Cryptocurrency is such a hype that everyone wants to be a part of it. Even nerds and programmers want to dive into this amazing field because it is quite versatile and interesting in every aspect. So how about scraping the price of cryptocurrency coins such as bitcoin, ethereum, dogecoin, and a ton of other coins using shell script and coingecko.com.
There are tons of websites that show the pieces of various Cryptocurrencies but many of them have bots and security systems to avoid recursively accessing a website. So the safest option here is to use coingecko which is a great and massive platform for analyzing cryptocurrency and other aspects as well.
Inspecting the site
This is the most crucial part of web scraping to inspect and analyze various aspects of the website. This allows us to get familiar with the structure and components of the website. If you are using chrome, developers have a great option of Dev tools, such as inspecting the webpage and see the tags and elements associated with it.

Finding the target element or tag
Now move on to the actual site’s content and find our target, which in this case is the current price of the cryptocurrency. We can use the “Select the element from the page to inspect” option on the top left side of the inspect/ developer window. This allows us to see the elements/tags by clicking or hovering over them. This will make sure we are selecting the correct tag from the source of the webpage. Also, it becomes quite easy to find our target element as we can visually see the element.


We find that the price is stored in the span tag with the class ‘no-wrap’ and has a fluctuating value of data-price-btc, which will be the tag that we will try to extract from this website. The other stuff in the span tag is fluctuating every second as it is the value of the coin stored in the properties. So we’ll only need the span tag until now, we’ll see how to extract this using grep and sed in the upcoming sections.
Using cURL to access the website and store it in a file
Now we move on to the actual scrapping and accessing the website page from the terminal. cURL command is a great option for this as it is available by default in many Linux/Unix systems. We also have an alternative cURL called wget, but is not widely available in many systems. We can access a website URL using the following command.
curl 'https://www.coingecko.com/en/'
You will have an output that shows the entire web page’s source. The output is massive, so we need to trim and strip many tags and components to extract the data from them, but for that, we need to store the webpage source somewhere. We’ll store it in a file. We can pass in arguments to the curl command to save the output in the file provided.
curl -o price.txt 'https://www.coingecko.com/en/'
The -o argument allows us to store the output in a file. In this case, we store it in the text file named ‘price.txt’. But it is the home page of the website as you can see, we need the page of the particular coin. We need to modify the URL and probably store it in a variable as the URL will be dynamically generated based on the user input of the coin. If you see the various coins and notice the URL, there is a pattern that generated the URL ‘ https://www.coingecko.com/en/coins/bitcoin’ and ‘https://www.coingecko.com/en/coins/ethereum’ have just the word/code of their name as a difference. So how can we achieve that? We can use variables inside of the URL like:
coin='bitcoin'
url='https://www.coingecko.com/en/coins/'$coin''
output=price.txt
curl -o $output $url
We can definitely input from the user and store it in the coin variable, but here we can keep it hardcoded just for testing out the command. We have also made a variable for the output file as well. We’ll need the file for pattern finding and filtering out the unwanted tags later. We are using the nested quotations inside of the quotation to make the bash understand the coin as a variable and $ symbol to access the variable’s content.
Scraping the webpage file using grep and sed
We now have the source of the webpage from which we need the price of the cryptocurrency coins. We will start by using grep to tick out the span tag with the class no wrap and data-price-BTC, which’s value changes every time, so we will check it here. We won’t be able to scrap the content if we hard code the value, it may change every second, so just keep it till there.
We will use grep with -o and -P arguments, which will allow us to return only matching cases and for Perl Regular Expression respectively. We will get everything in between the span class including the fluctuating properties. We just want the value of the coin which is embedded in the span tag, we can simply remove the span tags using the regex in Perl.
grep -oP ‘(?<=<span class=”no-wrap” data-price-btc).*?(?=</span>)’ $output >temp.txt
The following code will extract the span tag from the entire source and remove everything except the lines where the match is found. The command also removes the end span tag as well, so we are only left with the beginning tag with some properties and text attributes. The output is stored in the temp file. We will get some lines of text and properties of those tags as well. Because the properties and values are fluctuating prices, we get the text as follows:

We will remove those text and properties and get only the value in the text we have got using the sed command as follows:
sed -i 's/[^>]*>//g' temp.txt >$output
The sed command is an editor that will edit the text in the file as we need to remove the text before the > tag and simply get in the value after the closing tag. We store the output again in the price.txt file which we have made as a variable. The sed command with the provided regex will remove everything before the closing tag(>) and hence get the value between those tags but the ending tag(</> was already removed by grep. The -i argument will make sure we do not print the results after performing the operation.
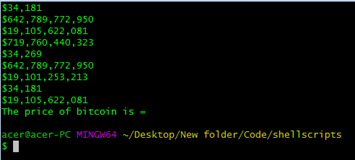
So we will only get the value which we wanted, but there are still 6-7 values that show volume and all-time-high and all-time-low prices of that coin. We don’t require that. We will remove them by again using sed but this time it will be quite simple, as the following:
sed -ni '1p' temp.txt >$output
The sed takes another parameter as -n which will suppress the output and p will print the specified line. We are not printing anything as we are storing the result in the price.txt file and hence we will achieve the result by printing only the first line which has the current line.

We will need to store the result in the price.txt file and remove the temp.txt file. For that, we will move the contents of the temp.txt file to the price.txt file and simply delete the temp file.
cp temp.txt $output
rm temp.txt
Printing the price
We are almost done. We only need to print the price, as we have stored the price in the file, we need to store it in the variable to print it according to our needs. We will use a while loop until the file reaches the end of the file and extract the only line into a variable. Finally, we use the echo command to print the price.
while read price
do
val=$price
done <$output
echo "The price of $coin is = $val"
For a layer of readable code, we’ll create functions for each task, i.e. for striping or scraping the webpage and for printing the price.
function strip_html(){
grep -oP '(?<=<span class="no-wrap" data-price-btc).*?(?=</span>)' $output >temp.txt
sed -i 's/[^>]*>//g' temp.txt >$output
sed -ni '1p' temp.txt >$output
cp temp.txt $output
rm temp.txt
}
function print(){
while read price
do
val=$price
done <$output
echo "The price of $coin is = $val"
}
Below is the complete implementation.
Making several modifications, such as clearing the output of cURL to /dev/null, will flush the output and make it loop a bit cleaner. If it shows any error, please remove those commands. We also took the user input and stored the value in the coin variable.
#!/bin/bash
function strip_html(){
grep -oP '(?<=<span class="no-wrap" data-price-btc).*?(?=</span>)' $output >temp.txt
sed -i 's/[^>]*>//g' temp.txt >$output
sed -ni '1p' temp.txt >$output
cp temp.txt $output
rm temp.txt
}
function print(){
while read price
do
val=$price
done <$output
echo "The price of $coin is = $val"
}
read -p "enter the coin code : " coin
url='https://www.coingecko.com/en/coins/'$coin''
output=price.txt
touch $output temp.txt
curl -o $output $url
strip_html
print

Share your thoughts in the comments
Please Login to comment...