Validation Curve
Last Updated :
29 May, 2023
Model validation is an important part of the data science project since want to select a model which not only performs well on our training dataset but also has good accuracy on the testing dataset. Model validation helps us in finding a model which has low variance.
What is Validation Curve
A Validation Curve is an important diagnostic tool that shows the sensitivity between changes in a Machine Learning model’s accuracy with changes in hyperparameters of the model.
The validation curve plots the model performance metric (such as accuracy, F1-score, or mean squared error) on the y-axis and a range of hyperparameter values on the x-axis. The hyperparameter values of the models are typically varied on a logarithmic scale, and the model is trained and evaluated using a cross-validation technique for each hyperparameter value.
Two curves are present in a validation curve – one for the training set score and one for the cross-validation score. By default, the function for validation curve, present in the scikit-learn library performs 3-fold cross-validation.
A validation curve is used to evaluate an existing model based on hyper-parameters and is not used to tune a model. This is because, if we tune the model according to the validation score, the model may be biased towards the specific data against which the model is tuned; thereby, not being a good estimate of the generalization of the model.
Interpreting a Validation Curve
Interpreting the results of a validation curve can sometimes be tricky. Keep the following points in mind while looking at a validation curve :
- Ideally, we would want both the validation curve and the training curve to look as similar as possible.
- If both scores are low, the model is likely to be underfitting. This means either the model is too simple or it is informed by too few features. It could also be the case that the model is regularized too much.
- If the training curve reaches a high score relatively quickly and the validation curve is lagging behind, the model is overfitting. This means the model is very complex and there is too little data, or it could simply mean there is too little data.
- We would want the value of the parameter where the training and validation curves are closest to each other.
Implementation of Validation Curves in Python
For the sake of simplicity, in this example, we will use the very popular, ‘digits‘ dataset which is already present in the sklearn.dataset module of the sklearn library.
For this example, we will use the k-Nearest Neighbour(KNN) classifier and will plot the accuracy of the model on the training set score and the cross-validation score against the value of ‘k’, i.e., the number of neighbours to consider. Python code to implement 5-fold cross-validation and to test the value of ‘k’ from 1 to 10.
python3
import matplotlib.pyplot as plt
import numpy as np
from sklearn.datasets import load_digits
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import validation_curve
dataset = load_digits()
X, y = dataset.data, dataset.target
parameter_range = np.arange(1, 10, 1)
train_score, test_score = validation_curve(KNeighborsClassifier(), X, y,
param_name="n_neighbors",
param_range=parameter_range,
cv=5, scoring="accuracy")
mean_train_score = np.mean(train_score, axis=1)
std_train_score = np.std(train_score, axis=1)
mean_test_score = np.mean(test_score, axis=1)
std_test_score = np.std(test_score, axis=1)
plt.plot(parameter_range, mean_train_score,
label="Training Score", color='b')
plt.plot(parameter_range, mean_test_score,
label="Cross Validation Score", color='g')
plt.title("Validation Curve with KNN Classifier")
plt.xlabel("Number of Neighbours")
plt.ylabel("Accuracy")
plt.tight_layout()
plt.legend(loc='best')
plt.show()
|
Output:
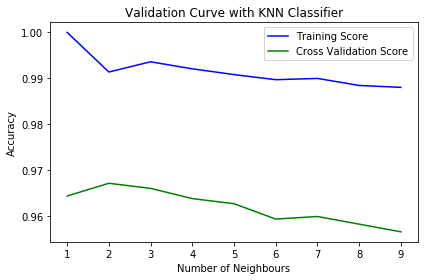
Validation curve plot for KNN classifier
From this graph, we can observe that ‘k’ = 2 would be the ideal value of k. As the number of neighbours (k) increases, both the accuracy of the Training Score as well as the cross-validation score decreases.
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...