Python is a great language for doing data analysis, primarily because of the fantastic ecosystem of data-centric Python packages. Pandas is one of those packages and makes importing and analyzing data much easier.
Dataframe.aggregate() function is used to apply some aggregation across one or more columns. Aggregate using callable, string, dict, or list of string/callables. The most frequently used aggregations are:
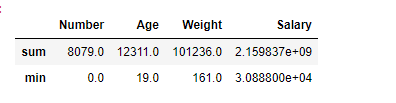
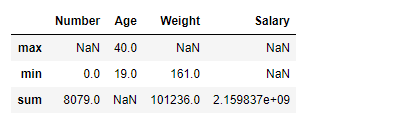
- sum: Return the sum of the values for the requested axis
- min: Return the minimum of the values for the requested axis
- max: Return the maximum of the values for the requested axis
Pandas dataframe.aggregate() Syntax in Python
Syntax: DataFrame.aggregate(func, axis=0, *args, **kwargs)
Parameters:
- func : callable, string, dictionary, or list of string/callables. Function to use for aggregating the data. If a function, must either work when passed a DataFrame or when passed to DataFrame.apply. For a DataFrame, can pass a dict, if the keys are DataFrame column names.
- axis : (default 0) {0 or ‘index’, 1 or ‘columns’} 0 or ‘index’: apply function to each column. 1 or ‘columns’: apply function to each row.
Returns: Aggregated DataFrame
Python dataframe.aggregate() Example
Below, we are discussing how to add values of Excel in Python using Pandas , we will see step-by-step how to add values of Excel in Python using Pandas are follows:
For link to CSV file Used in Code, click
Step 1: Importing Pandas and Reading CSV File
Aggregate 'sum' and 'min' function across all the columns in data frame.
Python3
# importing pandas package
import pandas as pd
# making data frame from csv file
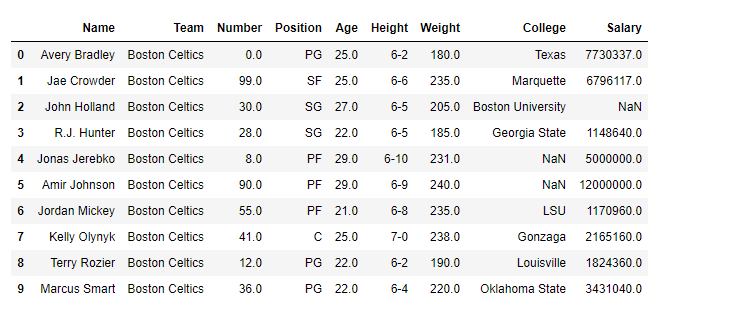
df = pd.read_csv("nba.csv")
# printing the first 10 rows of the dataframe
df[:10]