ER and Relational Models
Question 1
Consider the following relational schema.

Students(rollno: integer, sname: string)
Courses(courseno: integer, cname: string)
Registration(rollno: integer, courseno: integer, percent: real)
Which of the following queries are equivalent to this query in English?
"Find the distinct names of all students who score
more than 90% in the course numbered 107"

Question 3
Suppose (A, B) and (C,D) are two relation schemas. Let r1 and r2 be the corresponding relation instances. B is a foreign key that refers to C in r2. If data in r1 and r2 satisfy referential integrity constraints, which of the following is ALWAYS TRUE?
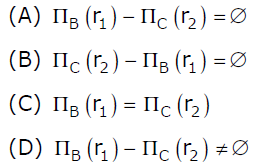

Question 4
Consider the following relations A, B, C. How many tuples does the result of the following relational algebra expression contain? Assume that the schema of A U B is the same as that of A.
[caption width="800"]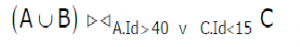 [/caption]
[/caption]Table A Id Name Age ---------------- 12 Arun 60 15 Shreya 24 99 Rohit 11 Table B Id Name Age ---------------- 15 Shreya 24 25 Hari 40 98 Rohit 20 99 Rohit 11 Table C Id Phone Area ----------------- 10 2200 02 99 2100 01
Question 5
Consider a relational table r with sufficient number of records, having attributes A1, A2,…, An and let 1 <= p <= n. Two queries Q1 and Q2 are given below.
 The database can be configured to do ordered indexing on Ap or hashing on Ap. Which of the following statements is TRUE?
The database can be configured to do ordered indexing on Ap or hashing on Ap. Which of the following statements is TRUE?
Question 6
Which of the following tuple relational calculus expression(s) is/are equivalent to 
Question 7
1) Let R and S be two relations with the following schema
R (P,Q,R1,R2,R3)
S (P,Q,S1,S2)
Where {P, Q} is the key for both schemas. Which of the following queries are equivalent?

Question 8
Consider the following ER diagram.
 The minimum number of tables needed to represent M, N, P, R1, R2 is
The minimum number of tables needed to represent M, N, P, R1, R2 is
The minimum number of tables needed to represent M, N, P, R1, R2 isQuestion 9
Consider the data given in above question. Which of the following is a correct attribute set for one of the tables for the correct answer to the above question?
Question 10
Information about a collection of students is given by the relation studinfo(studId, name, sex). The relation enroll(studId, courseId) gives which student has enrolled for (or taken) that course(s). Assume that every course is taken by at least one male and at least one female student. What does the following relational algebra expression represent? 
There are 74 questions to complete.
Last Updated :
Take a part in the ongoing discussion