Vector processor classification
Last Updated :
07 Mar, 2024
According to from where the operands are retrieved in a vector processor, pipe lined vector computers are classified into two architectural configurations:
- Memory to memory architecture – In memory to memory architecture, source operands, intermediate and final results are retrieved (read) directly from the main memory. For memory to memory vector instructions, the information of the base address, the offset, the increment, and the vector length must be specified in order to enable streams of data transfers between the main memory and pipelines. The processors like TI-ASC, CDC STAR-100, and Cyber-205 have vector instructions in memory to memory formats. The main points about memory to memory architecture are:
- There is no limitation of size
- Speed is comparatively slow in this architecture
- Register to register architecture – In register to register architecture, operands and results are retrieved indirectly from the main memory through the use of large number of vector registers or scalar registers. The processors like Cray-1 and the Fujitsu VP-200 use vector instructions in register to register formats. The main points about register to register architecture are:
- Register to register architecture has limited size.
- Speed is very high as compared to the memory to memory architecture.
- The hardware cost is high in this architecture.
A block diagram of a modern multiple pipeline vector computer is shown below:
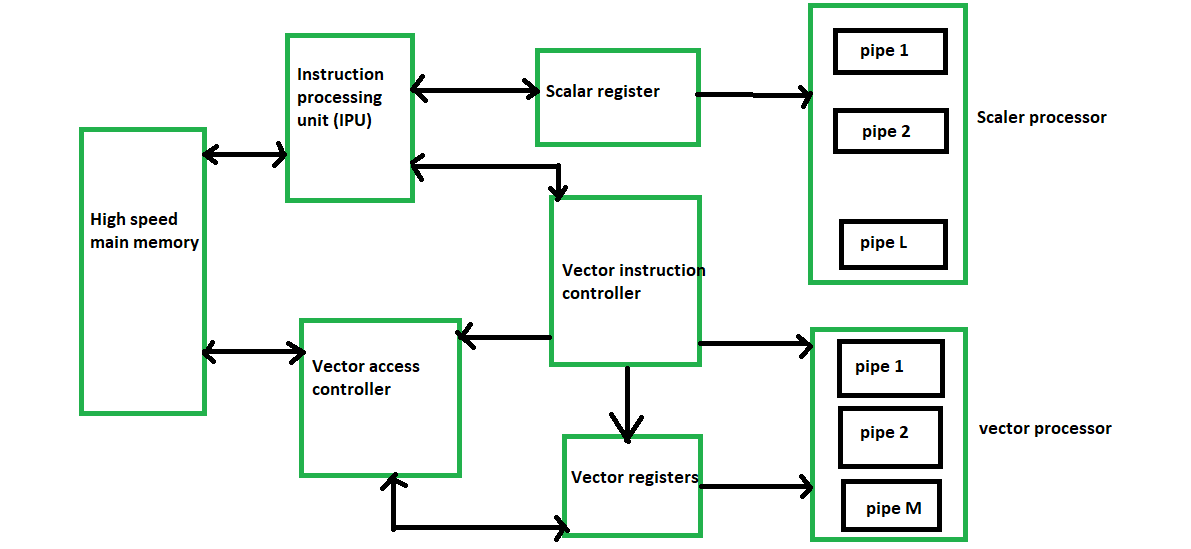
A typical pipe lined vector processor.
Advantages of Vector processor:
1. Parallelism and SIMD Execution: Vector processors are intended to perform Single Guidance, Different Information (SIMD) activities. This implies that a solitary guidance can work on numerous information components in equal, considering a huge speedup in errands that include monotonous procedure on enormous datasets. This parallelism is appropriate for logical recreations, reenactments of actual frameworks, signal handling, and different applications including weighty mathematical calculations.
2. Proficient Information Development: Vector processors are enhanced for moving information productively among memory and the computer chip registers. This is pivotal for execution, as memory access is much of the time a bottleneck in many registering errands. Vector processors commonly incorporate specific information development directions that can move information in huge lumps, limiting the effect of memory dormancy.
3. Diminished Guidance Above: With SIMD tasks, a solitary guidance can play out similar procedure on various information components. This lessens the above related with getting, unraveling, and executing individual directions, which is especially helpful for errands that include tedious computations.
4. Energy Proficiency: By executing procedure on various information components at the same time, vector processors can accomplish higher computational throughput while consuming generally less power contrasted with scalar processors playing out similar activities consecutively. This energy effectiveness is significant for superior execution registering (HPC) applications where power utilization is a worry.
5. Logical and Designing Applications: Vector processors succeed in logical and designing reproductions where complex numerical calculations are performed on huge datasets. Applications like weather conditions displaying, computational liquid elements, atomic elements reproductions, and picture handling can benefit altogether from the computational power and parallelism presented by vector processors.
6. Superior Execution for Cluster Activities: Some true applications include controlling exhibits or grids of information, for example, in information examination, AI, and illustrations handling. Vector processors can perform activities like expansion, increase, and other component wise procedure on whole clusters with a solitary guidance, significantly speeding up these undertakings.
7. Compiler Streamlining: Vector processors frequently expect code to be written with a certain goal in mind to make the most of their capacities. Compiler improvements can naturally change undeniable level code into vectorized guidelines, permitting software engineers to zero in on the algorithmic plan as opposed to low-even out advancements.
8. Memory Transmission capacity Usage: Vector processors can productively use memory transfer speed by streaming information from memory into vector registers and afterward performing calculations on those vectors. This can assist with alleviating the exhibition effect of memory bottlenecks.
9. Vector Length Adaptability: Some vector processors permit adaptability in the length of vector tasks, empowering software engineers to pick the proper vector length in light of the application’s necessities and the accessible equipment assets.
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...