Understanding BERT – NLP
Last Updated :
11 May, 2020
BERT stands for Bidirectional Representation for Transformers. It was proposed by researchers at Google Research in 2018. Although the main aim of that was to improve the understanding of the meaning of queries related to Google Search. A study shows that Google encountered 15% of new queries every day. Therefore, it requires the Google search engine to have a much better understanding of the language in order to comprehend the search query.
To improve the language understanding of the model. BERT is trained and tested for different tasks on a different architecture. Some of these tasks with the architecture discussed below.
Masked Language Model:
In this NLP task, we replace 15% of words in the text with the [MASK] token. The model then predicts the original words that are replaced by [MASK] token. Beyond masking, the masking also mixes things a bit in order to improve how the model later for fine-tuning because [MASK] token created a mismatch between training and fine-tuning. In this model, we add a classification layer at the top of the encoder input. We also calculate the probability of the output using a fully connected and a softmax layer.

Masked Language Model:
The BERT loss function while calculating it considers only the prediction of masked values and ignores the prediction of the non-masked values. This helps in calculating loss for only those 15% masked words.
Next Sentence Prediction:
In this NLP task, we are provided two sentences, our goal is to predict whether the second sentence is the next subsequent sentence of the first sentence in the original text. During training the BERT, we take 50% of the data that is the next subsequent sentence (labelled as isNext) from the original sentence and 50% of the time we take the random sentence that is not the next sentence in the original text (labelled as NotNext). Since this is a classification task so we the first token is the [CLS] token. This model also uses a [SEP] token to separate the two sentences that we passed into the model.

The BERT model obtained an accuracy of 97%-98% on this task. The advantage of training the model with the task is that it helps the model understand the relationship between sentences.
Fine Tune BERT for Different Tasks –
BERT for Sentence Pair Classification Task:
BERT has fine-tuned its architecture for a number of sentence pair classification tasks such as:
- MNLI: Multi-Genre Natural Language Inference is a large-scale classification task. In this task, we have given a pair of the sentence. The goal is to identify whether the second sentence is entailment, contradiction or neutral with respect to the first sentence.
- QQP: Quora Question Pairs, In this dataset, the goal is to determine whether two questions are semantically equal.
- QNLI: Question Natural Language Inference, In this task the model needs to determine whether the second sentence is the answer to the question asked in the first sentence.
- SWAG: Situations With Adversarial Generations dataset contains 113k sentence classifications. The task is to determine whether the second sentence is the continuation of first or not.

- Single Sentence Classification Task :
- SST-2: The Stanford Sentiment Treebank is a binary sentence classification task consisting of sentences extracted from movie reviews with annotations of their sentiment representing in the sentence. BERT generated state-of-the-art results on SST-2.
- CoLA:The Corpus of Linguistic Acceptability is the binary classification task. The goal of this task to predict whether an English sentence that is provided is linguistically acceptable or not.

- Question Answer Task: BERT has also generated state-of-the-art results Question Answering Tasks such as Stanford Question Answer Datasets (SQuAD v1.1 and SQuAD v2.0). In these Question Answering task, the model takes a question and passage. The goal is to mark the answer text span in the question.
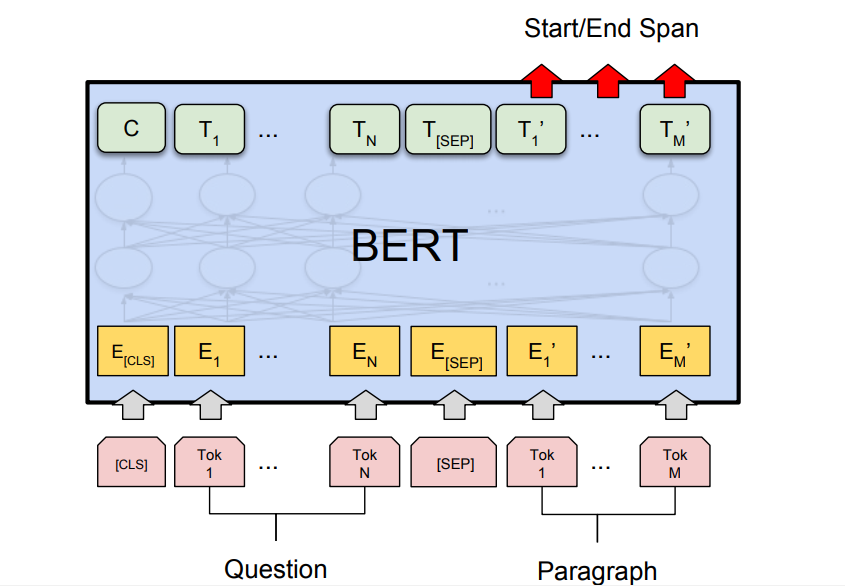
BERT for Google Search:
As we discussed above that BERT is trained and generated state-of-the-art results on Question Answers task. This was the result of particularly due to transformers models that we used in BERT architecture. These models take full sentences as inputs instead of word by word input. This helps in generating full contextual embeddings of a word and helps to understand the language better. This method is very useful in understanding the real intent behind the search query in order to serve the best results.

BERT Search Query From the above image, we can see that after applying the BERT model the google understands search query better, therefore, produced a more accurate result.
Conclusion:
BERT has proved to be a breakthrough in Natural Language Processing and Language Understanding field similar to that AlexNet has provided in the Computer Vision field. It has achieved state-of-the-art results in different task thus can be used for many NLP tasks. It is also used in Google Search in 70 languages as Dec 2019. References:
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...