What are Heartbeat Messages?
Last Updated :
18 Mar, 2024
Heartbeat messages are periodic signals sent between components of a distributed system to indicate that they are still alive and functioning properly. These messages serve as a form of health check, allowing each component to monitor the status of its peers and detect failures or network issues. The term “heartbeat” comes from the analogy of the periodic pulsing of a heart, indicating that it is still beating and functioning. Similarly, in a distributed system, heartbeat messages are regularly sent between components to ensure that they are operational.

Important Topics for Heartbeat Messages
What are Heartbeat Messages?
In a distributed system, heartbeat messages are brief, recurrent signals that are sent between various nodes, which can be servers, services, or other components. In the simplest terms, they say, “Hey, I’m alive and functioning!”
- In distributed systems, heartbeat messages are similar to routine check-ins you might have with close associates to make sure everything is well.
- Small, regular messages are exchanged between machines to verify that they are all still up and running and linked to the network.
- Simple signals known as heartbeat messages are sent from one node (a server, or a component) to another regularly.
- A node can determine that the sender is not available or has failed if it does not receive a heartbeat within a specified period.
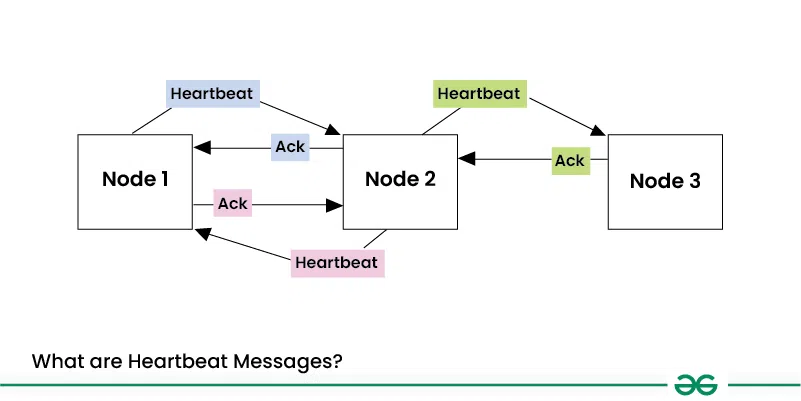
Importance of Heartbeat Messages in Distributed Systems
Heartbeat messages play a crucial role in ensuring the reliability, availability, and fault tolerance of distributed systems. Here are some key reasons why heartbeat messages are important:
- Failure Detection: Heartbeat messages are used to detect failures in distributed systems. By regularly sending and monitoring heartbeat messages, components can quickly detect when a peer becomes unresponsive or fails. This allows for timely action to be taken, such as initiating failover procedures or restarting the failed component.
- Health Monitoring: Heartbeat messages provide a way to monitor the health and availability of components in real time. By analyzing the receipt of heartbeat messages, administrators can gain insights into the overall health of the system and identify potential issues before they cause major problems.
- Load Balancing: In systems where components are responsible for handling incoming requests or tasks, heartbeat messages can be used for load balancing. By monitoring the load and availability of components through heartbeat messages, requests can be routed to the most suitable and available components, ensuring optimal performance and resource utilization.
- Network Partition Detection: Heartbeat messages can also be used to detect network partitions, where components become isolated from each other due to network issues. By monitoring the receipt of heartbeat messages, components can detect when they are no longer receiving messages from certain peers, indicating a potential network partition.
- Maintaining Consistency: In systems that use distributed consensus algorithms, such as Paxos or Raft, heartbeat messages are used to maintain consistency among nodes. These algorithms rely on regular communication between nodes, and heartbeat messages ensure that nodes are still reachable and operational.
Overall, heartbeat messages are a critical component of distributed systems, helping to ensure their reliability, availability, and fault tolerance. By providing a mechanism for failure detection, health monitoring, load balancing, and network partition detection, heartbeat messages help to keep distributed systems running smoothly and efficiently.
Purpose of Heartbeat Messages
A distributed systems heartbeat messages are its hidden champions, they keep everything running smoothly and react quickly to errors. Let us analyze their goal in more detail now.
1. Liveness Monitoring
- Basic Functionality: Heartbeats are brief messages that are sent on a regular basis to a designated recipient (another node or monitoring service) by a node (server, service). Everyone is informed about the sender’s liveliness by this frequent activity
- Frequency: The time between heart beats is very important. It should occur frequently enough to identify malfunctions quickly, but not frequently enough to generate unnecessary network traffic.
2. Failure Detection
- Missed Heartbeats: A possible problem may arise if a recipient does not receive a heartbeat within a certain amount of time (referred to as the heartbeat timeout). The beneficiary may:
- Declare the sender failed: This triggers actions like service failover or job reassignment.
- Initiate further checks: The recipient might send additional messages or attempt to ping the sender before declaring it failed.
3. Advanced Applications
- Beyond Liveness: Although a basic heartbeat indicates that a person is “alive,” some systems carry additional data in the payload of the message. This may consist of:
- Resource Usage: CPU, memory, or disk usage information is useful in determining which nodes are overloaded when load balancing.
- Custom Health Checks: Certain services may involve custom heartbeat checks to confirm that the heartbeats are functioning properly beyond just being alive.
- Leader Election: In leader-based clusters, in the event that the current leader fails (stops sending heartbeats), another can be chosen using heartbeats.
4. Considerations for Robustness
- Single Point of Failure: Failure detection may be affected by a single point of failure in the heartbeat mechanism, such as a central monitoring service. Mechanisms for redundancy and failover are essential.
- Network Problems: Temporary network failures may result in heartbeats missing. This can be reduced by set up timeouts and retries.
- Security: Heartbeat messages may carry private or sensitive data. Authentication and encryption can be used to increase security.
Components of Heartbeat Messages
Heartbeat messages in a distributed system usually contain multiple components that communicate critical information about the identity, health, and status of the sender. Some common components include the following, though they may vary depending on the particular requirements and system design:
1. Identification:
- Sequence Number: In order to assist recipients in tracking the sequence of messages received and identifying any missed or out-of-order messages, certain heartbeat messages contain a sequence number or sequence ID. Sequence numbers help to identify possible communication problems or message loss and enable dependable message delivery.
- Node/Component Identifier: An identifier, also known as a unique identifier (ID), is usually included in each heartbeat message to identify the sender node or component in the distributed system. With the aid of this identifier, recipients are able to identify the source of the heartbeat message and link it to the appropriate node or component.
2. Liveness Signal:
- Timestamp: A timestamp that shows the message’s send time is frequently included in heartbeat messages. This timestamp helps in evaluating the message’s freshness and enables recipients to determine when the sender last communicated.
3. Optional Additional Information (Depending on Implementation):
- Payload/Data: Additional payload or information about the health or status of the sender may be included in heartbeat messages. Version numbers, configuration details, and other relevant information that receivers require to evaluate the sender’s status or condition may be included in this payload.
- Acknowledgment (ACK):Heartbeat messages occasionally have an acknowledgment (ACK) mechanism that allows the recipient to verify that they have received the message. By verifying that the message was successfully received and processed by the recipient, this ACK provides feedback to the sender.
- Timeout/Expiration Information: Information regarding message expiration or timeout thresholds may also be included in heartbeat messages. When a message delivery exceeds a specific limit, this information aids recipients in verifying the message’s validity and applying timeout handling mechanisms.
4. Minimal Overhead
Status Information: The sender node or component’s current operational status, health, or state may be indicated by status information included in heartbeat messages. Metrics like CPU and memory usage, disk space availability, network connectivity, and any other appropriate health indicators could be included in this data.
5. Security Considerations
Checksum/Hash: Heartbeat messages may contain a checksum or hash value computed based on the message content in order to guarantee message integrity and identify tampering or corruption. This checksum can be used by recipients to confirm the message’s integrity and identify any unauthorized changes.
Heartbeat Protocols
In distributed systems, heartbeat protocols are used as a means of communication to transfer heartbeat messages amongst nodes or components. These protocols make it easier for distributed system entities to coordinate, detect failures, and monitor system health. Several distributed systems frequently employ one of the following heartbeat protocols:
1. Simple Heartbeat Protocol (SHP)
- For the purpose of transmitting heartbeat signals between nodes in a distributed system, the Simple Heartbeat Protocol is a straightforward and lightweight protocol.
- Typically, SHP uses a straightforward message exchange to report the availability and liveness of nodes at regular intervals.
- This protocol is simple to use and appropriate in situations where a simple heartbeat mechanism is sufficient.
.webp)
2. Ping/Echo Protocol
- Sending a “ping” message from one node to another and waiting for a “echo” response from the receiving node is the Ping/Echo protocol, also called the Ping-Pong protocol.
- For network-level communication, this protocol is commonly implemented using the Internet Control Message Protocol (ICMP), and for inter-process communication, it is typically implemented using custom application-layer protocols.
- In networked environments, the Ping/Echo protocol is frequently used for basic connectivity checks and health monitoring.
.webp)
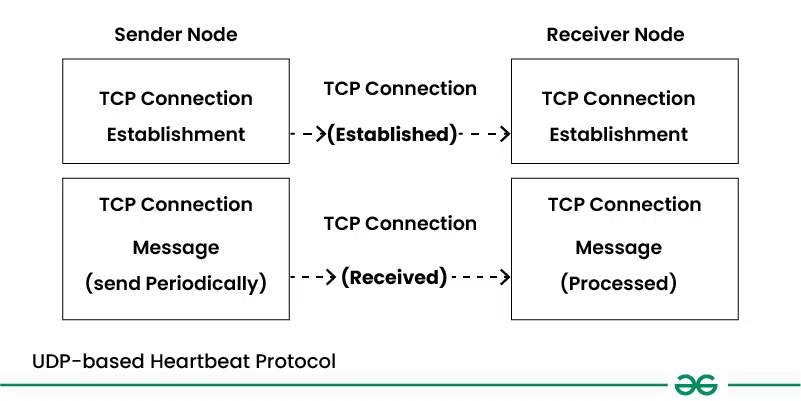
3. UDP-based Heartbeat Protocol
- User Datagram Protocol (UDP) is used by UDP-based heartbeat protocols to facilitate communication between nodes.
- These protocols usually entail periodic transmission of lightweight UDP packets with heartbeat messages inside of them.
- Protocols for UDP-based heartbeats are appropriate in situations where low latency and low overhead are required.

4. TCP-based Heartbeat Protocol:
- Transmission Control Protocol (TCP) is used by TCP-based heartbeat protocols to enable communication between nodes.
- In these protocols, nodes create a TCP connection and communicate by sending each other heartbeat messages over the connection.
- TCP-based heartbeat protocols are appropriate in situations where dependability is crucial because they guarantee message delivery and provide dependable communication.
5. Raft Protocol
- A consensus protocol called Raft is used in distributed systems to accomplish replication and fault tolerance.
- Heartbeat messages are used by the Raft protocol in the leader election and replication procedures.
- In a distributed system based on Raft, nodes communicate via heartbeat messages to track the health of the leader and identify any malfunctions.
6. Apache ZooKeeper Heartbeats
- Heartbeat messages are used by Apache ZooKeeper, a distributed coordination service, for session management and leader election.
- Clients of ZooKeeper send heartbeat messages on a regular basis to keep their session with the ZooKeeper ensemble going.
- ZooKeeper servers also use heartbeat messages to elect a leader and check if other servers are still active.
Use Cases of Heartbeat Messages
- Health Monitoring and Fault Detection: In distributed systems, heartbeat messages are frequently used to track the availability and health of component availability. This involves identifying malfunctions, unresponsiveness, or service or node crashes.
- Network Partition Detection: Heartbeat messages aid in the detection of network splits or node communication problems in distributed systems, enabling systems to take the necessary steps to preserve consistency and availability.
- Load Balancing and Resource Management: Systems can evaluate the capacity and workload of individual nodes or services by exchanging heartbeat messages, which allows for dynamic resource allocation and load balancing throughout the system.
- Timeout Handling and Connectivity Checks: Heartbeat messages are used to confirm component connectivity and manage timeouts. By doing this, it is made sure that components continue to function and be accessible even when there are network problems.
- Synchronization and Consistency: Heartbeat messages can help distributed nodes or replicas maintain consistency and synchronization, making sure that all parts are current and in sync with one another.
Benefits of Heartbeat Messages
- Improved Reliability: By facilitating proactive monitoring and failure detection, heartbeat messages contribute to increased system reliability by enabling prompt response and recovery measures.
- Enhanced Availability: Heartbeat messages help to preserve system availability and minimize downtime by continuously monitoring the condition and availability of components.
- Scalability and Performance Optimization: Heartbeat messages help with resource management and load balancing, which allows systems to scale effectively and maximize performance by dividing workloads among nodes.
- Resilience to Network Failures: Heartbeat messages help maintain systems resilience and functionality even in the face of network problems by assisting in the detection of network partitions and managing communication failures.
- Simplified Management: Heartbeat messages facilitate troubleshooting, capacity planning, and performance optimization by offering insights into the health and status of distributed components.
Challenges
- Overhead: Heartbeat messages are continuously exchanged, which can cause extra network overhead and potentially affect the scalability and performance of large-scale distributed systems.
- False Positives/Negatives: False positives, or incorrectly identifying failures, or false negatives, or failing to detect actual failures, can result from incorrectly interpreting heartbeat messages. These outcomes can impair system availability and reliability.
- Configuration Complexity: Heartbeat parameter configuration and tuning can be complicated, requiring careful consideration of system requirements and network characteristics. Examples of these parameters include message frequency, timeout thresholds, and failure detection mechanisms.
- Security Risks: Heartbeat messages are open to monitoring, tampering, or denial-of-service attacks because they might include sensitive information about the health and status of the system. To reduce these risks, appropriate security measures like authentication and encryption are required.
- Dependency on Network Performance: Systems that rely on heartbeat messages are susceptible to network-related problems like congestion, packet loss, and latency because heartbeat messages depend on network performance and connectivity.
Conclusion
Heartbeat messages, while seemingly simple, play a vital role in distributed system design. They provide the foundation for monitoring health, detecting failures early, and ensuring robust fault tolerance. By understanding the use cases, benefits, and challenges associated with heartbeats, system designers can create reliable and scalable distributed systems.
Share your thoughts in the comments
Please Login to comment...