Scala stands for scalable language. It is a statically typed language although unlike other statically typed languages like C, C++, or Java, it doesn't require type information while writing the code. The type verification is done at the compile time. Static typing allows us to build safe systems by default. Smart built-in checks and actionable error messages, combined with thread-safe data structures and collections, prevent many tricky bugs before the program first runs.
Understanding Dataframe and Spark
A DataFrame is a data structure in the Spark Language. Spark is used to develop distributed products i.e. a code that can be run on many machines at the same time.
- The main purpose of such products is to process large data for business analysis.
- The DataFrame is a tabular structure that can store structured and semi-structured data.
- For unstructured data, we need to modify it to fit into the data frame.
- Dataframes are built on the core API of Spark called RDDs to provide type-safety, optimization, and other things.
Building Sample DataFrames
Let us build two sample DataFrame to perform join upon in Scala.
import org.apache.spark.sql.SparkSession
object joindfs{
def main(args:Array[String]) {
val spark: SparkSession = SparkSession.builder().master("local[1]").getOrCreate()
val class_columns = Seq("Id", "Name")
val class_data = Seq((1, "Dhruv"), (2, "Akash"), (3, "Aayush"))
val class_df = spark.createDataFrame(class_data).toDF(class_columns:_*)
val result_column = Seq("Id", "Subject", "Score")
val result_data = Seq((1, "Maths", 98), (2, "Maths", 99), (3, "Maths", 94), (1, "Physics", 95), (2, "Physics", 97), (3, "Physics", 99))
val result_df = spark.createDataFrame(result_data).toDF(result_column:_*)
class_df.show()
result_df.show()
}
}
Output:

class_df

result_df
Explanation:
Here we have formed two dataframes.
- The first one is the class dataframe which contains the information about students in a classroom.
- The second one is the result dataframe which contains the marks of students in Maths and Physics.
- We will form a combined dataframe that will contain both student and result information.
Let us see how to join these dataframes now.
Joining DataFrames
Use df.join()
We can join one dataframe with another using the join statement. Let us see various examples of joins below.
Example 1: Specify join columns as a String or Sequence of String
If the column name in both dataframes are same we can simply write the names of the columns on which we want to join.
val joined_df = class_df.join(result_df, Seq("id"))
// OR
val joined_df = class_df.join(result_df, "id")
joined_df.show()
Output:
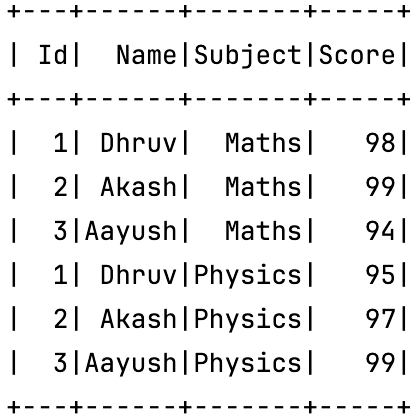
Joined_df
As it can be seen above the dataframes were joined by specifying the name of the common column.
Example 2: Specify join condition using expressions
If the column names are not same then we can use the join expressions to specify the match condition. The code for this type of join is as follows:
import spark.implicits._
val joined_df = class_df.join(result_df, class_df("id") === result_df("id")).select(result_df("Id"), $"Name", $"Subject", $"Score")
joined_df.show()
Output:

joined_df
As seen above the join is performed using the expression.
We can also specify the join condition in both of the above examples. Let us try to do a left join of the class dataframe with the result dataframe. We will remove the last id from the result dataframe to verify that the left join is actually performed. The code for the left join is as follows:
val result_filtered_df = result_df.filter("id in (1,2)")
val joined_df = class_df.join(result_filtered_df, "Id", "left")
joined_df.show()
Output:
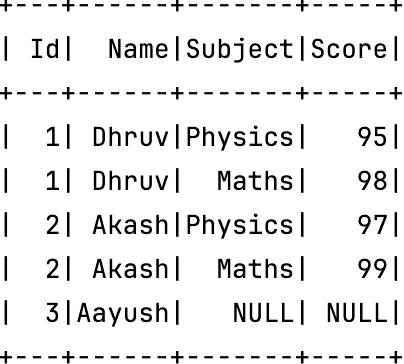
left join
As seen above, the left join was performed successfully. The missing record for results was filled with NULL values. Similarly, we can perform left join with example 2 as well.
Using SQL
We can also join the two dataframes using sql. To do that we will first need to convert the dataframes to views. We will then join the views and store the result to another dataframe. Let us see how to perform the join using SQL.
class_df.createOrReplaceTempView("class_df_view")
result_df.createOrReplaceTempView("result_df_view")
var joined_df = spark.sql("SELECT cl.Id, Name, Subject, Score FROM class_df_view cl INNER JOIN result_df_view rs ON cl.Id = rs.ID")
joined_df.show()
Output:
joined_dJ
As seen above the views were joined to create a new dataframe. This method helps those familiar with the SQL syntax and allows for easy migration from SQL projects. Although the views are extra but since they are temporary they will be deleted after the session ends.
Conclusion
In this article we have seen how to join the two dataframes in scala. Majorly, this can be done either using the scala join function or the SQL syntax. The scala join function further can be called in two ways, using strings or expressions. The strings method can be used if the column names are common in both the dataframes. In that case, the join columns can be specified using a list of strings. In the case, the column names are not common we can use the expressions to specify the join condition. The sql method creates temporary views from the dataframes and performs the join on them. It then creates another dataframe from the result of join as the joined dataframe.