Computer Organization and Architecture
Question 12
Consider the data given in previous question. The size of the cache tag directory is
Question 13
Consider a hypothetical processor with an instruction of type LW R1, 20(R2), which during execution reads a 32-bit word from memory and stores it in a 32-bit register R1. The effective address of the memory location is obtained by the addition of a constant 20 and the contents of register R2. Which of the following best reflects the addressing mode implemented by this instruction for operand in memory?
Question 14
On a non-pipelined sequential processor, a program segment, which is a part of the interrupt service routine, is given to transfer 500 bytes from an I/O device to memory.
Initialize the address register
Initialize the count to 500
LOOP: Load a byte from device
Store in memory at address given by address register
Increment the address register
Decrement the count
If count != 0 go to LOOP
Assume that each statement in this program is equivalent to machine instruction which takes one clock cycle to execute if it is a non-load/store instruction. The load-store instructions take two clock cycles to execute. The designer of the system also has an alternate approach of using DMA controller to implement the same transfer. The DMA controller requires 20 clock cycles for initialization and other overheads. Each DMA transfer cycle takes two clock cycles to transfer one byte of data from the device to the memory. What is the approximate speedup when the DMA controller based design is used in place of the interrupt driven program based input-output?
Question 15
Consider evaluating the following expression tree on a machine with load-store architecture in which memory can be accessed only through load and store instructions. The variables a, b, c, d and e initially stored in memory. The binary operators used in this expression tree can be evaluate by the machine only when the operands are in registers. The instructions produce results only in a register. If no intermediate results can be stored in memory, what is the minimum number of registers needed to evaluate this expression?
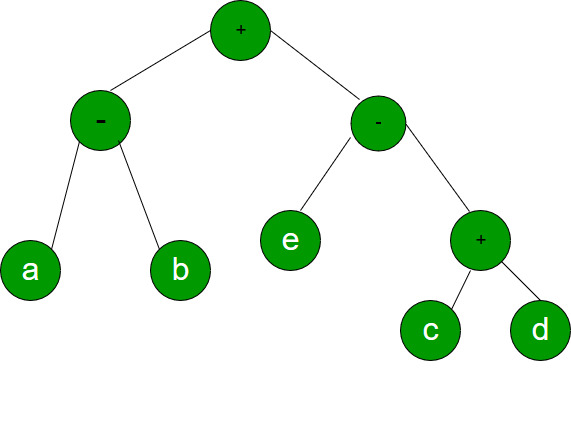
Question 16
Consider an instruction pipeline with four stages (S1, S2, S3 and S4) each with combinational circuit only. The pipeline registers are required between each stage and at the end of the last stage. Delays for the stages and for the pipeline registers are as given in the figure:
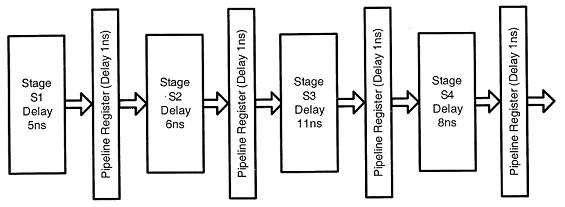 What is the approximate speed up of the pipeline in steady state under ideal conditions when compared to the corresponding non-pipeline implementation?
What is the approximate speed up of the pipeline in steady state under ideal conditions when compared to the corresponding non-pipeline implementation?
 What is the approximate speed up of the pipeline in steady state under ideal conditions when compared to the corresponding non-pipeline implementation?
What is the approximate speed up of the pipeline in steady state under ideal conditions when compared to the corresponding non-pipeline implementation? Question 17
An 8KB direct-mapped write-back cache is organized as multiple blocks, each of size 32-bytes. The processor generates 32-bit addresses. The cache controller maintains the tag information for each cache block comprising of the following.
1 Valid bit
1 Modified bit
As many bits as the minimum needed to identify the memory block mapped in the cache. What is the total size of memory needed at the cache controller to store meta-data (tags) for the cache?
Question 18
A main memory unit with a capacity of 4 megabytes is built using 1M × 1-bit DRAM chips. Each DRAM chip has 1K rows of cells with 1K cells in each row. The time taken for a single refresh operation is 100 nanoseconds. The time required to perform one refresh operation on all the cells in the memory unit is:-
A.100 nanoseconds
B.100×210 nanoseconds
C.100×220 nanoseconds
D.3200×220 nanoseconds
Question 19
A 5-stage pipelined processor has Instruction Fetch(IF),Instruction Decode(ID),Operand Fetch(OF),Perform Operation(PO)and Write Operand(WO)stages.The IF,ID,OF and WO stages take 1 clock cycle each for any instruction.The PO stage takes 1 clock cycle for ADD and SUB instructions,3 clock cycles for MUL instruction,and 6 clock cycles for DIV instruction respectively.Operand forwarding is used in the pipeline.What is the number of clock cycles needed to execute the following sequence of instructions?
Instruction Meaning of instruction I0 :MUL R2 ,R0 ,R1 R2 ¬ R0 *R1 I1 :DIV R5 ,R3 ,R4 R5 ¬ R3/R4 I2 :ADD R2 ,R5 ,R2 R2 ¬ R5+R2 I3 :SUB R5 ,R2 ,R6 R5 ¬ R2-R6
Question 20
The program below uses six temporary variables a, b, c, d, e, f.
a = 1
b = 10
c = 20
d = a+b
e = c+d
f = c+e
b = c+e
e = b+f
d = 5+e
return d+f
Assuming that all operations take their operands from registers, what is the minimum number of registers needed to execute this program without spilling?
There are 241 questions to complete.
Last Updated :
Take a part in the ongoing discussion