Sequential File Organization in DBMS
Last Updated :
11 Mar, 2024
Database Management System (DBMS) is a software system that manages the creation, storage, retrieval, and manipulation of data in a structured and organized way. It allows users to perform CRUD operations (Create, Read, Update, Delete) and organize data efficiently.
What is File Organization?
File Organization refers to the way data is stored in the form of blocks, or files, to facilitate easy access and maintain order. It shows the logical relationship among various records. The efficiency of any file organization mainly depends on the insertion, deletion, and updating of the records. Memory is partitioned into memory data blocks and each of them is assigned a specific address.
What is Sequential File Organization?
Sequential file organization is a method where records are stored in a specific order. For instance, imagine the names of students listed alphabetically in a proper sequence. At the end of the file, new records can be added and there is no fixed length in it as you can update it. Efficient for small datasets as the linear structure allows for quick processing and the entire set can be traversed easily.
Types of Sequential File Organization
Sequential file organization is further classified as:
- Pile File Method
- Sorted File Method

Types of Sequential File Organization
Pile File Method
One method of sequential file organization is the pile file, where records are stored in the order they arrive, similar to how customers’ orders are taken as per their arrival.
The pile file method operates on a “first-come, first-served” basis, where the record comes first would be stored first in sequence.
How Insertion Works in Pile File Method?

Inserting a new record
- Whenever a new record is added then it will automatically append itself to the end of the existing file in a sequential manner.
- In this, the files are not stored in a sorted manner.
- Suppose in this the record R5 will be added to the end of the file, i.e., after record R10.
Sorted File Method
Another method of sequential file organization is sorted file, where files are stored in sorted format either ascending or descending. In a sorted file, records are arranged based on a primary key or attribute, which dictates their sequential order. Adding new records in a sorted file according to the sorting criteria does not affect the overall sequence. It takes less time to search for the previous record.
Imagine a database file as a classroom register, where student records are arranged in ascending order by their unique roll numbers. This “sorted file” method allows for efficient retrieval of specific records, similar to quickly finding a student’s information based on their roll number.
How Insertion Works in Sorted File Method?
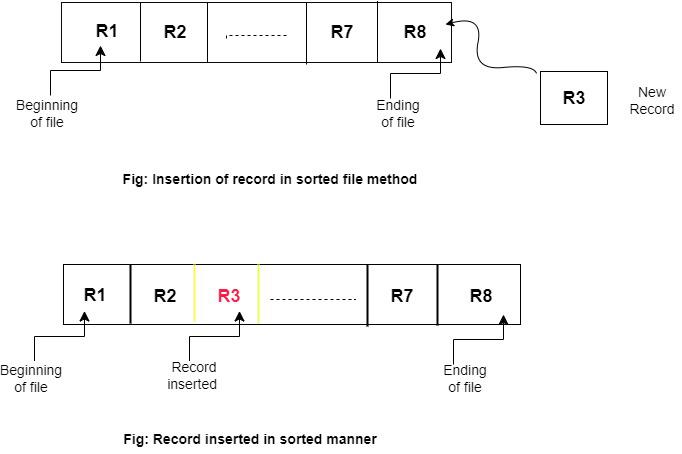
Inserting a new record in a sorted file
- In a sorted file, when a new record arrives, it’s not simply added to the end and then moved later. Instead, it’s inserted directly into its correct position based on a specific key or attribute. This ensures the final sequence remains sorted, enabling fast and efficient searching.
- Let R1, R2, R7, and R8 be four previous records stored in the file based on primary key references, and a new record R3 comes and then it will move forward to its correct position, i.e., after R2.
- A primary key is the unique key or attribute that determines the order of the records within the file. No two records can have the same primary key.
Advantages of Sequential File Organization
- Design: Compared to other file organization methods, sequential file organization boasts a simple design and minimal complexity, making it easy to develop and implement.
- Small Datasets: Sequential processing, can be efficient for small amounts of data. But for large datasets, other methods might be more efficient such as hash file and heap file.
- Accuracy: Sequential file organization is inherently accurate as it maintains a simple order, and there’s no manipulation involved that could introduce errors.
- Processing: For generating reports or calculations that require processing every record, sequential file organization is straightforward and accurate.
Disadvantages of Sequential File Organization
- Time-Consuming: Random record access within a pile file presents a time-consuming challenge. Unlike indexed methods, each record must be sequentially traversed from left to right.
- Memory Wastage: When a record is deleted the space it occupied usually remains unused. This can lead to memory waste, especially for large datasets with frequent deletions, and act as an inefficient memory method.
- System Processing: While using sorted files the record must always be sorted and adding or changing records often requires re-sorting the entire set, which can slow down your system, especially for larger files.
Therefore, sequential file organization is the easiest way to organize files and a straightforward approach to data storage and processing where records are stored in sequential order. This makes it ideal for traversing over small datasets. Also, the drawback is that there is time wastage in traversing the whole file to find a single record.
Frequently Asked Questions on Sequential File Organization – FAQs
When should sequential file organization be used?
When working with large datasets such as transaction history, and the goal is to examine entire records, sequential file organization offers an efficient approach. Due to its simple design and low complexity, it requires less effort to store data and information, making it ideal when storage cost is major concern.
What is the full form of ISAM?
The full form of ISAM is Indexed Sequential Access Method. It is an efficient file organization method that stores data sequentially while also maintaining secondary indexes. These indexes enable both sequential and random access, making it more versatile and better than sequential file organization.
Alternatives to sequential file organization for random access of records?
Heap file Organization- In this method, records are not placed in any specific order. New records are simply added to the end of the available space within a block. We can think of it as a stack of ungraded student assignmnets where as per their completion they put assignment copies on the teacher’s desk.
This approach requires traversing over the entire stack to find specific records, it is well-suited where frequent additions are essential, and order of data is not critical. In such situations, records are stored in arbitrary order meaning they have no predetermined arrangement.
Indexed sequential access method- Data is stored sequentially in a file, but secondary indexes are also present there. These indexes act as a pointer to the actual location of each record within the file, which enables both sequential and random access. But it comes with increased complexity compared to sequential.
This can be understood by thinking of classroom register where students’ names are listed sequentially, but they also have unique roll numbers. These roll numbers act as indexes, allowing teachers to quickly locate a specific student.
Share your thoughts in the comments
Please Login to comment...