How to Implement Stratified Sampling with Scikit-Learn
Last Updated :
26 Dec, 2023
In this article, we will learn about How to Implement Stratified Sampling with Scikit-Learn.
What is Stratified sampling?
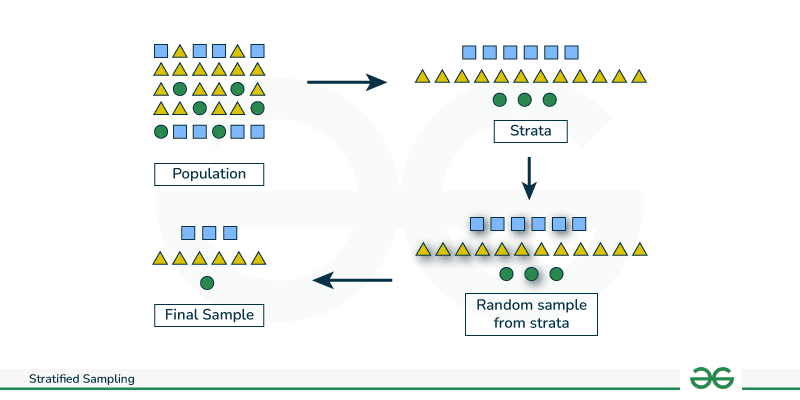
Stratified sampling is a sampling technique in which the population is subdivided into groups based on specific characteristics relevant to the problem before sampling. The samples are drawn from this group with ample sizes proportional to the size of the subgroup in the population and combined to form the final sample. The purpose is to ensure that all subgroup is represented proportionally in the final sample.
Stratified sampling is particularly useful when there are known variations within the population that could significantly impact the model results.
How to perform stratified sampling?
To perform stratified sampling, you need to follow the steps discussed below:
- Define Strata: Identify and define the state of subgroups with the population based on the characteristic(s) of interest such as race, gender, income, level of education, age group, etc.
- Sample Size: Determine overall sample size and individual subgroup sample size ensuring that the ratio of each subgroup chosen is proportionally representative of the overall population.
- Select samples: Randomly select samples from each identified stratum by applying random sampling techniques, such as simple random sampling or systematic random sampling.
- Final Sample: Combine all samples from the various strata into a unified representative sample.
When to use stratified sampling?
- Population Heterogeneity: When the population can be divided into mutually exclusive subgroups based on a specific characteristic.
- Equal Representation: When we want to ensure a specific characteristics or group of characteristics is adequately represented in the final sample.
- Resource Constraints: When you want to generalize the study results to the entire population and ensure that the estimates are valid for each stratum, but the resources are limited.
Examples include Market research where the stratification is generally down by income levels or age groups, and Election exit poll where stratification is generally done by demographics.
Advantages of stratified sampling
- Precision: By ensuring representation from all relevant subgroups, stratified sampling often provides more precise and reliable estimates for the entire population.
- Generalization: Results from the sample can be more confidently generalized to the entire population because each subgroup is accounted for in the sampling process.
- Reduced Variability: Stratified sampling can reduce the overall variability in the sample, leading to more accurate and meaningful statistical analyses.
Comparison started with other Sampling Techniques
Stratified sampling is just one of several sampling techniques used in research. Let’s compare stratified sampling with a few other common sampling techniques:
Stratified Sampling:
- Ensures representation from all subgroups. Useful when there is significant variability within the population.
- Requires knowledge about the population characteristics for effective stratification.
Simple Random Sampling:
- Simple Random Sampling is easy to implement, especially when the population is homogeneous.
- May not capture variability within the population, and certain subgroups may be underrepresented.
Cluster Sampling
- In cluster sampling, population is naturally grouped into clusters, which may not necessarily be based on characteristics of interest.
- The entire cluster becomes the sampling unit.
- Clusters are randomly selected, and all individuals within the selected clusters are included in the sample.
- Suitable for geographically dispersed populations, reduces costs and time.
Quota Sampling
- Quota sampling involves dividing the population into subgroups or quotas based on certain characteristics.
- The main difference is that in stratified sampling we draw a random sample from each subgroup (probability sampling). In quota sampling, we set predetermined quotas for specific characteristics based on our knowledge. Also, the samples selected are non-random meaning the researcher can use convenience or judgmental sampling to meet the predetermined quotas.
Systematic sampling
- Systematic sampling is a method of sampling where every nth member of a population is selected for inclusion in the sample after the first member is randomly chosen. This is done by selecting a random starting point and then picking every kth element from the population. The value of “k” is determined by dividing the total size of the population by the desired sample size.
Implementing Stratified Sampling
Let us load the iris dataset to implement stratified sampling.
- iris = datasets.load_iris(): Loads the famous Iris dataset from scikit-learn. This dataset contains measurements of sepal length, sepal width, petal length, and petal width for 150 iris flowers, representing three different species.
- The value_counts() method provides a quick overview of the distribution of these classes in the dataset.
Python3
import pandas as pd
from sklearn import datasets
iris = datasets.load_iris()
iris_df=pd.DataFrame(iris.data)
iris_df['class']=iris.target
iris_df.columns=['sepal_len', 'sepal_wid', 'petal_len', 'petal_wid', 'class']
iris_df['class'].value_counts()
|
Let us use the scikit-learn’s train_test_split function from scikit-learn’s model_selection module to split a dataset into training and testing sets.
- X and y: The data to be split into a training set and a test set.
- train_size: Represents the proportion of the dataset to include in the training split. In this case, train_size=0.8 means 80% of the data will be used for training, and the remaining 20% will be used for testing.
- random_state: If an integer value is provided, it ensures reproducibility by fixing the random seed. This means that the random split will be the same every time you run the code with the same random state stratify. If set to None, a different random split will be used each time.
- shuffle: If set to True (which is the default), the data is shuffled before splitting. If set to False, the data is split in a stratified fashion without shuffling.
- stratify: This is the column on which we want to stratify. Here we have set to the target variable (y). When stratify=y, it ensures that the class distribution in the training and test sets is similar to the original dataset.
Let us see class distribution when stratify is set to None.
Python3
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test= train_test_split(X,y, train_size=0.8,
random_state=None,
shuffle=True, stratify=None)
print("Class distribution of train set")
print(y_train.value_counts())
print()
print("Class distribution of test set")
print(y_test.value_counts())
|
Output:
Class distribution of train set
0 43
2 40
1 37
Name: class, dtype: int64
Class distribution of test set
1 13
2 10
0 7
Name: class, dtype: int64
Let us see class distribution when stratify is set to True.
Python3
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test= train_test_split(X,y, train_size=0.8,
random_state=None,
shuffle=True, stratify=y)
print(y_train.value_counts())
print(y_test.value_counts())
|
Output:
Class distribution of train set
0 40
2 40
1 40
Name: class, dtype: int64
Class distribution of test set
2 10
1 10
0 10
Name: class, dtype: int64
If we want to use stratified sampling with k fold, we can use StratifiedShuffleSplit class from Scikit Learn as below.
- StratifiedShuffleSplit is a class in scikit-learn that provides a method for generating train/test indices for cross-validation. It is specifically designed for scenarios where you want to ensure that the class distribution in the dataset is maintained when splitting the data into training and testing sets.
- n_splits: The number of re-shuffling and splitting iterations. In the example, n_splits=2 means the dataset will be split into 2 different train/test sets.
- test_size : The proportion of the dataset to include in the test split. It can be a float (for example, 0.2 for 20%) or an integer (for example, 2 for 2 samples).
- random_state: Seed for the random number generator to ensure reproducibility. If set to an integer, the same random splits will be generated each time.
Python3
import numpy as np
from sklearn.model_selection import StratifiedShuffleSplit
skf = StratifiedShuffleSplit(n_splits=2, train_size = .8)
X = iris_df.iloc[:,:-1]
y = iris_df.iloc[:,-1]
for i, (train_index, test_index) in enumerate(skf.split(X, y)):
print(f"Fold {i}:")
print(f" {iris_df.iloc[train_index]['class'].value_counts()}")
print("-"*10)
print(f" {iris_df.iloc[test_index]['class'].value_counts()}")
print("*" * 60)
|
Output:
Fold 0:
2 40
1 40
0 40
Name: class, dtype: int64
----------
2 10
1 10
0 10
Name: class, dtype: int64
************************************************************
Fold 1:
2 40
1 40
0 40
Name: class, dtype: int64
----------
2 10
0 10
1 10
Name: class, dtype: int64
************************************************************
Conclusion
In this article, we saw how we can use stratified sampling to ensure that the final sample represents the population by ensuring that the characteristic of interest is neither underrepresented nor overrepresented.
Frequently Asked Questions (FAQs)
1. How is the sample size determined in stratified sampling?
The formula for calculating the sample size in each stratum is:
(Size of stratum in population/Total Population size) *Overall sample size
2. How does stratified sampling help in addressing bias?
Stratified sampling helps address bias by ensuring that each stratum, representing a subgroup with specific characteristics, is adequately represented in the sample.
3. Difference between stratified sampling and quota sampling?
The main difference is how, samples are selected after defining the strata. In stratified sampling the samples are drawn randomly, while in quota convenience sampling is used.
Share your thoughts in the comments
Please Login to comment...