What is Hadoop Streaming?
Last Updated :
03 Jan, 2021
It is a utility or feature that comes with a Hadoop distribution that allows developers or programmers to write the Map-Reduce program using different programming languages like Ruby, Perl, Python, C++, etc. We can use any language that can read from the standard input(STDIN) like keyboard input and all and write using standard output(STDOUT). We all know the Hadoop Framework is completely written in java but programs for Hadoop are not necessarily need to code in Java programming language. feature of Hadoop Streaming is available since Hadoop version 0.14.1.
How Hadoop Streaming Works
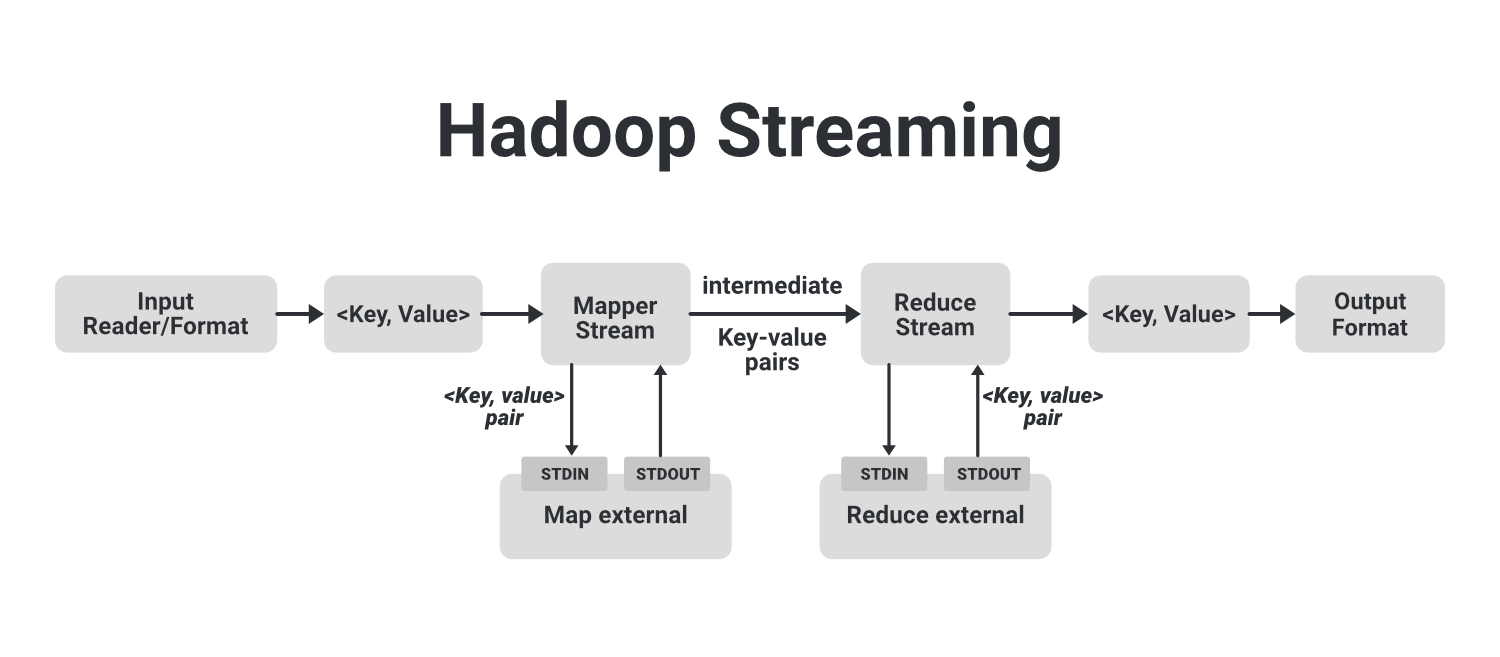
In the above example image, we can see that the flow shown in a dotted block is a basic MapReduce job. In that, we have an Input Reader which is responsible for reading the input data and produces the list of key-value pairs. We can read data in .csv format, in delimiter format, from a database table, image data(.jpg, .png), audio data etc. The only requirement to read all these types of data is that we have to create a particular input format for that data with these input readers. The input reader contains the complete logic about the data it is reading. Suppose we want to read an image then we have to specify the logic in the input reader so that it can read that image data and finally it will generate key-value pairs for that image data.
If we are reading an image data then we can generate key-value pair for each pixel where the key will be the location of the pixel and the value will be its color value from (0-255) for a colored image. Now this list of key-value pairs is fed to the Map phase and Mapper will work on each of these key-value pair of each pixel and generate some intermediate key-value pairs which are then fed to the Reducer after doing shuffling and sorting then the final output produced by the reducer will be written to the HDFS. These are how a simple Map-Reduce job works.
Now let’s see how we can use different languages like Python, C++, Ruby with Hadoop for execution. We can run this arbitrary language by running them as a separate process. For that, we will create our external mapper and run it as an external separate process. These external map processes are not part of the basic MapReduce flow. This external mapper will take input from STDIN and produce output to STDOUT. As the key-value pairs are passed to the internal mapper the internal mapper process will send these key-value pairs to the external mapper where we have written our code in some other language like with python with help of STDIN. Now, these external mappers process these key-value pairs and generate intermediate key-value pairs with help of STDOUT and send it to the internal mappers.
Similarly, Reducer does the same thing. Once the intermediate key-value pairs are processed through the shuffle and sorting process they are fed to the internal reducer which will send these pairs to external reducer process that are working separately through the help of STDIN and gathers the output generated by external reducers with help of STDOUT and finally the output is stored to our HDFS.
This is how Hadoop Streaming works on Hadoop which is by default available in Hadoop. We are just utilizing this feature by making our external mapper and reducers. Now we can see how powerful feature is Hadoop streaming. Anyone can write his code in any language of his own choice.
Some Hadoop Streaming Commands
|
Option
|
Description
|
| -input directory_name or filename |
Input location for the mapper. |
| -output directory_name |
Input location for the reducer. |
| -mapper executable or JavaClassName |
The command to be run as the mapper |
| -reducer executable or script or JavaClassName |
The command to be run as the reducer |
| -file file-name |
Make the mapper, reducer, or combiner executable available locally on the compute nodes |
| -inputformat JavaClassName |
By default, TextInputformat is used to return the key-value pair of Text class. We can specify our class but that should also return a key-value pair. |
| -outputformat JavaClassName |
By default, TextOutputformat is used to take key-value pairs of Text class. We can specify our class but that should also take a key-value pair. |
| -partitioner JavaClassName |
The Class that determines which key to reduce. |
| -combiner streamingCommand or JavaClassName |
The Combiner executable for map output |
| -verbose |
The Verbose output. |
| -numReduceTasks |
It Specifies the number of reducers. |
| -mapdebug |
Script to call when map task fails |
| -reducedebug |
Script to call when reduce task fails |
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...