XPath is important for element location in Selenium automation. With flexibility, Relative XPath navigates elements according to how they relate to other elements. While absolute XPath offers greater precision, it makes scripts larger and less flexible because it provides the entire path from the HTML document's root. Comprehending the differences between Absolute and Relative XPath is essential to effective automated programming. This article explores their differences and advises when to use each technique for reliable Selenium automation.
Table of Content
Relative XPath in Selenium
Relative XPath in Selenium refers to locating elements on a webpage based on their relationships with other elements, starting from a specific context node. Unlike Absolute XPath, which provides the full path from the root of the HTML document, Relative XPath offers more flexibility and simplicity. It is often preferred for automation testing as it adapts well to changes in the webpage structure and allows for shorter and more maintainable XPath expressions. Relative XPath expressions typically use attributes, tags, and positional relationships to identify elements efficiently.
Advantages of Relative XPath
The advantages of Relative XPath in Selenium are the following:
- Flexibility: By navigating based on relationships with other components instead of the rigid structure of the HTML text, relative XPath enables more variable element positioning.
- Robustness: Because relative XPath expressions are not dependent on particular paths from the document root, they are less likely to break when the web page's structure changes.
- Readability: Relative XPath expressions are easier to comprehend and maintain in automation scripts since they are typically shorter and more natural.
- Efficiency: Compared to Absolute XPath, Relative XPath requires less work to write and update, which might result in more efficient test scripts.
- Handling Dynamic Content: Relative XPath is more appropriate for managing items with variable properties or dynamic content, enabling more dependable automation testing.
Disadvantages of Relative XPath
Relative XPath with Selenium has a few disadvantages in addition to its benefits.
- Ambiguity: When many elements share similar relationships or properties, relative XPath may cause ambiguity in element selection, which could lead to the selection of unintentional elements.
- Performance: When browsing big DOM structures or using sophisticated XPath expressions, Relative XPath may occasionally perform less efficiently than Absolute XPath.
- Dependency on Page Structure: Because Relative XPath depends on the design and organization of the webpage, scripts run the risk of malfunctioning if there are major changes made to the page structure.
- Limited Precision: When working with intricate page layouts or aiming for components buried deep within nested structures, Relative XPath may not be as precise as Absolute XPath.
Absolute XPath in Selenium
In Selenium, Absolute XPath is a technique for finding components on a webpage by giving their precise path from the HTML document root. It gives the entire element's hierarchical path, from the top-level HTML node to the target element. This path leads to the target element and contains all of the parent nodes, divided by slashes (/). Although Absolute XPath can be more accurate when locating items, it is less flexible and typically longer than Relative XPath, which increases the likelihood that it will break when the structure of the webpage changes.
Advantages of Relative XPath
- Precision: Absolute XPath is less ambiguous and more precise because it gives the precise location of an element within an HTML document.
- Stability: Because absolute XPath expressions are unaffected by modifications to the relationships between elements, they are less likely to fracture as a result of alterations to the web page's structure.
- Global Accessibility: Regardless of an element's location or connection to other elements, Absolute XPath can access any element in the document.
- Selecting Complex Elements: Absolute XPath enables accurate targeting of elements buried in intricate page layouts or nested structures.
- Debugging: Absolute XPath can be helpful in debugging because it gives you a full path to the element, which makes it easier to figure out why some selections fail.
Disadvantages of Relative XPath
- Fragility: Scripts are more likely to break if the HTML structure changes since absolute XPath expressions are typically longer and less flexible.
- Maintenance: Updating Absolute XPath whenever the structure of a webpage changes results in more maintenance overhead.
- Readability: Absolute XPath expressions in automation scripts can be more difficult to comprehend and maintain due to their verbose and less intuitive nature.
- Performance: When browsing big DOM structures or using sophisticated XPath expressions, Absolute XPath may be less efficient than Relative XPath.
- Dependency on Page Structure: Because Absolute XPath relies so heavily on the page structure, scripts written with it are less adaptable to alterations made to the web page's layout or design.
Choosing the Right XPath Strategy
Choosing the right XPath strategy is crucial for effective and robust Selenium automation. Here's a guide to help you make the right choice:
- Know the Webpage: Understand how the webpage is built. Look for unique features or patterns in the elements you want to click or interact with.
- Stable or Flexible: Absolute XPath is like a ruler - precise but less flexible. Relative XPath is like a rubber band - more adaptable to changes.
- Look for Clues: Use the browser's tools to find clues about elements, like unique IDs or how they're related to other parts of the page.
- Prefer Flexible XPath: Unless you're sure about the elements' stability, go for Relative XPath. It's easier to use and less likely to break.
- Use Absolute XPath Carefully: Only use Absolute XPath when you're certain about the elements' location. It's like a GPS coordinate - very specific but may change if the webpage does.
- Test and Improve: Try out your XPath expressions to make sure they work well across different browsers. Adjust them as needed to make your automation smooth and reliable.
By considering these factors and choosing the appropriate XPath strategy based on the specific requirements of your automation project, you can build robust and maintainable Selenium scripts that effectively interact with web elements on various web pages.
Examples of Relative and Absolute XPath in Selenium
1. Relative XPath:
Suppose we want to locate the "Search" input field within the navigation bar of a webpage. The Relative XPath expression could be:
//img[@class='gfg_logo_img']This XPath starts from the 'nav' element and searches for the input field with the id "search" within it. It's flexible because it doesn't depend on the exact position of the navigation bar within the document.
Example:
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.firefox.FirefoxDriver;
import org.openqa.selenium.support.ui.Select;
import org.openqa.selenium.By;
public class Xpath_Selection {
public static void main(String[] args) {
System.setProperty("webdriver.firefox.marionette", "C:\\geckodriver.exe");
WebDriver driver = new FirefoxDriver();
driver.get("https://www.stqatools.com");
// Relative xpath
driver.findElement(By.xpath("//img[@class='gfg_logo_img']"));
}
}
Output:
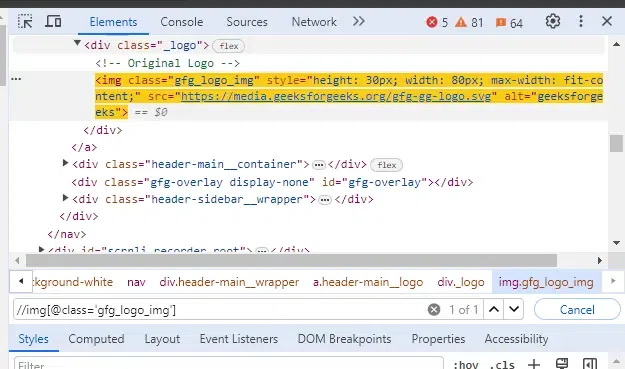
Relative XPath
2. Absolute XPath:
To find the same "Search" input field using an Absolute XPath expression:
//html[1]/body[1]/nav/div/a[2]This Absolute XPath specifies the full path from the root of the HTML document to the input field. It relies on the exact structure of the webpage, making it longer and more prone to breaking if the structure changes.
Example:
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.firefox.FirefoxDriver;
import org.openqa.selenium.support.ui.Select;
import org.openqa.selenium.By;
public class Xpath_Selection {
public static void main(String[] args) {
System.setProperty("webdriver.firefox.marionette", "C:\\geckodriver.exe");
WebDriver driver = new FirefoxDriver();
driver.get("https://www.geeksforgeeks.org");
// Absolute xpath
driver.findElement(By.xpath("/html[1]/body[1]/nav/div/a[2]"));
}
}
Output:
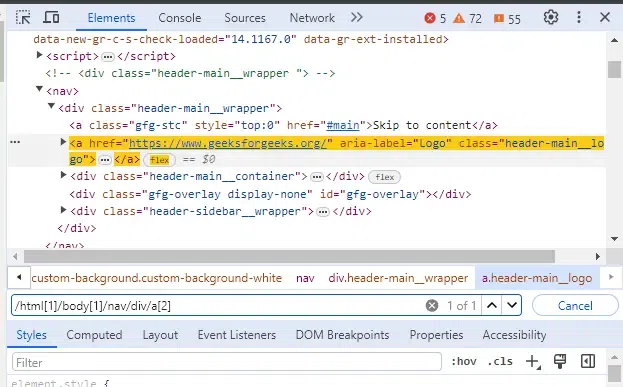
Absolute XPath Output
Best Practices for Writing XPaths
Writing XPath expressions in Selenium efficiently requires adherence to best practices. Here are guidelines for crafting both Relative and Absolute XPath expressions:
Best Practices for Relative XPath:
- Start from Unique Elements: Commence XPath from distinct parent elements to narrow the search scope and enhance resilience.
- Utilize Attributes: Favor attributes like id, class, or data attributes for precise element identification and to simplify XPath.
- Avoid Positional Indexes: Minimize reliance on positional indexes ([1], [2], etc.) to prevent XPath fragility.
- Use Axes: Employ child, descendant, or sibling axes for efficient DOM navigation and to locate elements relative to others.
- Thorough Testing: Validate XPath across diverse browsers and environments to ensure consistency and compatibility.
Best Practices for Absolute XPath:
- Be Specific: Provide a complete path from root to target element for accuracy.
- Minimize Indexing: Limit positional indexing to maintain concise and resilient XPath.
- Avoid Dynamic Attributes: Steer clear of dynamic attributes like dynamically generated IDs to prevent XPath fragility.
- Consider Debugging: Absolute XPath aids debugging and suits scenarios with stable, unique attributes.
- Regular Maintenance: Periodically review and update Absolute XPath expressions to accommodate webpage structure changes.
Related Articles:
- Introduction to XPath
- XPath Relative Path
- XPath Absolute Path
- Locating Strategies By XPath Using Java
- Selenium Basics – Components, Features, Uses and Limitations
Conclusion
In conclusion, understanding the differences between Absolute and Relative XPath is crucial for effective Selenium automation. While Absolute XPath offers precision, it's less flexible and prone to breakage. On the other hand, Relative XPath provides flexibility and adaptability, making it preferred for most automation tasks. By following best practices and choosing the right XPath strategy based on your project's needs, you can create robust and maintainable Selenium scripts. Remember to regularly review and update XPath expressions to accommodate changes in webpage structure, ensuring smooth and reliable automation.
FAQs on Difference between Relative and Absolute XPath in Selenium
What is the difference between Absolute and Relative XPath in Selenium?
Ans: Absolute XPath provides the full path from the HTML document's root, offering precision but less flexibility. Relative XPath navigates elements based on relationships, providing more adaptability.
When should I use Absolute XPath over Relative XPath?
Ans: Absolute XPath is suitable when precise element location is critical, but it's less flexible and prone to breakage. Use it sparingly when element positioning is stable.
What are the advantages of Relative XPath in Selenium?
Ans: Relative XPath offers flexibility, robustness against webpage structure changes, readability, and efficiency compared to Absolute XPath.
How can I choose the right XPath strategy for Selenium automation?
Ans: Consider the stability of elements, use clues from the webpage, prefer flexibility with Relative XPath unless precision is crucial, and test XPath expressions across browsers for reliability.