication within the cluster and outside it as well.
Types of Service
When we define a service configuration, we can specify the type of the service, the type attribute can have four different values:
- ClusterIP
- Headless Service
- NodePort
- LoadBalancer
1. ClusterIP Service
ClusterIP is the most common Service as well as it is the Default type of Service, meaning when you create a Service and not specify a type it will automatically take ClusterIP as a type.
Let’s understand this with the help of an example. Imagine we have a microservice application deployed in the Cluster. We have a Pod with microservice container running inside it and beside that microservice container we have a side-car container that collects the logs of the microservice and then sends that to some destination database.
apiVersion: apps/v1
kind: Deployment
metadata:
name: microservice-one
# ...
spec:
replicas: 3
# ...
template:
metadata:
labels:
app: microservice-one
spec:
containers:
- name: ms-one
image: my-repo/ms-one
ports:
- containerPort: 3000
- name: log-collector
image: my-repo/log-c
ports:
- containerPort: 9000
Here, our microservice container (ms-one) is running at Port 3000 and the logging container is running on Port 9000. This means that those two ports will be now open and accessible inside the Pod. The Pod will also get an IP address from a range that is assigned to a node.
Additional Note :- The way it works is that if you have three Worker Nodes in your Kubernetes Cluster, each worker Node will get a range of IP addresses which are internal in the Cluster. For example, the Pod 1 will get IP addresses from a range of 10.2.1 onwards, the second worker Node will get IP range of 10.2.2 onwards and the third worker Node will get a range of 10.2.3 onwards.
The requests coming in from the browser to the microservice will be handled by Ingress, and incoming requests get forwarded from Ingress to the Pod by the help of the ClusterIP Service. A ClusterIP just like other Service in Kubernetes is a component not a process, it is just an abstraction layer that basically represents an IP address. Ingress will send the request to the ClusterIP Service at it’s IP address at it’s Port which you can understand by the diagram.
Here is the Ingress configuration file:
apiVersion: networking.k8s.io/v1beta1
kind: Ingress
metadata:
name: ms-one-ingress
annotations:
kubernetes.io/ingress.class: "nginx"
spec:
rules:
- host: microservice-one.com
http:
paths:
- path: /
backend:
serviceName: microservice-one-service
servicePort: 3200
Here is the Service configuration file:
apiVersion: v1
kind: Service
metadata:
name: microservice-one-service
This is how Service is accessible within the cluster. We define Ingress rules that forward the request based on the request address to certain Services and we define the Service by its name and the DNS resolution then maps that Service name to an IP address that the Service actually got assigned. This is how Ingress knows how to talk to the Service. Once the request comes to the Service at a particular address, then Service will know to forward that request to one of the Pods that are registered as the Service endpoints.
.webp)
Another thing you should know about Service (ClusterIP) is that when you create a Service, Kubernetes creates an Endpoints object that has the same name as the service itself and Kubernetes will use this endpoints object to keep track of which Pods are the Endpoints of the Service.
2. Headless Service
Headless Service is a type of Service that allows the client to directly communicate with the Pods. It is a useful tool for building distributed applications. Headless Services are used in deploying Stateful Application in Kubernetes.
With ClusterIP we saw that each request to the service is forwarded to one of the Pod replicas that are registered as service Endpoints, but Headless Service comes into play if a Client wants to communicate with one of the Pods directly and selectively, or if the Endpoint Pods need to communicate with each other directly without going through the Service. We would not use ClusterIP Service in this case because it will randomly select one of the Pods while we want the communication with specific Pods.
This is how we use Headless Service – Kubernetes allows Slients to discover Pod IP addresses through DNS lookups. Usually the way it works is that when a client performs a DNA lookup for a service, the DNS Server returns a single IP address which belongs to the Service and this will be the Services ClusterIP address which. However if you tell Kubernetes that you don’t need a ClusterIP address of the Service by setting the ClusterIP field to none when creating a Service, then the DNS server will return the pod IP addresses instead of the services IP address. With this the Client can do a simple DNS lookup to get the IP address of the Pods that are members of that service and the client can use that IP address to connect to the specific Pods it wants to talk to.
so the way we define a headless service in a service configuration file is basically setting the ClusterIP to none.
apiVersion: v1
kind: Service
metadata:
name: mongodb-headless-service
spec:
clusterIP: None
selector:
app: mongodb
ports:
- protocols: TCP
port: 27017
targetPort: 27017
If we create Service from this configuration file, Kubernetes will not assign the Service a cluster IP address. And when we deploy Stateful applications in the Cluster like Mongo DB, we have the normal ClusterIP Service that handles the communication to mongodb and other Container inside the Pod and in addition to that service we have a headless Service, so we always have these two services alongside each other so that ClusterIP can do the load balancing and Headless Service can be used by client to communicate with one of those Pods directly to perform the right commands or used by the Pods to talk to each other for data synchronization.
3. NodePort
NodePort is a Service that is accessible on a static Port on each Worker Node in the cluster. The NodePort Service makes the external traffic accessible on static or fixed port on each worker Node which is different from the ClusterIP Service which was only accessible within the Cluster (no external traffic can directly address the ClusterIP Service). With NodePort instead of Ingress, the browser request will come directly to the worker node at the Port that the service specification defines and the Port that NodePort service type exposes is defined in the NodePort attribute. The NodePort value has a predefined range between 30,000 and 32,767.
apiVersion: v1
kind: Service
metadata:
name: ms-service-nodeport
spec:
type: NodePort
selector:
app: microservice-one
ports:
- protocols: TCP
port: 3200
targetPort: 3000
nodePort: 30008
The NodePort Service is accessible for the external traffic like browser request. NodePort Service exposure is not very efficient and not secure because we are opening the Ports to directly talk to the Services on each Worker Node so the external clients basically have access to the worker nodes directly, so if we gave all the services this NodePort Service type then we would have a bunch of Ports open on the worker nodes Clients from outside can directly talk to.
4. Load Balancer
Load Balancer Service type allows the Service to become accessible externally through a Cloud Provider’s Load Balancer functionality. LoadBalancer Service is an extension of NodePort Service. To understand LoadBalancer Service type, you must know about Load Balancing. Load Balancing is the process of dividing a set of tasks over a set of resources in order to make the process fast and efficient. All the Cloud Providers like Google Cloud Platform, AWS, Azure, etc. have their own native Load Balancer implementation and that is created and used whenever we create a LoadBalancer Service type.
Whenever we create a LoadBalancer Service, NodePort and ClusterIP Services are created automatically by Kubernetes to which the external Load Balancer of the cloud platform will route the traffic to. Here is an example of how to define load balancer service configuration:
apiVersion: v1
kind: Service
metadata:
name: ms-service-loadbalancer
spec:
type: LoadBalancer
selector:
app: microservice-one
ports:
- protocols: TCP
port: 3200
targetPort: 3000
nodePort: 30010
Here the nodePort which is the port that opens on the Worker Node is not directly accessible externally but only through the Load Balancer. So the entry point becomes a Load Balancer first and it can then direct the traffic to nodePort on the Worker Node and the ClusterIP. Hence we can say that the LoadBalancer Service type is an extension of the NodePort type which itself is an extension of the ClusterIP Service type.
Conclusion
In this article we have discussed the most important types of Service in Kubernetes. Service is basically a static IP address or a permanent IP address that can be attached to the Pod. The reason why we need Service is that the life cycles of Service and the Pod are not connected so even if the Pod dies, the Service and its IP address will stay so we don’t have to change that endpoints every time the Pod dies. In this article we discussed for types of Services – ClusterIP, NortPort, LoadBalancer and Headless Service.
We hope that this article helped you improve your understanding about Services in Kubernetes. Make sure to go through the entire article for in-depth understanding Services.
Frequently Asked Question(FAQs) On Types of Service in Kubernetes
1. What are the possible values in service type attribute?
There are three possible values in service type attribute.
- ClusterIP
- NodePort
- LoadBalancer
2. Can a pod have 2 Services?
Yes, a Pod can have 2 Services in Kubernetes.
3. Can I access Pod without Service?
Yes, you can access Pod without Service using its IP Address.
4. What are Kubernetes Services?
In Kubernetes, A Service is a method for exposing a network application that is running as one or more Pods in your cluster. Service is basically a static IP address or a permanent IP address that can be attached to the Pod.
5. What are the types of Services in Kubernetes?
The types of Services in Kubernetes are :
- ClusterIP
- NodePort
- LoadBalancer
- Headless Service
6. What is a Headless Service?
Headless Service is a type of Service that allows the client to directly communicate with the Pods. It is a useful tool for building distributed applications. Headless Services are used in deploying Stateful Application in Kubernetes.
Share your thoughts in the comments
Please Login to comment...