How to Add Multiple Columns in PySpark Dataframes ?
Last Updated :
30 Jun, 2021
In this article, we will see different ways of adding Multiple Columns in PySpark Dataframes.
Let’s create a sample dataframe for demonstration:
Dataset Used: Cricket_data_set_odi
Python3
import pandas as pd
import pyspark
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
df=spark.read.option(
"header",True).csv("Cricket_data_set_odi.csv")
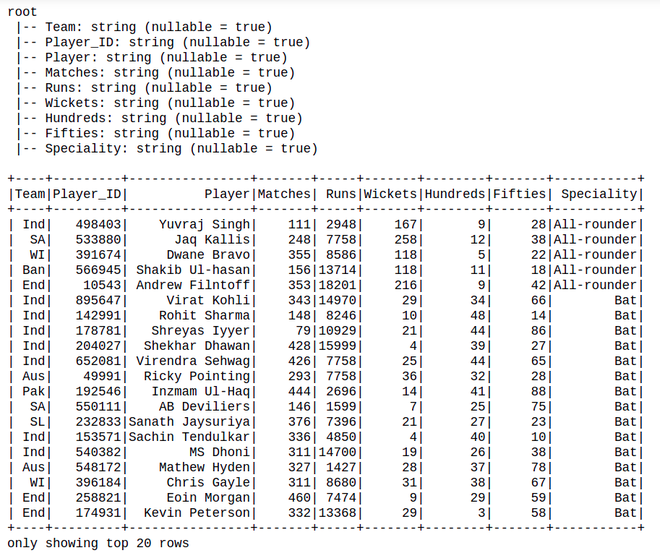
df.printSchema()
df.show()
|
Output:
Method 1: Using withColumn()
withColumn() is used to add a new or update an existing column on DataFrame
Syntax: df.withColumn(colName, col)
Returns: A new :class:`DataFrame` by adding a column or replacing the existing column that has the same name.
Code:
Python3
df.withColumn(
'Avg_runs', df.Runs / df.Matches).withColumn(
'wkt+10', df.Wickets+10).show()
|
Output:

Method 2: Using select()
You can also add multiple columns using select.
Syntax: df.select(*cols)
Code:
Python3
df.select('*', (df.Runs / df.Matches).alias('Avg_runs'),
(df.Wickets+10).alias('wkt+10')).show()
|
Output :

Method 3: Adding a Constant multiple Column to DataFrame Using withColumn() and select()
Let’s create a new column with constant value using lit() SQL function, on the below code. The lit() function present in Pyspark is used to add a new column in a Pyspark Dataframe by assigning a constant or literal value.
Python3
from pyspark.sql.functions import col, lit
df.select('*',lit("Cricket").alias("Sport")).
withColumn("Fitness",lit(("Good"))).show()
|
Output:

Share your thoughts in the comments
Please Login to comment...