When to use DFS or BFS to solve a Graph problem?
Last Updated :
24 Aug, 2022
Generally, when we come across a graph problem, we might need to traverse the structure of the given graph or tree to find our solution to the problem. Our problem might be :
- To search for a particular node in the graph.
- To find the shortest distance from a node to any other node or to every other node.
- To count all the nodes.
- Or there can be more complex tasks we need to perform in the way problem defines us to do it.
But one thing is for sure we need to traverse the graph. Two very famous methods of traversing the graph/tree are Breadth-first-search (BFS) and Depth-first-search (DFS) algorithms.
The main difference between these two methods is the way of exploring nodes during our traversal-
- BFS: Tries to explore all the neighbors it can reach from the current node. It will use a queue data structure.
- DFS: Tries to reach the farthest node from the current node and come back (backtrack) to the current node to explore its other neighbors. This will use a stack data structure.
Deciding what to use, BFS or DFS?
Most of the problems can be solved using either BFS or DFS. It won’t make much difference. For example, consider a very simple example where we need to count the total number of cities connected to each other. Where in a graph nodes represent cities and edges represent roads between cities.
In such a problem, we know that we need to go to every node in order to count the nodes. So it doesn’t matter if we use BFS or DFS as using any of the ways we will be traversing all the edges and nodes of a graph. So anyway time complexity will be O(E+V) where E is the total number of edges and V is the total number of nodes.
But there are problems when we need to decide to either use DFS or BFS for a faster solution. And there is no generalization. It completely depends on the problem definition. It depends on what we are trying to find in the solution. We need to understand clearly what our problem wants us to find. And the problem might not directly tell us to use BFS or DFS.
Let’s see a few examples for better clarity.
Examples of choosing DFS over BFS.
Example 1:
Consider a problem where you are standing at your house and you have multiple ways to go from your house to a grocery store. You are said that every path you choose has one store and is located at the end of every path. You just need to reach any of the stores.
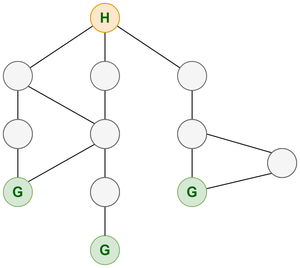
Representation showing path from room to grocery store
The obvious method here will be to choose DFS.
As we know we can find our solution (grocery store) in any of the paths, we can just go on traversing to any neighbor of the current node without exploring all the neighbors. There is no need of going through BFS as it will unnecessarily explore other paths but we can find our solution by traversing any of the paths. Also, we know that our solution is situated farthest from the starting point so if we choose BFS then we will have to almost visit all the nodes as we are visiting all nodes of a level and we will keep doing it till the end where we find a grocery store.
Example 2:
Consider a problem where you need to print all the nodes encountered in any one of the paths starting from node A to node B in the diagram.
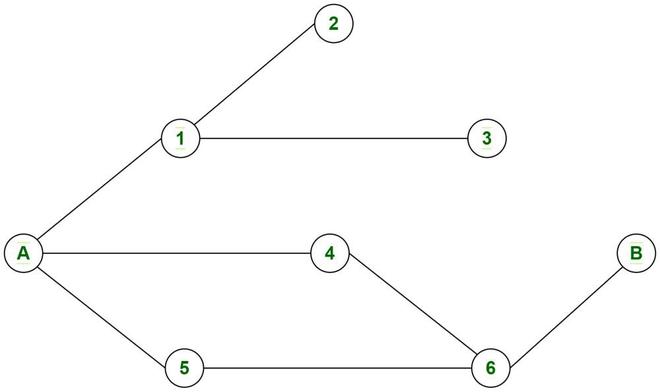
A graph
Here there are two possible paths “A -> 4 -> 6 -> B” and “A -> 5 -> 6 -> B”. Here we require to keep track of a single path so there is no need of exploring every other path using BFS. Also, not every path will lead us from A to B. So we need to backtrack to the current node and then explore another path and see if that leads us to B. Need for backtracking tells us that we can think in the DFS direction.
Examples of choosing BFS over DFS.
Example 1:
Consider an example of a graph representing connected cities through edges. There are a few nodes colored in red that indicates covid affected cities. White-colored nodes indicate healthy cities. You are asked to find out the time the covid virus will take to affect all the non-affected cities if it takes one unit of time to travel from one city to another.
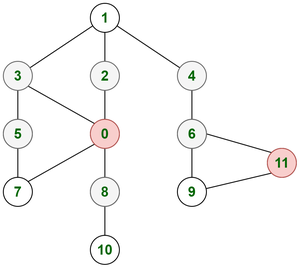
Graph representing above city arrangement
Here thinking of DFS is not even feasible. Here one affected city will affect all of its neighbors in one unit of time. This is how we know that we need to apply BFS as we need to explore all neighbors of the current node first. Another strong reason for BFS here is that both nodes 0 and 11 will start affecting neighbor cities simultaneously. This shows we require a parallel operation on both nodes 0 and 11. So we need to start traversing all the neighbor nodes of both nodes simultaneously. So we can push nodes 0 and 11 in the queue and start traversal parallelly. It will require 2 units of time for all the cities to get affected.
- At time = 0 units, Affected nodes = {0, 11}
- At time = 1 units, Affected nodes = {0, 11, 3, 2, 8, 7, 6, 9}
- At time = 2 units, Affected nodes = {0, 11, 3, 2, 8, 7, 6, 9, 5, 1, 4, 10}
Example 2:
Consider the same example of house and grocery stores mentioned in the above section. Suppose now you need to find the nearest grocery store from the house instead of any grocery store. Consider that each edge is of 1 unit distance. Consider the diagram below:
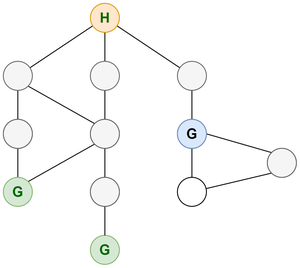
Graph representing grocery store
Here using DFS like previous will not be feasible. If we use DFS then we will travel down a path till we don’t find a grocery store. But once we have found it we are not sure if it is the grocery store at the shortest distance. So we need to backtrack to find a grocery store on other paths and see if any other grocery store has a distance less than the current found grocery store. This will lead us to visit every node in the graph which is not probably the best way to do it.
We can use BFS here as BFS traverses nodes level by level. We first check all the nodes at a 1-unit distance from the house. If any of the nodes is a grocery store then we can stop else we will see the next level i.e all the nodes at a distance 2-unit from the house and so on. This will take less time in most situations as we will not be traversing all the nodes. For the given graph we will only explore nodes up to two levels as at the second level we will find the grocery store and we will return the shortest distance to be 2.
Conclusion:
We can’t have fixed rules for using BFS or DFS. It totally depends on the problem we are trying to solve. But we can make some general intuition.
- We will prefer to use BFS when we know that our solution might lie closer to the starting point or if the graph has greater depths.
- We will prefer to use DFS when we know our solution might lie farthest from the starting point or when the graph has a greater width.
- If we have multiple starting points and the problem requires us to start traversing all those starting points parallelly then we can think of BFS as we can push all those starting points in the queue and start exploring them first.
- It’s generally a good idea to use BFS if we need to find the shortest distance from a node in the unweighted graph.
- We will be using DFS mostly in path-finding algorithms to find paths between nodes.
Although usage of BFS or DFS is not only limited to these few problems. You can find more applications and usage of BFS here and DFS here.
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...