PostgreSQL – DELETE USING
Last Updated :
28 Aug, 2020
PostgreSQL has various techniques to delete duplicate rows. One of them is using the DELETE USING statement.
Syntax: DELETE FROM table_name row1 USING table_name row2 WHERE condition;
For the purpose of demonstration let’s set up a sample table(say, basket) that stores fruits as follows:
CREATE TABLE basket(
id SERIAL PRIMARY KEY,
fruit VARCHAR(50) NOT NULL
);
Now let’s add some data to the newly created basket table.
INSERT INTO basket(fruit) values('apple');
INSERT INTO basket(fruit) values('apple');
INSERT INTO basket(fruit) values('orange');
INSERT INTO basket(fruit) values('orange');
INSERT INTO basket(fruit) values('orange');
INSERT INTO basket(fruit) values('banana');
Now let’s verify the basket table using the below statement:
SELECT * FROM basket;
This should result into below:
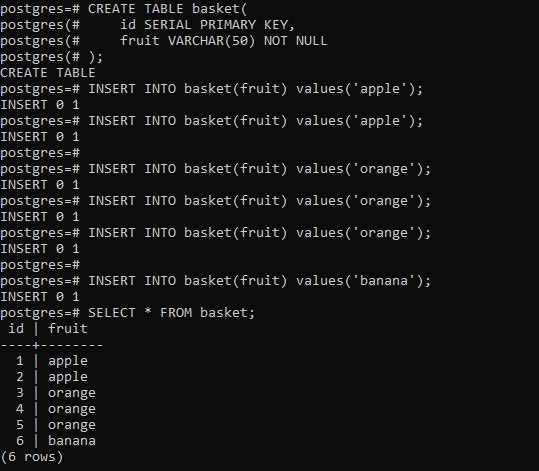
Now that we have set up the sample table, we will query for the duplicates using the following:
SELECT
fruit,
COUNT( fruit )
FROM
basket
GROUP BY
fruit
HAVING
COUNT( fruit )> 1
ORDER BY
fruit;
This should lead to the following results:
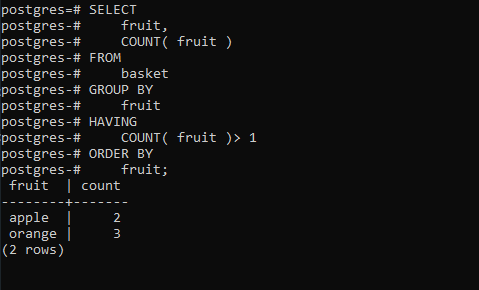
Now that we know the duplicate rows we can use the DELETE USING statement to remove duplicate rows as follows:
DELETE FROM
basket a
USING basket b
WHERE
a.id < b.id
AND a.fruit = b.fruit;
This should remove all duplicate from the table basket, and to verify so use the below query:
SELECT
fruit,
COUNT( fruit )
FROM
basket
GROUP BY
fruit
HAVING
COUNT( fruit )> 1
ORDER BY
fruit;
This should result in the following:
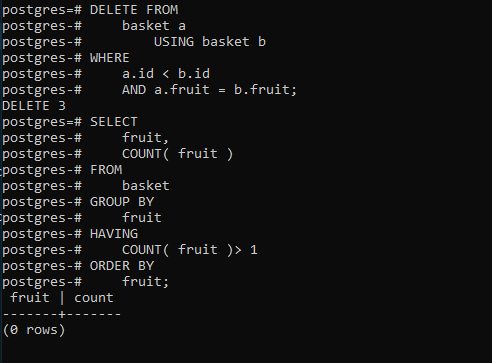
Share your thoughts in the comments
Please Login to comment...