GATE-CS-2005
Question 4
Which one of the following are essential features of an object-oriented programming language? (GATE CS 2005) (i) Abstraction and encapsulation (ii) Strictly-typedness (iii) Type-safe property coupled with sub-type rule (iv) Polymorphism in the presence of inheritance
Question 5
A program P reads in 500 integers in the range [0..100] representing the scores of 500 students. It then prints the frequency of each score above 50. What would be the best way for P to store the frequencies?
Question 6
An undirected graph C has n nodes. Its adjacency matrix is given by an n × n square matrix whose (i) diagonal elements are 0\'s, and (ii) non-diagonal elements are l\'s. Which one of the following is TRUE?
Question 7
The time complexity of computing the transitive closure of a binary relation on a set of n elements is known to be
Question 8
Let A, B and C be non-empty sets and let X = (A - B) - C and Y = (A - C) - (B - C). Which one of the following is TRUE?
Question 9
The following is the Hasse diagram of the poset [{a, b, c, d, e}, ≤]
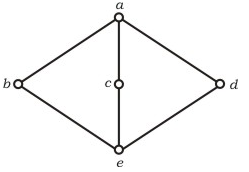 The poset is
The poset is
 The poset is
The poset is
Question 10
Let G be a simple connected planar graph with 13 vertices and 19 edges. Then, the number of faces in the planar embedding of the graph is
There are 90 questions to complete.
Last Updated :
Take a part in the ongoing discussion