How Ensemble Modeling Helps to Avoid Overfitting
Last Updated :
29 Feb, 2024
Our data often contains noise and other irregularities and if we train an overly complex machine learning model on this data, it might lead to overfitting. One of the most a powerful strategy to overcome the effects of overfitting is Ensemble modeling whereby simply combining multiple models into one, we reduce the risk of overfitting to a great extent. In this article, we’ll explore the working of ensemble modeling works along with some practical steps you can take to implement it effectively using the scikit-learn module.
What is overfitting?
Overfitting is a common issue in the Machine Learning domain where a model learns so perfectly on the given data that it fails to generalize well to unseen data, leading to poor performance in real-world scenarios.
Ensembling Techniques
Now that we have an idea of overfitting, let us briefly understand what the ensemble learning technique is. In ensemble modelling, predictions from several separate models are combined to provide a final prediction, thereby improving the performance in comparison to any of the individual models by themselves.
We can compare this to a cricket team where each member (model) has a specific role and contributes to the team’s overall performance. Similar to how a diversified team can outperform a single player, ensemble learning brings together a range of models to improve the accuracy and reliability in making predictions.
There are two well-known ensemble techniques that are effective at overcoming overfitting:
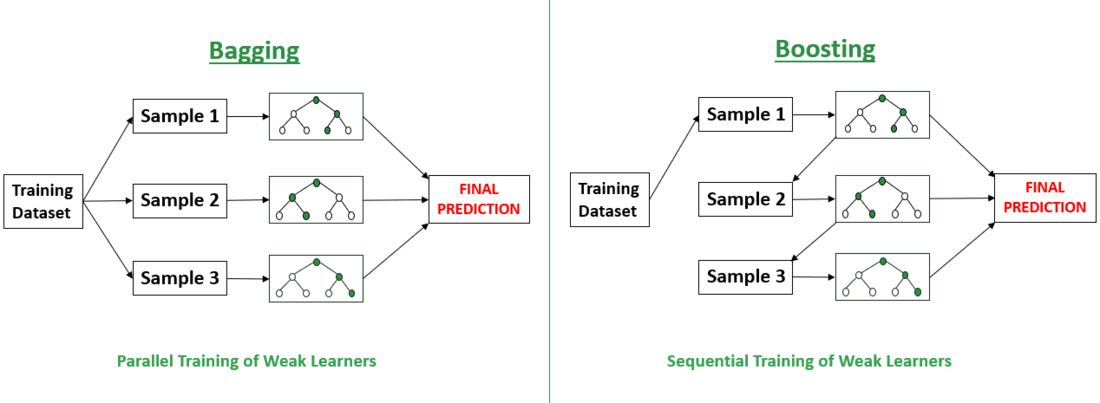
- Bagging: Bagging works by training several versions of a base model on various subsets of the training data (sampled with replacement), and then averaging or taking a majority vote of the predictions from these models, to reduce variance and prevent overfitting.
- Boosting: Boosting, on the other hand, creates a strong model by sequentially combining the outputs of weak learners, with each model focusing on correcting the errors of the previous one to boost performance and minimize overfitting. The final prediction is a weighted sum of the predictions made by each model.
How does Ensemble Modeling Avoid Overfitting?
Overfitting happens when a model is overly complex and closely matches the training data, resulting in decreased performance on new data. Ensemble modeling prevents overfitting by merging various models to generate a more generalized and precise prediction. This results in an overall decrease in prediction variance and minimizes the bias in modeling methods.
- Bias: Measures the average difference between predicted and actual values.
- Variance: Measures how predictions on the same data point vary.
- Irreducible Error: Represents data noise that cannot be minimized.
.jpg)
Implementation
Import Required Libraries
Python
import numpy as np
import matplotlib.pyplot as plt
from sklearn.tree import DecisionTreeRegressor
from sklearn.ensemble import RandomForestRegressor, GradientBoostingRegressor
from sklearn.datasets import make_regression
from sklearn.model_selection import train_test_split
|
Generating and splitting the dataset
Here we have generated a synthetic dataset with some noise for regression using the “make_regression” function from scikit-learn.
After creating the dataset, we now split the data into training and testing sets using the “train_test_split” function.
Python
X, y = make_regression(n_samples=30, n_features=1, noise=30, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
|
Model Implementation
Now we train various machine learning models on our training data. For this we have chosen the Random Forest model which follows bagging technique, Gradient Boosting model which follows Boosting technique and a simple Decision Tree model which does not follow ensembling techniques.
Python
rf = RandomForestRegressor(n_estimators=100, max_depth=5, random_state=123)
rf.fit(X_train, y_train)
gb = GradientBoostingRegressor(n_estimators=100, max_depth=5, random_state=123)
gb.fit(X_train, y_train)
dt = DecisionTreeRegressor(max_depth=3, random_state=123)
dt.fit(X_train, y_train)
|
Calculating Accuracy
After model training we display the training and testing accuracies of the various models.
Python
dt_accuracy_train = dt.score(X_train, y_train)
dt_accuracy_test = dt.score(X_test, y_test)
rf_accuracy_train = rf.score(X_train, y_train)
rf_accuracy_test = rf.score(X_test, y_test)
gb_accuracy_train = gb.score(X_train, y_train)
gb_accuracy_test = gb.score(X_test, y_test)
print("Decision Tree - Training Accuracy:", f"{dt_accuracy_train:.2f}")
print("Decision Tree - Test Accuracy:", f"{dt_accuracy_test:.2f}")
print("Random Forest - Training Accuracy:", f"{rf_accuracy_train:.2f}")
print("Random Forest - Test Accuracy:", f"{rf_accuracy_test:.2f}")
print("Gradient Boosting - Training Accuracy:", f"{gb_accuracy_train:.2f}")
print("Gradient Boosting - Test Accuracy:", f"{gb_accuracy_test:.2f}")
|
Output:
Decision Tree - Training Accuracy: 0.96
Decision Tree - Test Accuracy: 0.75
Random Forest - Training Accuracy: 0.96
Random Forest - Test Accuracy: 0.85
Gradient Boosting - Training Accuracy: 1.00
Gradient Boosting - Test Accuracy: 0.83
As it is evident from the output, all three models exhibit similar training accuracies. However, the key difference lies in their test accuracies. The Decision Tree model demonstrates a high training accuracy of 0.96 but a lower testing accuracy of 0.75, suggesting potential overfitting. In contrast, both the Random Forest and Gradient Boosting models achieve higher testing accuracies of 0.85 and 0.83, respectively, compared to their training accuracies. This highlights the effectiveness of ensemble models in generalizing to new data, emphasizing their advantage in reducing overfitting and enhancing model performance on unseen data.
Conclusion
Overfitting poses a significant challenge to the predictive power of machine learning models. However, ensemble modeling offers a powerful solution by not only effectively addressing overfitting but also enhancing the predictive capabilities of individual models.
Share your thoughts in the comments
Please Login to comment...