Web Scraping using R Language
Last Updated :
17 Feb, 2023
One of the most important things in the field of Data Science is the skill of getting the right data for the problem you want to solve. Data Scientists don’t always have a prepared database to work on but rather have to pull data from the right sources. For this purpose, APIs and Web Scraping are used.
- API (Application Program Interface): An API is a set of methods and tools that allows one to query and retrieve data dynamically. Reddit, Spotify, Twitter, Facebook, and many other companies provide free APIs that enable developers to access the information they store on their servers; others charge for access to their APIs.
- Web Scraping: A lot of data isn’t accessible through data sets or APIs but rather exists on the internet as Web pages. So, through web scraping, one can access the data without waiting for the provider to create an API.
What’s Web Scraping?
Web scraping is a technique to fetch data from websites. While surfing on the web, many websites don’t allow the user to save data for private use. One way is to manually copy-paste the data, which is both tedious and time-consuming. Web Scraping is the automatic process of data extraction from websites. This process is done with the help of web scraping software known as web scrapers. They automatically load and extract data from the websites based on user requirements. These can be custom-built to work for one site or can be configured to work with any website.
Web scraping real-life example
A common real-life example of web scraping is a price comparison website that aggregates product prices from multiple online retailers and displays them to the user. The website uses web scraping to extract the latest prices and product information from the retailers’ websites and store it in its own database. This enables users to compare prices and make informed purchasing decisions.
Consider a scenario where a real estate company wants to gather information on properties listed for sale in a certain area. The company can use web scraping to extract data such as property type, price, location, square footage, and number of bedrooms and bathrooms from popular real estate websites like Zillow and Redfin.
The company can then use this data to create a comprehensive database of properties for sale in the area, which can be used for various purposes such as market analysis, determining fair market value for potential clients, and identifying trends and patterns in the local real estate market.
Once the data is collected and stored, the company can also use it to generate custom reports and visualizations, such as graphs and maps that show the distribution of properties by price, location, and other relevant factors. This can provide valuable insights into the real estate market, which can be used to make informed business decisions and provide better services to clients.
Implementation of Web Scraping using R
There are several web scraping tools out there to perform the task and various languages too, have libraries that support web scraping. Among all these languages, R is considered as one of the programming languages for Web Scraping because of features like – a rich library, ease to use, dynamically typed, etc. The commonly used web Scraping tools for R is rvest.
Install the package rvest in your R Studio using the following code.
install.packages('rvest')
Having, knowledge of HTML and CSS will be an added advantage. It’s observed that most of the Data Scientists are not very familiar with technical knowledge of HTML and CSS. Therefore, let’s use an open-source software named Selector Gadget which will be more than sufficient for anyone in order to perform Web scraping. One can access and download the Selector Gadget extension(https://selectorgadget.com/). Consider that one has this extension installed by following the instructions from the website. Also, consider one using Google chrome and he/she can access the extension in the extension bar to the top right.
Web Scraping in R with rvest
rvest maintained by the legendary Hadley Wickham. We can easily scrape data from webpage from this library.
Import rvest libraries
Before starting we will import the rvest library into your code.
Read HTML Code
Read the HTML code from the webpage using read_html(). Consider this webpage.
R
data-structures-in-r-programming")
|
Scrape Data From HTML Code
Now, let’s start by scraping the heading field. For that, use the selector gadget to get the specific CSS selectors that enclose the heading. One can click on the extension in his/her browser and select the heading field with the cursor.
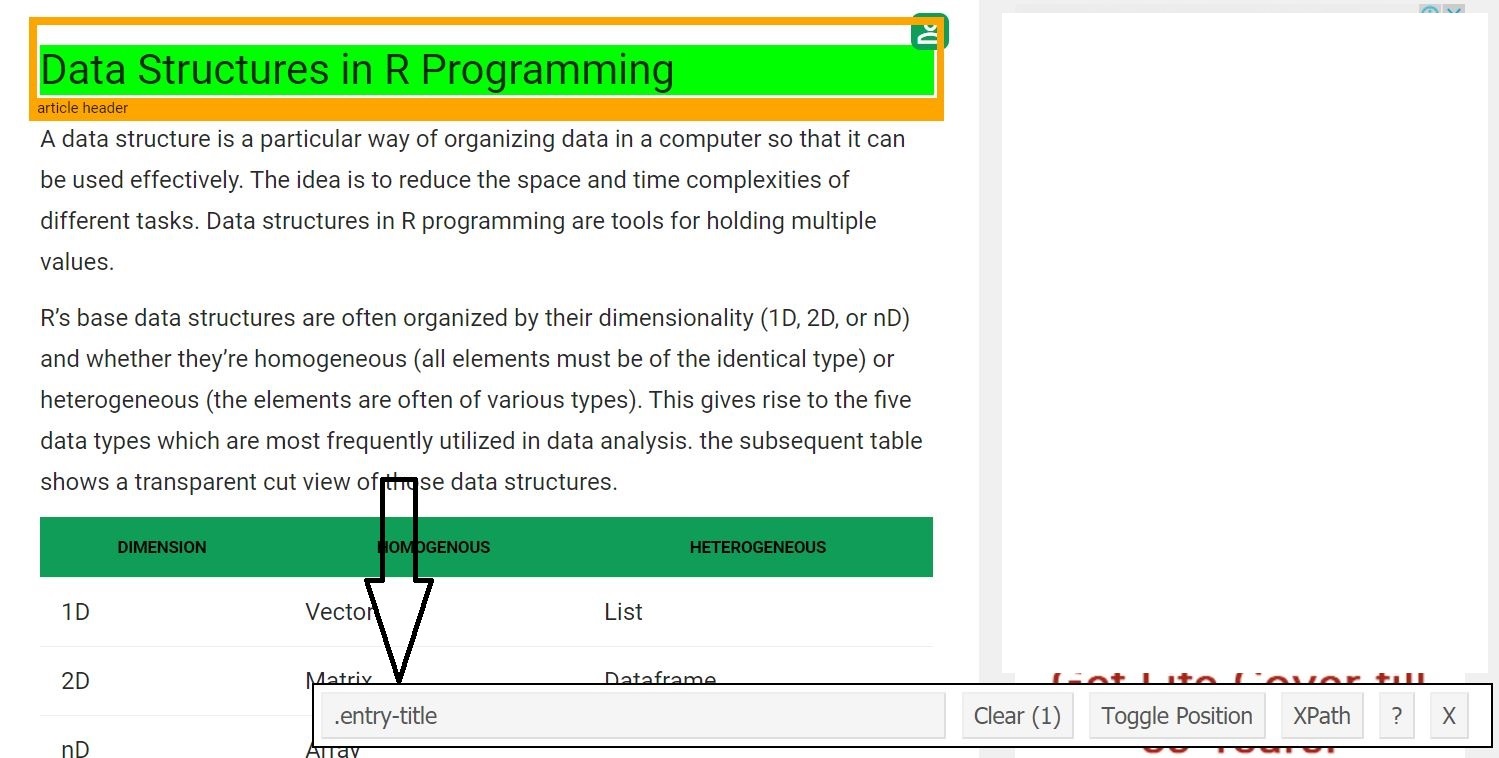
Once one knows the CSS selector that contains the heading, he/she can use this simple R code to get the heading.
R
heading = html_node(webpage, '.entry-title')
text = html_text(heading)
print(text)
|
Output:
[1] "Data Structures in R Programming"
Now, let’s scrape the all paragraph fields. For that did the same procedure as we did before.
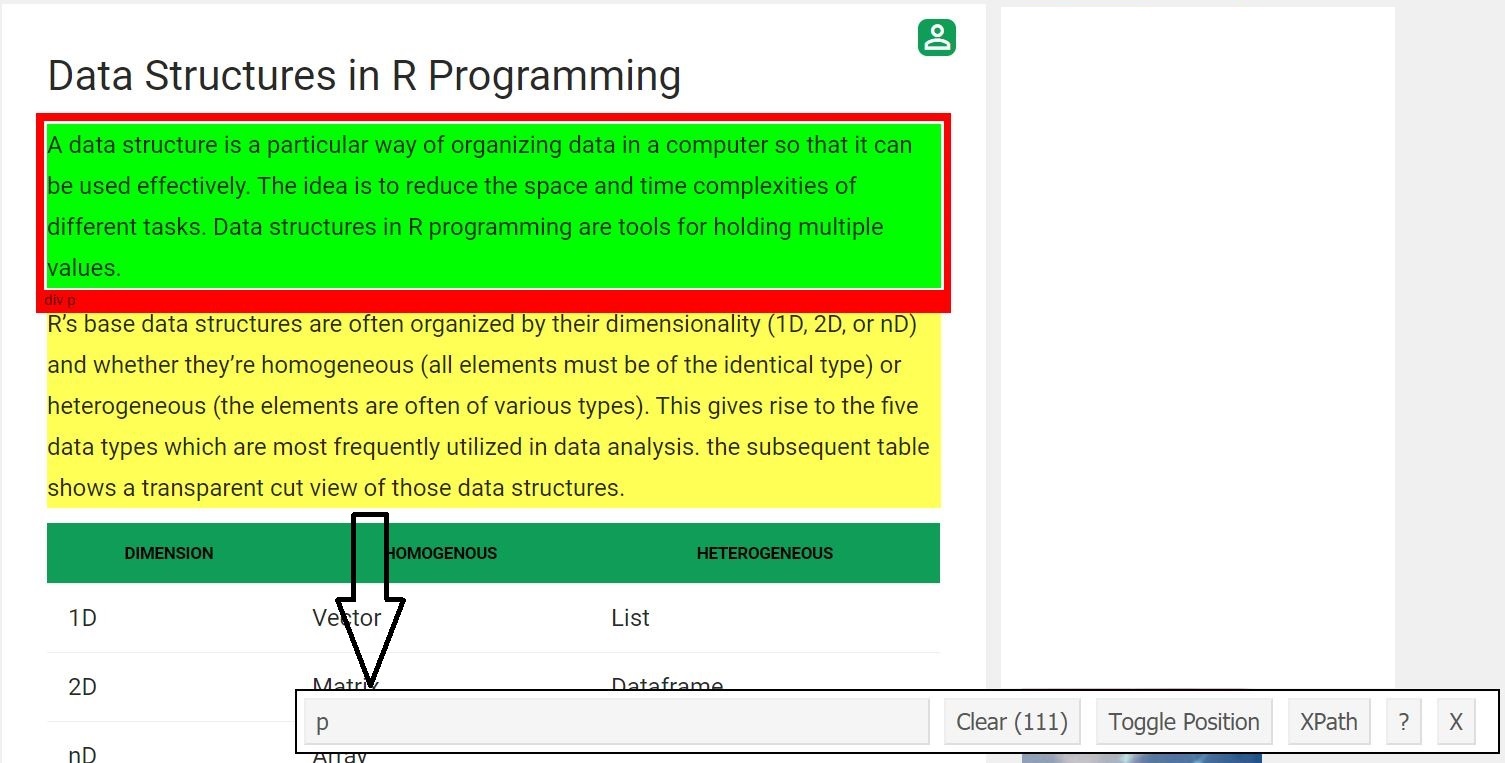
Once one knows the CSS selector that contains the paragraphs, he/she can use this simple R code to get all the paragraphs.
R
paragraph = html_nodes(webpage, 'p')
pText = html_text(paragraph)
print(head(pText))
|
Output:
[1] “A data structure is a particular way of organizing data in a computer so that it can be used effectively. The idea is to reduce the space and time complexities of different tasks. Data structures in R programming are tools for holding multiple values. ”
[2] “R’s base data structures are often organized by their dimensionality (1D, 2D, or nD) and whether they’re homogeneous (all elements must be of the identical type) or heterogeneous (the elements are often of various types). This gives rise to the five data types which are most frequently utilized in data analysis. the subsequent table shows a transparent cut view of those data structures.”
[3] “The most essential data structures used in R include:”
[4] “”
[5] “A vector is an ordered collection of basic data types of a given length. The only key thing here is all the elements of a vector must be of the identical data type e.g homogeneous data structures. Vectors are one-dimensional data structures.”
[6] “Example:”
The complete code for Web Scraping using R Language
R
library(rvest)
data-structures-in-r-programming")
heading = html_node(webpage, '.entry-title')
text = html_text(heading)
print(text)
paragraph = html_nodes(webpage, 'p')
pText = html_text(paragraph)
print(head(pText))
|
Output:
[1] “Data Structures in R Programming”
[1] “A data structure is a particular way of organizing data in a computer so that it can be used effectively. The idea is to reduce the space and time complexities of different tasks. Data structures in R programming are tools for holding multiple values. ” [2] “R’s base data structures are often organized by their dimensionality (1D, 2D, or nD) and whether they’re homogeneous (all elements must be of the identical type) or heterogeneous (the elements are often of various types). This gives rise to the five data types which are most frequently utilized in data analysis. the subsequent table shows a transparent cut view of those data structures.” [3] “The most essential data structures used in R include:” [4] “” [5] “A vector is an ordered collection of basic data types of a given length. The only key thing here is all the elements of a vector must be of the identical data type e.g homogeneous data structures. Vectors are one-dimensional data structures.” [6] “Example:”
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...