Select Columns that Satisfy a Condition in PySpark
Last Updated :
29 Jun, 2021
In this article, we are going to select columns in the dataframe based on the condition using the where() function in Pyspark.
Let’s create a sample dataframe with employee data.
Python3
import pyspark
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
data = [[1, "sravan", "company 1"], [2, "ojaswi", "company 1"],
[3, "rohith", "company 2"], [4, "sridevi", "company 1"],
[1, "sravan", "company 1"], [4, "sridevi", "company 1"]]
columns = ['ID', 'NAME', 'Company']
dataframe = spark.createDataFrame(data, columns)
dataframe.show()
|
Output:

The where() method
This method is used to return the dataframe based on the given condition. It can take a condition and returns the dataframe
Syntax:
where(dataframe.column condition)
- Here dataframe is the input dataframe
- The column is the column name where we have to raise a condition
The select() method
After applying the where clause, we will select the data from the dataframe
Syntax:
dataframe.select('column_name').where(dataframe.column condition)
- Here dataframe is the input dataframe
- The column is the column name where we have to raise a condition
Example 1: Python program to return ID based on condition
Python3
import pyspark
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
data = [[1, "sravan", "company 1"], [2, "ojaswi", "company 1"],
[3, "rohith", "company 2"], [4, "sridevi", "company 1"],
[1, "sravan", "company 1"], [4, "sridevi", "company 1"]]
columns = ['ID', 'NAME', 'Company']
dataframe = spark.createDataFrame(data, columns)
dataframe.select('ID').where(dataframe.ID < 3).show()
|
Output:
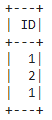
Example 2: Python program to select ID and name where ID =4.
Python3
import pyspark
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
data = [[1, "sravan", "company 1"], [2, "ojaswi", "company 1"],
[3, "rohith", "company 2"], [4, "sridevi", "company 1"],
[1, "sravan", "company 1"], [4, "sridevi", "company 1"]]
columns = ['ID', 'NAME', 'Company']
dataframe = spark.createDataFrame(data, columns)
dataframe.select(['ID', 'NAME']).where(dataframe.ID == 4).show()
|
Output:

Example 3: Python program to select all column based on condition
Python3
import pyspark
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
data = [[1, "sravan", "company 1"], [2, "ojaswi", "company 1"],
[3, "rohith", "company 2"], [4, "sridevi", "company 1"],
[1, "sravan", "company 1"], [4, "sridevi", "company 1"]]
columns = ['ID', 'NAME', 'Company']
dataframe = spark.createDataFrame(data, columns)
dataframe.select(['ID', 'NAME', 'Company']).where(
dataframe.NAME == 'sridevi').show()
|
Output:

Share your thoughts in the comments
Please Login to comment...