What is Schema On Read and Schema On Write in Hadoop?
Last Updated :
04 Nov, 2020
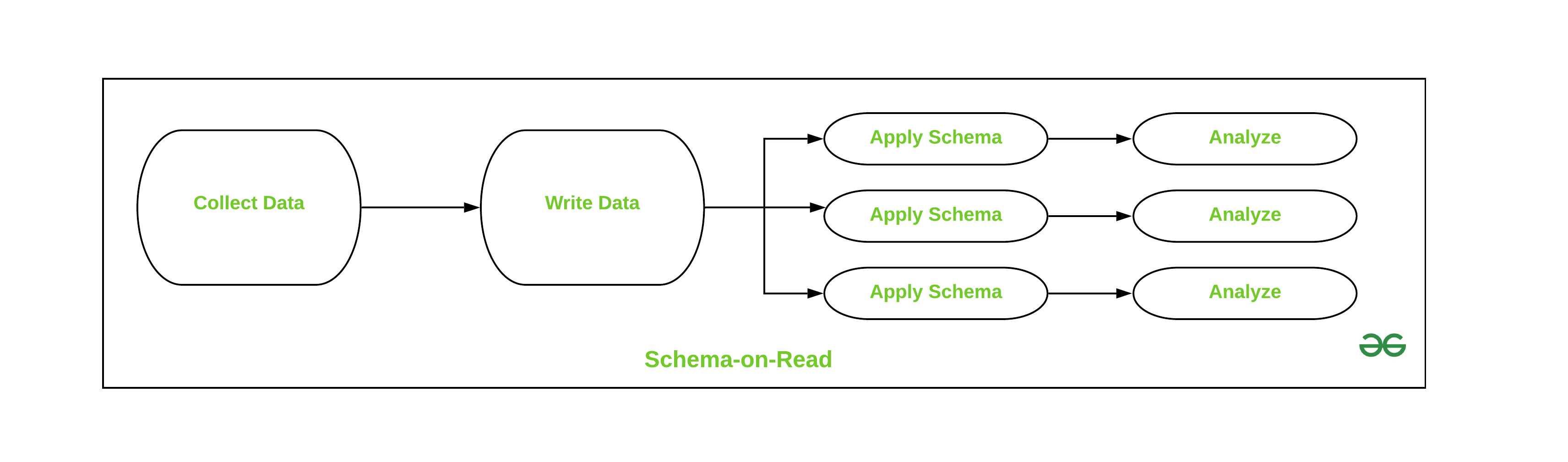
Schema on-Read is the new data investigation approach in new tools like Hadoop and other data-handling technologies. In this schema, the analyst has to identify each set of data which makes it more versatile. This schema is used when the data organization is not the optimal goal but the data collection is a priority. Which makes it easier to create two views on the same data. The use of this Schema made Hadoop technology more popular in today’s business scenarios.
Advantages of using Schema On Read
- This approach provides us the benefit of flexibility of the type of data to be consumed.
- It enhances the data generation speed to the availability of data.
- It provides flexibility to store unstructured, semi-structured, loosely or unorganized data.
Disadvantages of using Schema On Read
- It is required to invest time in creating jobs into schema-on-read.
- It does not allow you to look into the schema and identify what data is present in it.
- It is a little expensive in terms of computing resources are utilized.
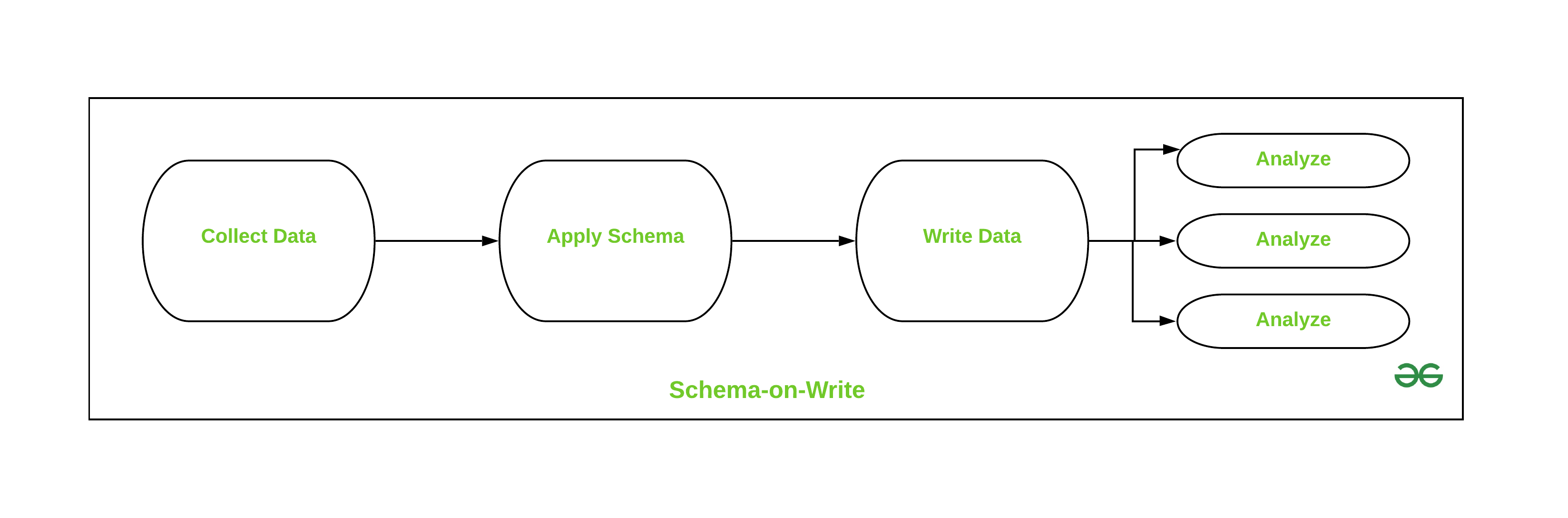
Schema on write is a technique for storing data into databases. This has provided a new way to enhance traditional sophisticated systems. It is a newer way of handling data over Schema-on-Read as it provides flexibility to the businesses in big data and analytics. It provides the user to achieve consistency in the data but is very restrictive to the type of data inserted which makes it rejection to many unstructured types of data. With some alterations with hardware and software, it is easily capable to handle a variety of data.
Advantages of using Schema On Write
- This approach helps to express the relationship between data points.
- As the schema is being described the user/tool can start its work.
- This approach makes you store dense data.
Disadvantages of using Schema On Write
- Schema is to built for specific purposes.
- Schema Requires enough modeling to get it ready for work.
- Semi-structured or unstructured data are not a perfect fit for this approach.
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...