With DataFrames in Apache Spark using Scala, you could check the schema of a DataFrame and get to know its structure with column types. The schema contains data types and names of columns that are available in a DataFrame.
Apache Spark is a powerful distributed computing framework used for processing big data. It provides structured data manipulation APIs through DataFrames which represent collections of distributed data organized into named columns.
Prerequisites:
Before we begin, we need to import some packages and create a SparkSession:
import org.apache.spark.sql.{SparkSession, DataFrame}
val spark = SparkSession.builder()
.appName("Check Schema Example")
.getOrCreate()
import spark.implicits._
Implementation:
Sample DataFrame
DataFrame is an important concept in Spark so we can create one of them for this exercise.
val data = Seq(
("John", 30, true),
("Alice", 25, false),
("Bob", 35, true)
)
val df = data.toDF("Name", "Age", "IsStudent")
Read the DataFrame
If you already have a DataFrame, you can read it from a file or any other data source. For the purpose of this example, let’s assume that we have a DataFrame called myDataFrame.
Check Schema
To check the schema of the DataFrame, you can use the printSchema() method:
df.printSchema()
And here is the schema and the ‘printTreeString()’ method is used to visualize it in tree-like structure.
Example 1:
import org.apache.spark.sql.{SparkSession, DataFrame}
val spark = SparkSession.builder()
.appName("Check Schema Example")
.getOrCreate()
import spark.implicits._
// Sample DataFrame Creation
val data = Seq(
("A", 30, true),
("B", 25, false),
("C", 35, true)
)
val df = data.toDF("Name", "Age", "IsStudent")
// Check Schema
df.printSchema()
Output:
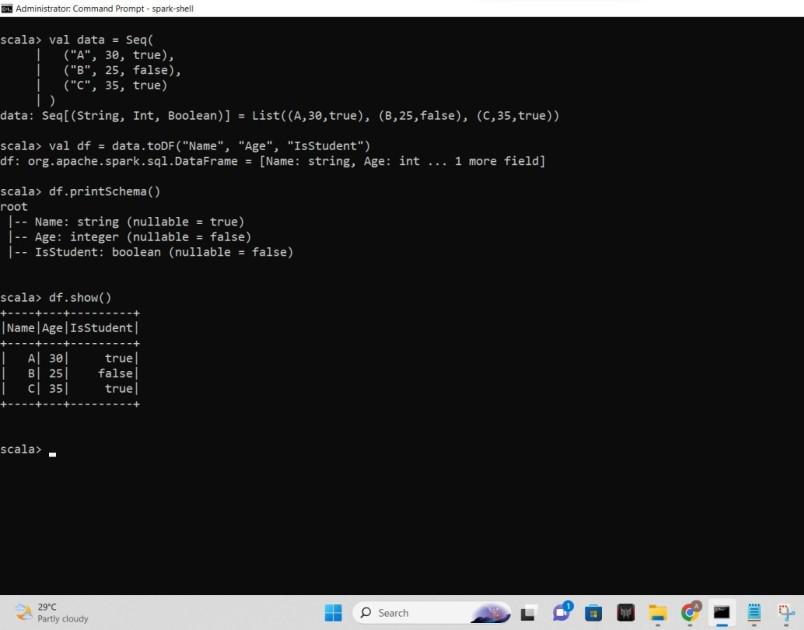
Screenshot of the output
Explanation:
- We start by importing the necessary packages and creating a SparkSession.
- we define a sample DataFrame called 'df' with three columns: "Name", "Age", and "IsStudent".
- we use the 'printSchema()' method to display the structure of the DataFrame. This shows the column names along with their data types and whether they can accept null values or not.
Example 2:
import org.apache.spark.sql.{SparkSession, DataFrame}
import org.apache.spark.sql.types._
val spark = SparkSession.builder()
.appName("Check Schema Example")
.getOrCreate()
import spark.implicits._
// Sample DataFrame Creation
val data = Seq(
(101, "Rahul", "D1", 50),
(102, "Aman", "D2", 40),
(103, "Rohit", "D3", 60),
(104, "Diya", "D4", 70),
(105, "Raman", "D5", 70),
(106, "Payal", "D6", 70),
(107, "Ajay", "D7", 60),
(108, "Riya", "D8", 50),
(109, "Arya", "D9", 50),
(110, "Suman", "D10", 80)
)
val schema = StructType(
Seq(
StructField("EID", IntegerType, nullable = false),
StructField("Ename", StringType, nullable = false),
StructField("DID", StringType, nullable = false),
StructField("Salary", IntegerType, nullable = false)
)
)
val df = spark.createDataFrame(
spark.sparkContext.parallelize(data),
schema
)
// Check Schema
df.printSchema()
Output:
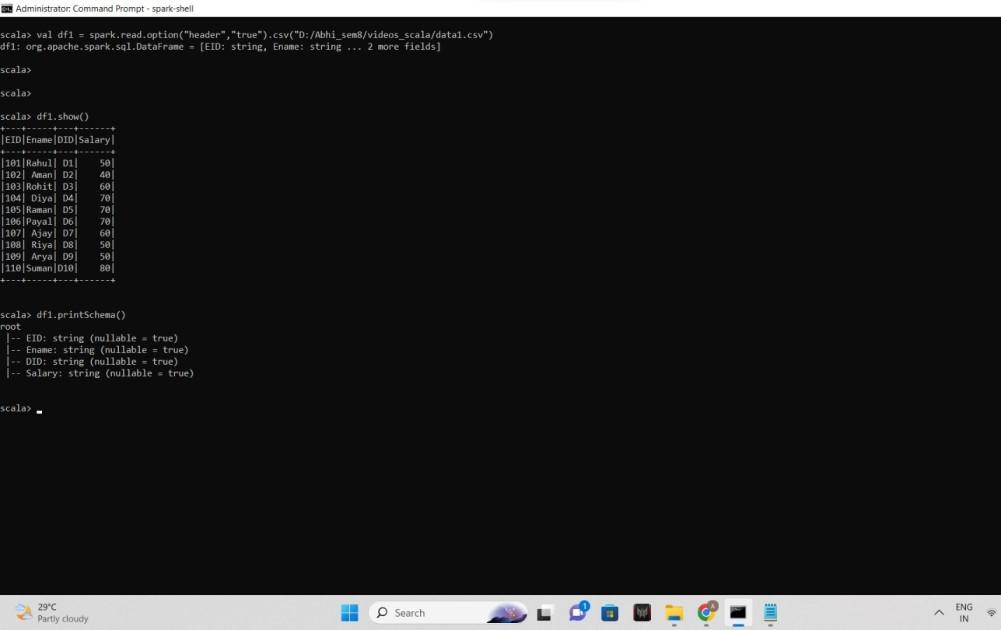
output
Conclusion
Checking the schema of a DataFrame is crucial for understanding its structure and making informed decisions about how to process and transform the data. The 'printSchema()' method provided by Apache Spark's DataFrame API makes this task easy.