Web scraping from Wikipedia using Python – A Complete Guide
Last Updated :
09 Jan, 2023
In this article, you will learn various concepts of web scraping and get comfortable with scraping various types of websites and their data. The goal is to scrape data from the Wikipedia Home page and parse it through various web scraping techniques. You will be getting familiar with various web scraping techniques, python modules for web scraping, and processes of Data extraction and data processing. Web scraping is an automatic process of extracting information from the web. This article will give you an in-depth idea of web scraping, its comparison with web crawling, and why you should opt for web scraping.
Introduction to Web scraping and Python
It is basically a technique or a process in which large amounts of data from a huge number of websites is passed through a web scraping software coded in a programming language and as a result, structured data is extracted which can be saved locally in our devices preferably in Excel sheets, JSON or spreadsheets. Now, we don’t have to manually copy and paste data from websites but a scraper can perform that task for us in a couple of seconds.
Web scraping is also known as Screen Scraping, Web Data Extraction, Web Harvesting, etc.
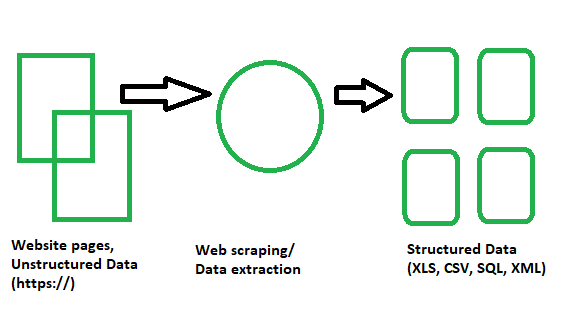
Process of Web scraping
This helps programmers write clear, logical code for small and large-scale projects. Python is mostly known as the best web scraper language. It’s more like an all-rounder and can handle most of the web crawling related processes smoothly. Scrapy and Beautiful Soup are among the widely used frameworks based on Python that makes scraping using this language such an easy route to take.
A brief list of Python libraries used for web scraping
Let’s see the web scraping libraries in Python!
- Requests (HTTP for Humans) Library for Web Scraping – It is used for making various types of HTTP requests like GET, POST, etc. It is the most basic yet the most essential of all libraries.
- lxml Library for Web Scraping – lxml library provides super-fast and high-performance parsing of HTML and XML content from websites. If you are planning to scrape large datasets, this is the one you should go for.
- Beautiful Soup Library for Web Scraping – Its work involves creating a parse tree for parsing content. A perfect starting library for beginners and very easy to work with.
- Selenium Library for Web Scraping – Originally made for automated testing of web applications, this library overcomes the issue all the above libraries face i.e. scraping content from dynamically populated websites. This makes it slower and not suitable for industry-level projects.
- Scrapy for Web Scraping – The BOSS of all libraries, an entire web scraping framework which is asynchronous in its usage. This makes it blazing fast and increases efficiency.
Practical Implementation – Scraping Wikipedia

Steps of web scraping
Step 1: How to use python for web scraping?
- We need python IDE and should be familiar with the use of it.
- Virtualenv is a tool to create isolated Python environments. With the help of virtualenv, we can create a folder that contains all necessary executables to use the packages that our Python project requires. Here we can add and modify python modules without affecting any global installation.
- We need to install various Python modules and libraries using the pip command for our purpose. But, we should always keep in mind that whether the website we are scraping is legal or not.
Requirements:
- Requests: It is an efficient HTTP library used for accessing web pages.
- Urlib3: It is used for retrieving data from URLs.
- Selenium: It is an open-source automated testing suite for web applications across different browsers and platforms.
Installation:
pip install virtualenv
python -m pip install selenium
python -m pip install requests
python -m pip install urllib3

Sample image during installing
Step 2: Introduction to Requests library
- Here, we will learn various python modules to fetch data from the web.
- The python requests library is used to make download the webpage we are trying to scrape.
Requirements:
- Python IDE
- Python Modules
- Requests library
Code Walk-Through:
URL: https://en.wikipedia.org/wiki/Main_Page
Python3
import requests
print(page.status_code)
print(page.content)
|
Output:
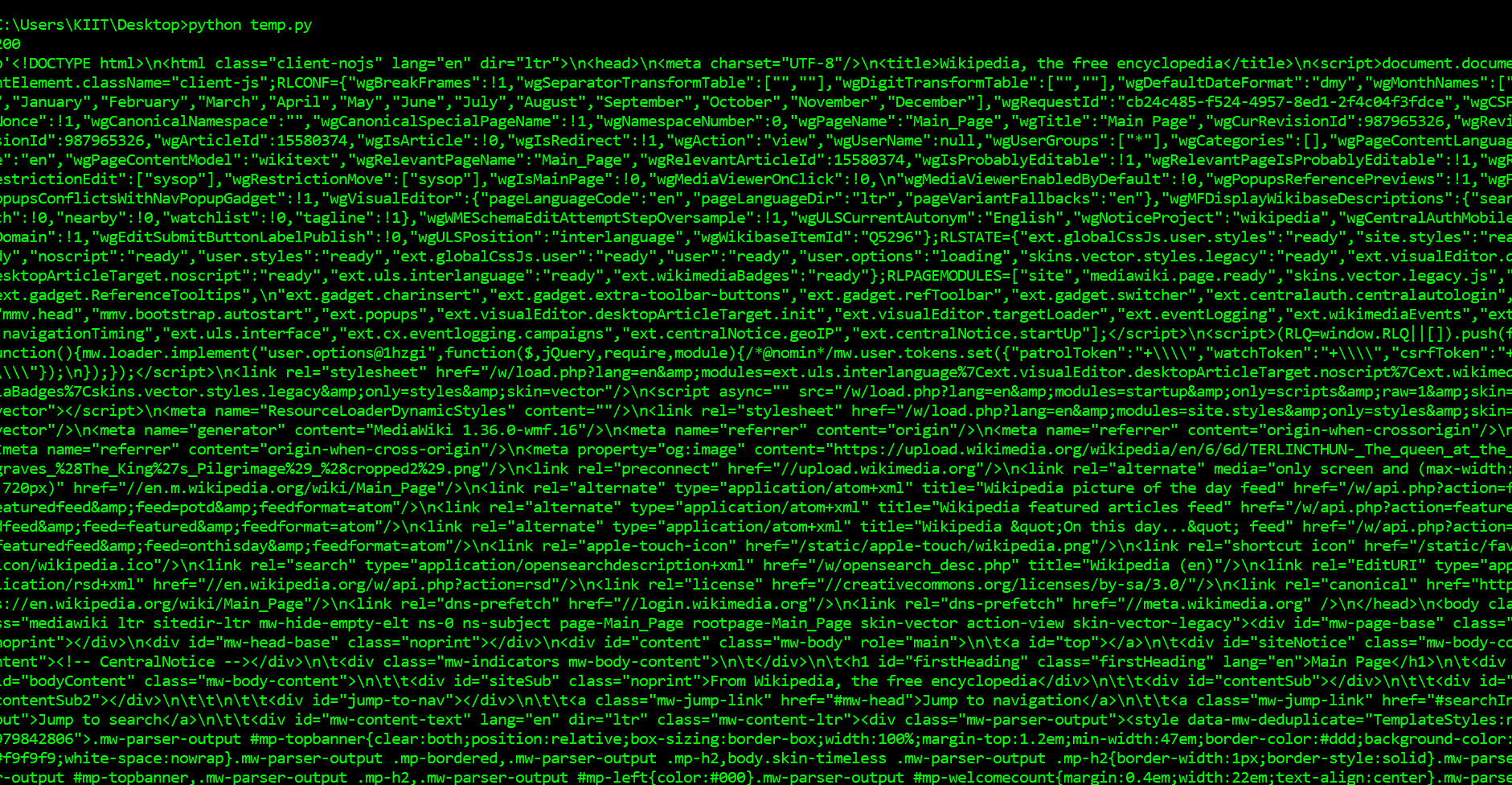
The first thing we’ll need to do to scrape a web page is to download the page. We can download pages using the Python requests library. The requests library will make a GET request to a web server, which will download the HTML contents of a given web page for us. There are several types of requests we can make using requests, of which GET is just one. The URL of our sample website is https://en.wikipedia.org/wiki/Main_Page. The task is to download it using requests.get() method. After running our request, we get a Response object. This object has a status_code property, which indicates if the page was downloaded successfully. And a content property that gives the HTML content of the webpage as output.
Step 3: Introduction to Beautiful Soup for page parsing
We have a lot of python modules for data extraction. We are going to use BeautifulSoup for our purpose.
- BeautifulSoup is a Python library for pulling data out of HTML and XML files.
- It needs an input (document or URL) to create a soup object as it cannot fetch a web page by itself.
- We have other modules such as regular expression, lxml for the same purpose.
- We then process the data in CSV or JSON or MySQL format.
Requirements:
- PythonIDE
- Python Modules
- Beautiful Soup library
pip install bs4
Code Walk-Through:
Python3
from bs4 import BeautifulSoup
import requests
soup = BeautifulSoup(page.content, 'html.parser')
print(soup.prettify())
|
Output:
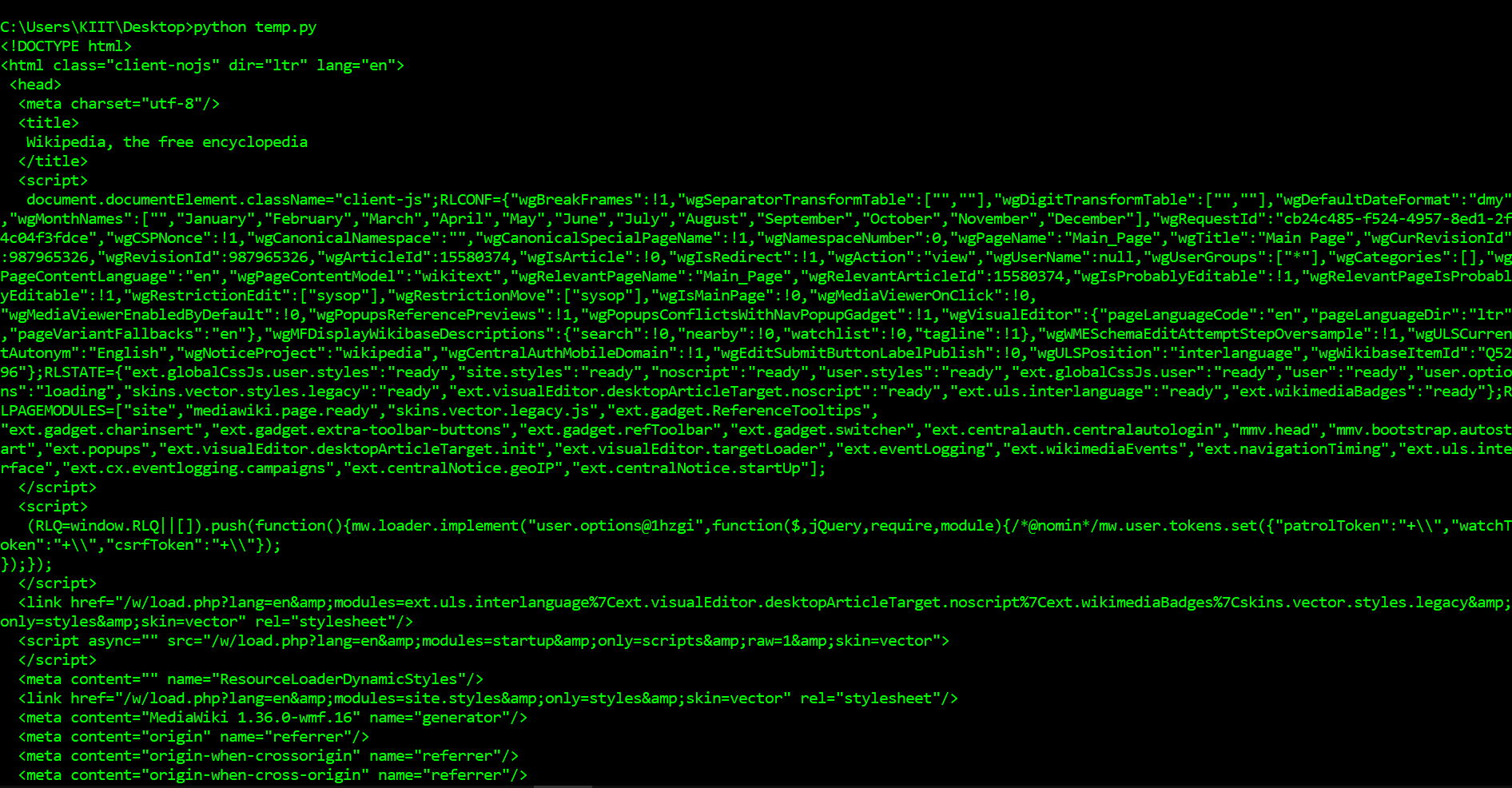
As you can see above, we now have downloaded an HTML document. We can use the BeautifulSoup library to parse this document and extract the text from the p tag. We first have to import the library and create an instance of the BeautifulSoup class to parse our document. We can now print out the HTML content of the page, formatted nicely, using the prettify method on the BeautifulSoup object. As all the tags are nested, we can move through the structure one level at a time. We can first select all the elements at the top level of the page using the children’s property of soup. Note that children return a list generator, so we need to call the list function on it.
Step 4: Digging deep into Beautiful Soup further
Three features that make Beautiful Soup so powerful:
- Beautiful Soup provides a few simple methods and Pythonic idioms for navigating, searching, and modifying a parse tree: a toolkit for dissecting a document and extracting what you need. It doesn’t take much code to write an application
- Beautiful Soup automatically converts incoming documents to Unicode and outgoing documents to UTF-8. You don’t have to think about encodings unless the document doesn’t specify an encoding and Beautiful Soup can’t detect one. Then you just have to specify the original encoding.
- Beautiful Soup sits on top of popular Python parsers like lxml and html5lib, allowing you to try out different parsing strategies or trade speed for flexibility. Then we have to just process our data in a proper format such as CSV or JSON or MySQL.
Requirements:
- PythonIDE
- Python Modules
- Beautiful Soup library
Code Walk-Through:
Python3
from bs4 import BeautifulSoup
import requests
soup = BeautifulSoup(page.content, 'html.parser')
list(soup.children)
print(soup.find_all('p'))
print('\n\n')
print(soup.find_all('p')[0].get_text())
|
Output:

What we did above was useful for figuring out how to navigate a page, but it took a lot of commands to do something fairly simple. If we want to extract a single tag, we can instead use the find_all() method, which will find all the instances of a tag on a page. Note that find_all() returns a list, so we’ll have to loop through, or use list indexing, to extract text. If you instead only want to find the first instance of a tag, you can use the find method, which will return a single BeautifulSoup object.
Step 5: Exploring page structure with Chrome Dev tools and extracting information
The first thing we’ll need to do is inspect the page using Chrome Devtools. If you’re using another browser, Firefox and Safari have equivalents. It’s recommended to use Chrome though.
You can start the developer tools in Chrome by clicking View -> Developer -> Developer Tools. You should end up with a panel at the bottom of the browser like what you see below. Make sure the Elements panel is highlighted. The elements panel will show you all the HTML tags on the page, and let you navigate through them. It’s a really handy feature! By right-clicking on the page near where it says Extended Forecast, then clicking Inspect, we’ll open up the tag that contains the text Extended Forecast in the elements panel.

Analyzing by Chrome Dev tools
Code Walk-Through:
Python3
from bs4 import BeautifulSoup
import requests
soup = BeautifulSoup(page.content, 'html.parser')
object = soup.find(id="mp-left")
items = object.find_all(class_="mp-h2")
result = items[0]
print(result.prettify())
|
Output:

Here we have to select that element that has an id to it and contains children having the same class. For example, the element with id mp-left is the parent element and its nested children have the class mp-h2. So we will print the information with the first nested child and prettify it using the prettify() function.
Conclusion and Digging deeper into Web scraping
We learned various concepts of web scraping and scraped data from the Wikipedia Home page and parsed it through various web scraping techniques. The article helped us in getting an in-depth idea of web scraping, its comparison with web crawling, and why you should opt for web scraping. We also learned about the components and working of a web scraper.
Although web scraping opens up many doors for ethical purposes, there can be unintended data scraping by unethical practitioners which creates a moral hazard to many companies and organizations where they can retrieve the data easily and use it for their own selfish means. Data-scraping in combination with big data can provide the company’s market intelligence and help them identify critical trends and patterns and identify the best opportunities and solutions. Therefore, it’s quite accurate to predict that Data scraping can be upgraded to the better soon.

Uses of Web scraping
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...