Pipelining and Addressing modes
Question 21
Consider the following processors (ns stands for nanoseconds). Assume that the pipeline registers have zero latency.
P1: Four-stage pipeline with stage
latencies 1 ns, 2 ns, 2 ns, 1 ns.
P2: Four-stage pipeline with stage
latencies 1 ns, 1.5 ns, 1.5 ns, 1.5 ns.
P3: Five-stage pipeline with stage
latencies 0.5 ns, 1 ns, 1 ns, 0.6 ns, 1 ns.
P4: Five-stage pipeline with stage
latencies 0.5 ns, 0.5 ns, 1 ns, 1 ns, 1.1 ns.
Which processor has the highest peak clock frequency?
Question 22
An instruction pipeline has five stages, namely, instruction fetch (IF), instruction decode and register fetch (ID/RF), instruction execution (EX), memory access (MEM), and register writeback (WB) with stage latencies 1 ns, 2.2 ns, 2 ns, 1 ns, and 0.75 ns, respectively (ns stands for nanoseconds). To gain in terms of frequency, the designers have decided to split the ID/RF stage into three stages (ID, RF1, RF2) each of latency 2.2/3 ns. Also, the EX stage is split into two stages (EX1, EX2) each of latency 1 ns. The new design has a total of eight pipeline stages. A program has 20% branch instructions which execute in the EX stage and produce the next instruction pointer at the end of the EX stage in the old design and at the end of the EX2 stage in the new design. The IF stage stalls after fetching a branch instruction until the next instruction pointer is computed. All instructions other than the branch instruction have an average CPI of one in both the designs. The execution times of this program on the old and the new design are P and Q nanoseconds, respectively. The value of P/Q is __________.
Question 23
A CPU has a five-stage pipeline and runs at 1 GHz frequency. Instruction fetch happens in the first stage of the pipeline. A conditional branch instruction
computes the target address and evaluates the condition in the third stage of the pipeline. The processor stops fetching new instructions following a conditional branch until the branch outcome is known. A program executes 109 instructions out of which 20% are conditional branches. If each instruction takes one cycle to complete on average, the total execution time of the program is:
Question 24
Consider a three word machine instruction
ADD A[R0], @ BThe first operand (destination) "A [R0]" uses indexed addressing mode with R0 as the index register. The second operand (source) "@ B" uses indirect addressing mode. A and B are memory addresses residing at the second and the third words, respectively. The first word of the instruction specifies the opcode, the index register designation and the source and destination addressing modes. During execution of ADD instruction, the two operands are added and stored in the destination (first operand). The number of memory cycles needed during the execution cycle of the instruction is
Question 25
Match each of the high level language statements given on the left hand side with the most natural addressing mode from those listed on the right hand side.
1 A[1] = B[J]; a Indirect addressing 2 while [*A++]; b Indexed, addressing 3 int temp = *x; c Autoincrement
Question 26
A 5 stage pipelined CPU has the following sequence of stages:
IF — Instruction fetch from instruction memory,
RD — Instruction decode and register read,
EX — Execute: ALU operation for data and address computation,
MA — Data memory access - for write access, the register read
at RD stage is used,
WB — Register write back.
Consider the following sequence of instructions:
I1 : L R0, 1oc1; R0 <= M[1oc1]
I2 : A R0, R0; R0 <= R0 + R0
I3 : S R2, R0; R2 <= R2 - R0
Let each stage take one clock cycle.
What is the number of clock cycles taken to complete the above sequence of instructions starting from the fetch of I1 ?
Question 27
Consider the following data path of a CPU.
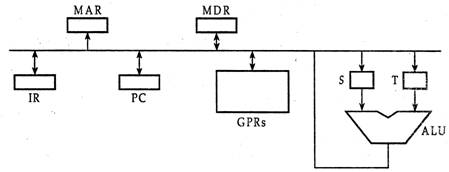
The, ALU, the bus and all the registers in the data path are of identical size. All operations including incrementation of the PC and the GPRs are to be carried out in the ALU. Two clock cycles are needed for memory read operation - the first one for loading address in the MAR and the next one for loading data from the memory bus into the MDR 79.
The instruction “call Rn, sub” is a two word instruction. Assuming that PC is incremented during the fetch cycle of the first word of the instruction, its register transfer interpretation is
Rn < = PC + 1; PC < = M[PC];
The minimum number of clock cycles needed for execution cycle of this instruction is.
Question 28
A 4-stage pipeline has the stage delays as 150, 120, 160 and 140 nanoseconds respectively. Registers that are used between the stages have a delay of 5 nanoseconds each. Assuming constant clocking rate, the total time taken to process 1000 data items on this pipeline will be
Question 29
For a pipelined CPU with a single ALU, consider the following situations
1. The j + 1-st instruction uses the result of the j-th instruction
as an operand
2. The execution of a conditional jump instruction
3. The j-th and j + 1-st instructions require the ALU at the same
time
Which of the above can cause a hazard ?
There are 94 questions to complete.
Last Updated :
Take a part in the ongoing discussion