What is Apache Kafka Streams?
Last Updated :
02 Feb, 2023
Kafka Streams is a library for processing and analyzing data stored in Kafka. It expands on crucial stream processing ideas such as clearly separating event time from processing time, allowing for windows, and managing and querying application information simply but effectively in real time. Kafka Streams has a low entry barrier since it is easy to create and operate a small-scale proof-of-concept on a single system. To scale up to high-volume production workloads, you merely need to run extra instances of your application on numerous machines. By utilizing Kafka’s parallelism paradigm, Kafka Streams transparently manages the load balancing of numerous instances of the same application.
Kafka Streams Architecture

Kafka Streams Architecture
Features of Kafka Streams
- Crafted to be a straightforward and lightweight client library that is simple to embed in any Java program and to work with any current packaging, deployment, and operational tools that customers may already have for their streaming applications.
- Uses Apache Kafka as the internal messaging layer and has no external dependencies on any other systems; in particular, it employs Kafka’s partitioning mechanism to horizontally scale processing while preserving strong ordering guarantees.
- Supports fault-tolerant local state, which makes stateful operations like windowed joins and aggregations incredibly quick and effective.
- Supports exactly-once processing semantics, which ensures that each record will only be processed once, even if Streams clients or Kafka brokers fail in the middle of the processing process.
- Achieves millisecond processing latency by using one record at a time processing. It also allows event-time-based windowing activities with data arriving out of sequence.
- Provides the essential stream processing primitives, a high-level Streams DSL, and both a low-level and a high-level Processor API.
Topologies
The flow of stream processing is represented by topologies, which are directed acyclic graphs, in Kafka Streams (“DAGs”).
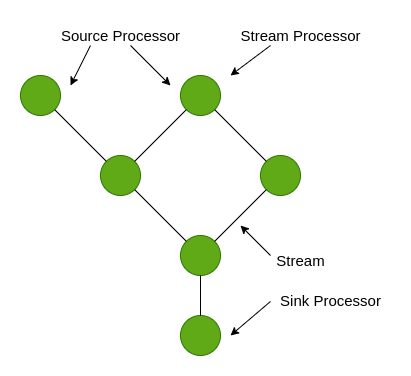
Kafka Streams Topology
- Stream: The most significant abstraction offered by Kafka Streams is a stream, which stands for an unbounded data set that is constantly changing. A data record is defined as a key-value pair, and a stream is an ordered, replayable, and fault-tolerant sequence of immutable data records.
- Stream Processor: A node in the processor topology known as a stream processor provides a processing step to convert data in streams by receiving one input record at a time from its upstream processors in the topology, processing it, and perhaps producing one or more output records for its downstream processors.
- Source Processor: A unique type of stream processor called a source processor doesn’t have any upstream processors. It consumes records from one or more Kafka topics and sends them to its downstream processors, producing an input stream to its topology from these topics.
- Sink Processor: A unique kind of stream processor called a sink processor lacks downstream processors. Any records it receives from its upstream processors are sent to a particular Kafka topic.
Duality of Streams and Tables
A table is a collection of key-value pairs.
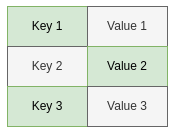
Table
- Stream as Table: Each data record in a stream can be thought of as a changelog for a database, recording each time the state of the table has changed. Thus, a stream is a table in disguise, and it is simple to transform a stream into a “true” table simply replaying the changelog to create the table from scratch. A table will be produced if data records from a stream are aggregated. As an illustration, we could determine the total number of pageviews by the user from a stream of pageview events input. The output would be a table, with the user as the key and the matching pageview count as the value.
- Table as Stream: A stream’s data records are key-value pairs, therefore a table may be thought of as a snapshot of the most recent value for each key at a particular point in time. Thus, a table is actually a stream in disguise, and it is simple to transform it into a “true” stream by repeatedly iterating over each key-value entry.
Here, a changelog stream can be used to depict how the status of the table changes between various points in time and different revisions (second column).
The original table can be recreated using the same stream because of the stream-table duality (third column).
Conclusion
Kafka Streams provide millisecond-level processing latency and are elastic, highly scalable, and fault-tolerant. Regardless of whether it runs on a VM, cloud, container, or on-premises, it functions precisely the same. Linux, Mac, and Windows are all supported systems. With so many advantages, its reach has grown in recent years.
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...