GATE CS 2008
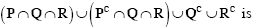
Question 3
The following system of equations
[caption width="800"]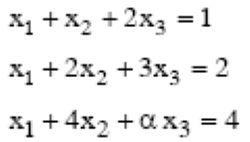 [/caption]
[/caption]
has a unique solution. The only possible value(s) for α is/are
Question 4
In the IEEE floating point representation, the hexadecimal value 0 × 00000000 corresponds to
Question 5
Let r denote number system radix. The only value(s) of r that satisfy the equation 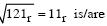
Question 6
In the Karnaugh map shown below, X denotes a don\'t care term. What is the minimal form of the function represented by the Karnaugh map?
A) B) C) D)
Question 7
Given f1, f3 and f in canonical sum of products form (in decimal) for the circuit
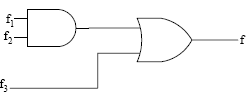
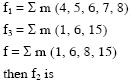


A)m(4, 6) B)
Question 9
Which of the following are decidable?
I. Whether the intersection of two regular languages is infinite II. Whether a given context-free language is regular III. Whether two push-down automata accept the same language IV. Whether a given grammar is context-free
Question 10
Which of the following describes a handle (as applicable to LR-parsing) appropriately?
There are 85 questions to complete.
Last Updated :
Take a part in the ongoing discussion