Computer Organization and Architecture
Question 231
In 8085 microprocessor, what is the output of following program?
LDA 8000H
MVI B, 30H
ADD B
STA 8001H
Question 232
A direct mapped cache memory of 1 MB has a block size of 256 bytes. The cache has an access time of 3 ns and a hit rate of 94%. During a cache miss, it takes 20 ns to bring the first word of a block from the main memory, while each subsequent word takes 5 ns. The word size is 64 bits. The average memory access time in ns (round off to 1 decimal place) is ________ .
Note - This question was Numerical Type.
Question 233
A computer system with a word length of 32 bits has a 16 MB byte- addressable main memory and a 64 KB, 4-way set associative cache memory with a block size of 256 bytes. Consider the following four physical addresses represented in hexadecimal notation.
A1 = 0x42C8A4, A2 = 0x546888, A3 = 0x6A289C, A4 = 0x5E4880Which one of the following is TRUE ?
Question 234
Consider a non-pipelined processor operating at 2.5 GHz. It takes 5 clock cycles to complete an instruction. You are going to make a 5- stage pipeline out of this processor. Overheads associated with pipelining force you to operate the pipelined processor at 2 GHz. In a given program, assume that 30% are memory instructions, 60% are ALU instructions and the rest are branch instructions. 5% of the memory instructions cause stalls of 50 clock cycles each due to cache misses and 50% of the branch instructions cause stalls of 2 cycles each. Assume that there are no stalls associated with the execution of ALU instructions. For this program, the speedup achieved by the pipelined processor over the non-pipelined processor (round off to 2 decimal places) is __________ .
Note - This question was Numerical Type.
Question 235
A processor has 64 registers and uses 16-bit instruction format. It has two types of instructions: I-type and R-type. Each I-type instruction contains an opcode, a register name, and a 4-bit immediate value. Each R-type instruction contains an opcode and two register names. If there are 8 distinct I-type opcodes, then the maximum number of distinct R-type opcodes is _______ .
Note - This question was Numerical Type.
Question 236
Consider the following instruction sequence where registers R1,R2 and R3 are general purpose and MEMORY[X] denotes the content at the memory location X.
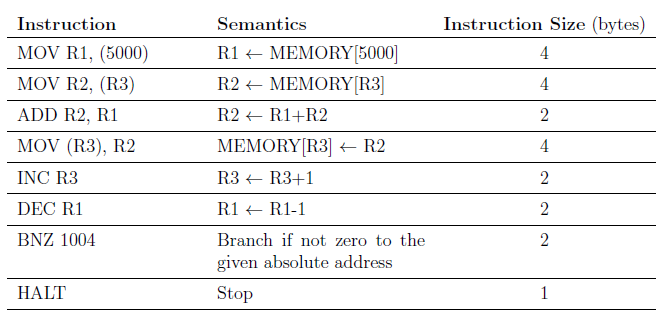 Assume that the content of the memory location 5000 is 10, and the content of the register R3 is 3000. The content of each of the memory locations from 3000 to 3010 is 50. The instruction sequence starts from the memory location 1000. All the numbers are in decimal format. Assume that the memory is byte addressable.
After the execution of the program, the content of memory location 3010 is ____________ .
Assume that the content of the memory location 5000 is 10, and the content of the register R3 is 3000. The content of each of the memory locations from 3000 to 3010 is 50. The instruction sequence starts from the memory location 1000. All the numbers are in decimal format. Assume that the memory is byte addressable.
After the execution of the program, the content of memory location 3010 is ____________ .
Assume that the content of the memory location 5000 is 10, and the content of the register R3 is 3000. The content of each of the memory locations from 3000 to 3010 is 50. The instruction sequence starts from the memory location 1000. All the numbers are in decimal format. Assume that the memory is byte addressable.
After the execution of the program, the content of memory location 3010 is ____________ .Question 237
Answer the following:
a. Draw the schematic of an 8085 based system that can be used to measure the width of a pulse. Assume that the pulse is given as a TTL compatible signal by the source which generates it.
b. Write the 8085 Assembly Language program to measure the width of the pulse. State all your assumption clearly.
Question 238
Assume a two-level inclusive cache hierarchy, L1 and L2, where L2 is the larger of the two. Consider the following statements.
- S1: Read misses in a write through L1 cache do not result in writebacks of dirty lines to the L2
- S2: Write allocate policy must be used in conjunction with write through caches and no-write allocate policy is used with writeback caches.
Question 239
Which one of the following facilitates the transfer of bulk data from hard disk to main memory with the highest throughput?
Question 240
A processor X1 operating at 2 GHz has a standard 5-stage RISC instruction pipeline having a base CPI (cycles per instruction) of one without any pipeline hazards. For a given program P that has 30% branch instructions, control hazards incur 2 cycles stall for every branch. A new version of the processor X2 operating at same clock frequency has an additional branch predictor unit (BPU) that completely eliminates stalls for correctly predicted branches. There is neither any savings nor any additional stalls for wrong predictions. There are no structural hazards and data hazards for X1 and X2. If the BPU has a prediction accuracy of 80%, the speed up (rounded off to two decimal places) obtained by X2 over X1 in executing P is____________.
There are 241 questions to complete.
Last Updated :
Take a part in the ongoing discussion