Pipelining and Addressing modes
Question 1
A five-stage pipeline has stage delays of 150,120,150,160 and 140 nanoseconds. The registers that are used between the pipeline stages have a delay of 5 nanoseconds each.
The total time to execute 100 independent instructions on this pipeline, assuming there are no pipeline stalls, is _______ nanoseconds.
Question 2
Consider a pipelined processor with 5 stages, Instruction Fetch(IF), Instruction Decode(ID), Execute (EX), Memory Access (MEM), and Write Back (WB). Each stage of the pipeline, except the EX stage, takes one cycle. Assume that the ID stage merely decodes the instruction and the register read is performed in the EX stage. The EX stage takes one cycle for ADD instruction and the register read is performed in the EX stage, The EX stage takes one cycle for ADD instruction and two cycles for MUL instruction. Ignore pipeline register latencies.
Consider the following sequence of 8 instructions:
ADD, MUL, ADD, MUL, ADD, MUL, ADD, MULAssume that every MUL instruction is data-dependent on the ADD instruction just before it and every ADD instruction (except the first ADD) is data-dependent on the MUL instruction just before it. The speedup defined as follows.
Speedup = (Execution time without operand forwarding) / (Execution time with operand forwarding)The Speedup achieved in executing the given instruction sequence on the pipelined processor (rounded to 2 decimal places) is _____________ .
Question 3
Consider an instruction pipeline with five stages without any branch prediction: Fetch Instruction (FI), Decode Instruction (DI), Fetch Operand (FO), Execute Instruction (EI) and Write Operand (WO). The stage delays for FI, DI, FO, EI and WO are 5 ns, 7 ns, 10 ns, 8 ns and 6 ns, respectively. There are intermediate storage buffers after each stage and the delay of each buffer is 1 ns. A program consisting of 12 instructions I1, I2, I3, …, I12 is executed in this pipelined processor. Instruction I4 is the only branch instruction and its branch target is I9. If the branch is taken during the execution of this program, the time (in ns) needed to complete the program is
Question 5
Consider a hypothetical processor with an instruction of type LW R1, 20(R2), which during execution reads a 32-bit word from memory and stores it in a 32-bit register R1. The effective address of the memory location is obtained by the addition of a constant 20 and the contents of register R2. Which of the following best reflects the addressing mode implemented by this instruction for operand in memory?
Question 6
Consider evaluating the following expression tree on a machine with load-store architecture in which memory can be accessed only through load and store instructions. The variables a, b, c, d and e initially stored in memory. The binary operators used in this expression tree can be evaluate by the machine only when the operands are in registers. The instructions produce results only in a register. If no intermediate results can be stored in memory, what is the minimum number of registers needed to evaluate this expression?
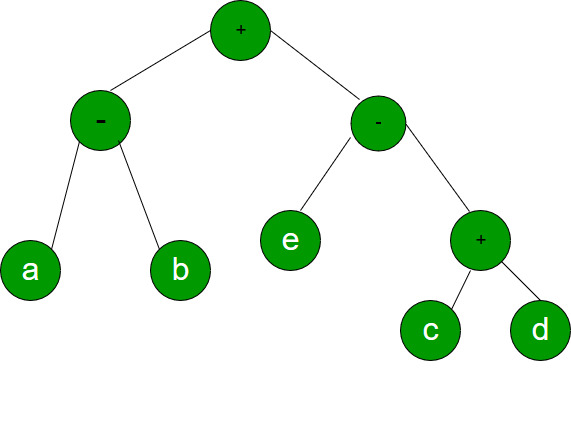
Question 7
Consider an instruction pipeline with four stages (S1, S2, S3 and S4) each with combinational circuit only. The pipeline registers are required between each stage and at the end of the last stage. Delays for the stages and for the pipeline registers are as given in the figure:
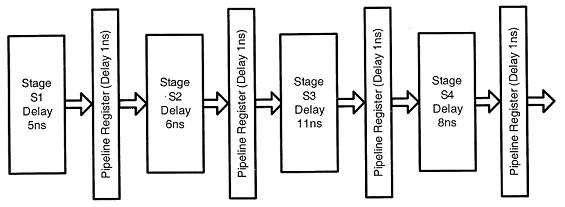 What is the approximate speed up of the pipeline in steady state under ideal conditions when compared to the corresponding non-pipeline implementation?
What is the approximate speed up of the pipeline in steady state under ideal conditions when compared to the corresponding non-pipeline implementation?
 What is the approximate speed up of the pipeline in steady state under ideal conditions when compared to the corresponding non-pipeline implementation?
What is the approximate speed up of the pipeline in steady state under ideal conditions when compared to the corresponding non-pipeline implementation? Question 8
A 5-stage pipelined processor has Instruction Fetch(IF),Instruction Decode(ID),Operand Fetch(OF),Perform Operation(PO)and Write Operand(WO)stages.The IF,ID,OF and WO stages take 1 clock cycle each for any instruction.The PO stage takes 1 clock cycle for ADD and SUB instructions,3 clock cycles for MUL instruction,and 6 clock cycles for DIV instruction respectively.Operand forwarding is used in the pipeline.What is the number of clock cycles needed to execute the following sequence of instructions?
Instruction Meaning of instruction I0 :MUL R2 ,R0 ,R1 R2 ¬ R0 *R1 I1 :DIV R5 ,R3 ,R4 R5 ¬ R3/R4 I2 :ADD R2 ,R5 ,R2 R2 ¬ R5+R2 I3 :SUB R5 ,R2 ,R6 R5 ¬ R2-R6
Question 9
The program below uses six temporary variables a, b, c, d, e, f.
a = 1
b = 10
c = 20
d = a+b
e = c+d
f = c+e
b = c+e
e = b+f
d = 5+e
return d+f
Assuming that all operations take their operands from registers, what is the minimum number of registers needed to execute this program without spilling?
Question 10
Consider a 4 stage pipeline processor. The number of cycles needed by the four instructions I1, I2, I3, I4 in stages S1, S2, S3, S4 is shown below:
What is the number of cycles needed to execute the following loop?
For (i=1 to 2) {I1; I2; I3; I4;}
|
S1 |
S2 |
S3 |
S4 |
|
|
I1 |
2 |
1 |
1 |
1 |
|
I2 |
1 |
3 |
2 |
2 |
|
I3 |
2 |
1 |
1 |
3 |
|
I4 |
1 |
2 |
2 |
2 |
There are 94 questions to complete.
Last Updated :
Take a part in the ongoing discussion