Scrapy – Feed exports
Last Updated :
30 Jan, 2023
Scrapy is a fast high-level web crawling and scraping framework written in Python used to crawl websites and extract structured data from their pages. It can be used for many purposes, from data mining to monitoring and automated testing.
This article is divided into 2 sections:
- Creating a Simple web crawler to scrape the details from a Web Scraping Sandbox website (http://books.toscrape.com/)
- Exploring how Scrapy Feed exports can be used to store the scraped data to export files in various formats.
Creating a Simple web crawler
We are going to create a web crawler to scrape all the book details(URL, Title, Price) from a Web Scraping Sandbox website
1. Installation of packages – run the following command from the terminal
pip install scrapy
2. Create a Scrapy project – run the following command from the terminal
scrapy startproject booklist
cd booklist
scrapy genspider book http://books.toscrape.com/
Here,
- Project Name: “booklist”
- Spider Name: “book”
- Domain to be Scraped: “http://books.toscrape.com/”
Directory Structure:
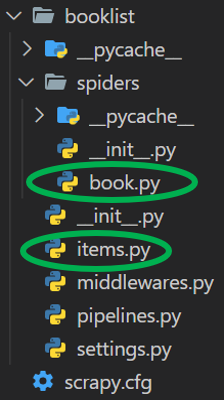
Directory Structure
3. Create an Item – replace the contents of “booklist\items.py” file with the below code
We define each Item scraped from the website as an object with the following 3 fields:
Python
from scrapy.item import Item, Field
class BooklistItem(Item):
url = Field()
title = Field()
price = Field()
|
4. Define the Parse function – Add the following code to “booklist\spiders\book.py”
The response from the crawler is parsed to extract the book details (i.e. URL, Title, Price) as shown in the below code
Python
import scrapy
from booklist.items import BooklistItem
class BookSpider(scrapy.Spider):
name = 'book'
allowed_domains = ['books.toscrape.com']
def parse(self, response):
for article in response.css('article.product_pod'):
book_item = BooklistItem(
url=article.css("h3 > a::attr(href)").get(),
title=article.css("h3 > a::attr(title)").extract_first(),
price=article.css(".price_color::text").extract_first(),
)
yield book_item
|
5. Run the spider using following command:
scrapy crawl book
Output:
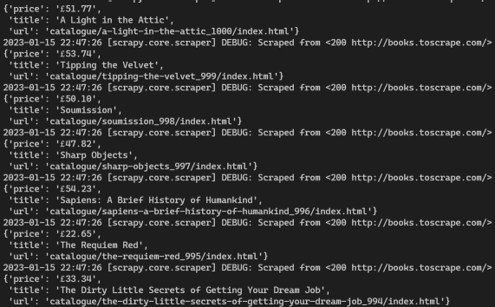
Output Items
Scrapy Feed Exports
One of the most frequently required features when implementing scrapers is being able to store the scraped data as an “export file”.
Scrapy provides this functionality out of the box with the Feed Exports, which allows to generate feeds with the scraped items, using multiple serialization formats and storage backends.
The different file formats supported are:
1. Saving Files via the Command Line
The simplest way to export the file of the data scraped, is to define a output path when starting the spider in the command line.
Add the flag -o to the scrapy crawl command along with the file path you want to save the file to
- CSV – “data/book_data.csv”
- JSON – “data/book_data.json”
- JSON Lines – “data/book_data.jsonl”
- XML – “data/book_data.xml”
scrapy crawl book -o data/book_data.csv
scrapy crawl book -o data/book_data.json
scrapy crawl book -o data/book_data.jsonl
scrapy crawl book -o data/book_data.xml
There are 2 options to using this command:
|
Flag
|
Description
|
|
-o
|
Appends new data to an existing file. |
|
-O
|
Overwrites any existing file with the current data. |
2. Saving Files using Feed Exports
For serializing the scraped data, the Feed Exports internally use the Item Exporters.
Saving the Data via FEEDS setting:
The scraped data can stored by defining the FEEDS setting in the “booklist\settings.py” by passing it a dictionary with the path/name of the file and the file format
Python
FEEDS = {
'data/book_data.csv': {'format': 'csv', 'overwrite': True}
}
|
Python
FEEDS = {
'data/book_data.json': {'format': 'json', 'overwrite': True}
}
|
Python
FEEDS = {
'data/book_data.jsonl': {'format': 'jsonlines', 'overwrite': True}
}
|
Python
FEEDS = {
'data/book_data.xml': {'format': 'xml', 'overwrite': True}
}
|
Saving the Data via custom_settings:
The scraped data can also be stored by configuring the FEEDS setting in each individual spider by setting a custom_setting in the spider (“booklist\spiders\book.py”) for various file formats required.
Python
import scrapy
from booklist.items import BooklistItem
class BookSpider(scrapy.Spider):
name = 'book'
allowed_domains = ['books.toscrape.com']
custom_settings = {
'FEEDS': {'data.csv': {'format': 'csv', 'overwrite': True}}
}
def parse(self, response):
for article in response.css('article.product_pod'):
book_item = BooklistItem(
url=article.css("h3 > a::attr(href)").get(),
title=article.css("h3 > a::attr(title)").extract_first(),
price=article.css(".price_color::text").extract_first(),
)
yield book_item
|
Python
import scrapy
from booklist.items import BooklistItem
class BookSpider(scrapy.Spider):
name = 'book'
allowed_domains = ['books.toscrape.com']
custom_settings = {
'FEEDS': {'data.json': {'format': 'json', 'overwrite': True}}
}
def parse(self, response):
for article in response.css('article.product_pod'):
book_item = BooklistItem(
url=article.css("h3 > a::attr(href)").get(),
title=article.css("h3 > a::attr(title)").extract_first(),
price=article.css(".price_color::text").extract_first(),
)
yield book_item
|
Python
import scrapy
from booklist.items import BooklistItem
class BookSpider(scrapy.Spider):
name = 'book'
allowed_domains = ['books.toscrape.com']
custom_settings = {
'FEEDS': {'data.jsonl': {'format': 'jsonlines', 'overwrite': True}}
}
def parse(self, response):
for article in response.css('article.product_pod'):
book_item = BooklistItem(
url=article.css("h3 > a::attr(href)").get(),
title=article.css("h3 > a::attr(title)").extract_first(),
price=article.css(".price_color::text").extract_first(),
)
yield book_item
|
Python
import scrapy
from booklist.items import BooklistItem
class BookSpider(scrapy.Spider):
name = 'book'
allowed_domains = ['books.toscrape.com']
custom_settings = {
'FEEDS': {'data.xml': {'format': 'xml', 'overwrite': True}}
}
def parse(self, response):
for article in response.css('article.product_pod'):
book_item = BooklistItem(
url=article.css("h3 > a::attr(href)").get(),
title=article.css("h3 > a::attr(title)").extract_first(),
price=article.css(".price_color::text").extract_first(),
)
yield book_item
|
Setting Dynamic File Paths/Names:
The generated data files can be stored using dynamic Path/Name as follows:
Below code creates a JSON file in the data folder, followed by the subfolder with the spiders name, and a file name that includes the spider name and date it was scraped.
Python
FEEDS = {
'data/%(name)s/%(name)s_%(time)s.json': {
'format': 'json', 'overwrite': True
}
}
|
The generated path would look something like this.
"data/book/book_2023-01-15T16-53-02.json"
Saved Files Output:
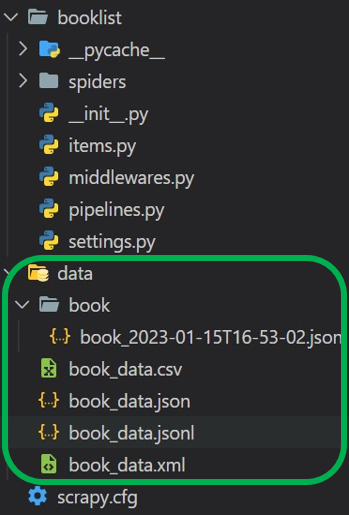
Saved Files Output
Share your thoughts in the comments
Please Login to comment...