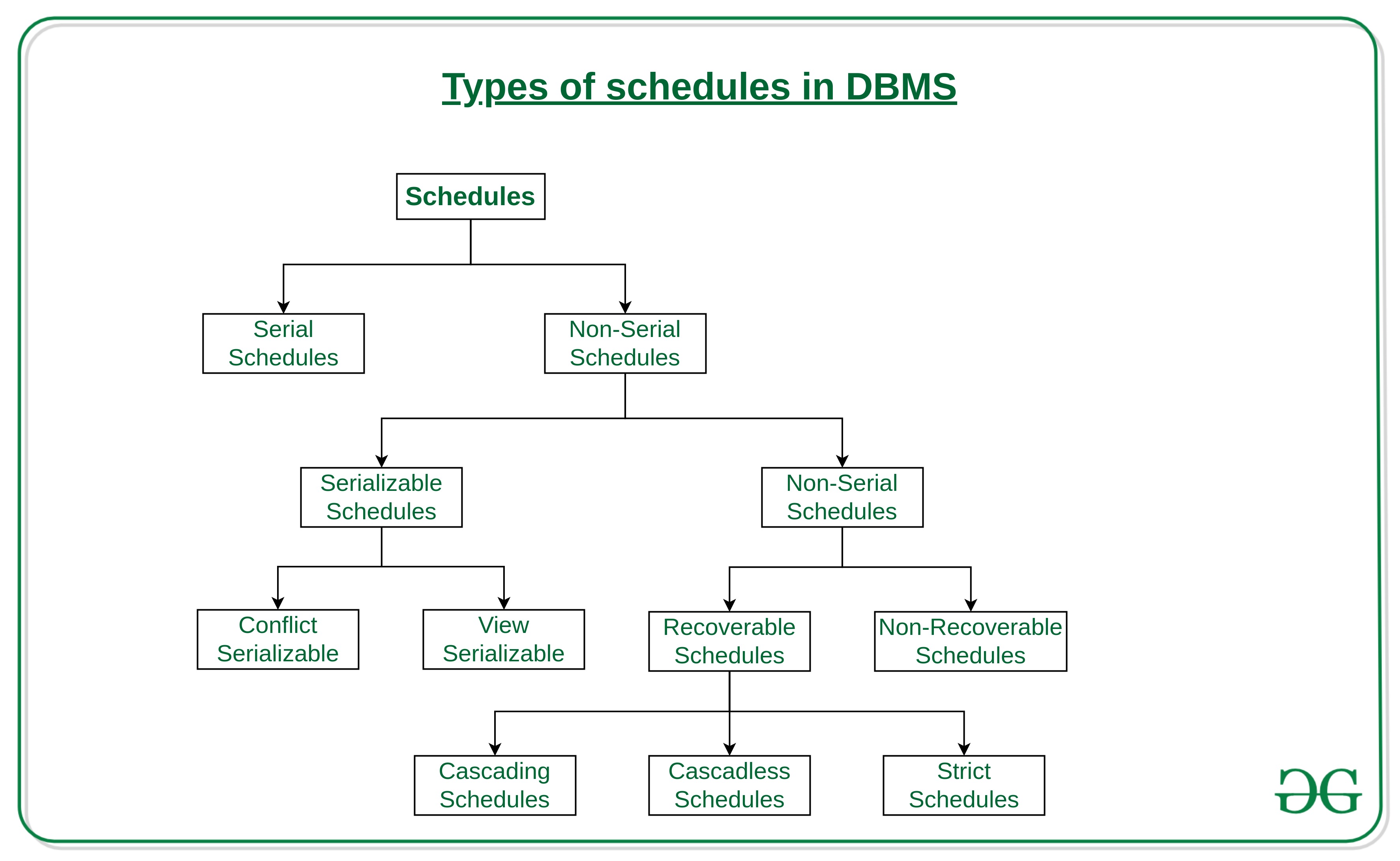
Types of Schedules in DBMS
Last Updated :
04 Feb, 2020
Schedule, as the name suggests, is a process of lining the transactions and executing them one by one. When there are multiple transactions that are running in a concurrent manner and the order of operation is needed to be set so that the operations do not overlap each other, Scheduling is brought into play and the transactions are timed accordingly. The basics of Transactions and Schedules is discussed in Concurrency Control (Introduction), and Transaction Isolation Levels in DBMS articles. Here we will discuss various types of schedules.
- Serial Schedules:
Schedules in which the transactions are executed non-interleaved, i.e., a serial schedule is one in which no transaction starts until a running transaction has ended are called serial schedules.
Example: Consider the following schedule involving two transactions T1 and T2.
| T1 |
T2 |
| R(A) |
|
| W(A) |
|
| R(B) |
|
|
W(B) |
|
R(A) |
|
R(B) |
where R(A) denotes that a read operation is performed on some data item ‘A’
This is a serial schedule since the transactions perform serially in the order T1 —> T2
- Non-Serial Schedule:
This is a type of Scheduling where the operations of multiple transactions are interleaved. This might lead to a rise in the concurrency problem. The transactions are executed in a non-serial manner, keeping the end result correct and same as the serial schedule. Unlike the serial schedule where one transaction must wait for another to complete all its operation, in the non-serial schedule, the other transaction proceeds without waiting for the previous transaction to complete. This sort of schedule does not provide any benefit of the concurrent transaction. It can be of two types namely, Serializable and Non-Serializable Schedule.
The Non-Serial Schedule can be divided further into Serializable and Non-Serializable.
- Serializable:
This is used to maintain the consistency of the database. It is mainly used in the Non-Serial scheduling to verify whether the scheduling will lead to any inconsistency or not. On the other hand, a serial schedule does not need the serializability because it follows a transaction only when the previous transaction is complete. The non-serial schedule is said to be in a serializable schedule only when it is equivalent to the serial schedules, for an n number of transactions. Since concurrency is allowed in this case thus, multiple transactions can execute concurrently. A serializable schedule helps in improving both resource utilization and CPU throughput. These are of two types:
- Conflict Serializable:
A schedule is called conflict serializable if it can be transformed into a serial schedule by swapping non-conflicting operations. Two operations are said to be conflicting if all conditions satisfy:
- They belong to different transactions
- They operate on the same data item
- At Least one of them is a write operation
- View Serializable:
A Schedule is called view serializable if it is view equal to a serial schedule (no overlapping transactions). A conflict schedule is a view serializable but if the serializability contains blind writes, then the view serializable does not conflict serializable.
- Non-Serializable:
The non-serializable schedule is divided into two types, Recoverable and Non-recoverable Schedule.
- Recoverable Schedule:
Schedules in which transactions commit only after all transactions whose changes they read commit are called recoverable schedules. In other words, if some transaction Tj is reading value updated or written by some other transaction Ti, then the commit of Tj must occur after the commit of Ti.
Example – Consider the following schedule involving two transactions T1 and T2.
| T1 |
T2 |
| R(A) |
|
| W(A) |
|
|
W(A) |
|
R(A) |
| commit |
|
|
commit |
This is a recoverable schedule since T1 commits before T2, that makes the value read by T2 correct.
There can be three types of recoverable schedule:
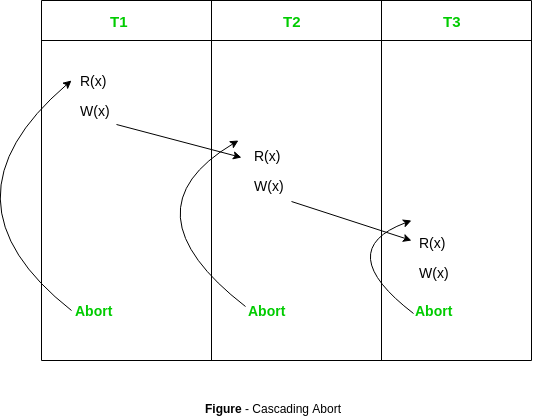
- Cascading Schedule:
Also called Avoids cascading aborts/rollbacks (ACA). When there is a failure in one transaction and this leads to the rolling back or aborting other dependent transactions, then such scheduling is referred to as Cascading rollback or cascading abort. Example:
- Cascadeless Schedule:
Schedules in which transactions read values only after all transactions whose changes they are going to read commit are called cascadeless schedules. Avoids that a single transaction abort leads to a series of transaction rollbacks. A strategy to prevent cascading aborts is to disallow a transaction from reading uncommitted changes from another transaction in the same schedule.
In other words, if some transaction Tj wants to read value updated or written by some other transaction Ti, then the commit of Tj must read it after the commit of Ti.
Example: Consider the following schedule involving two transactions T1 and T2.
| T1 |
T2 |
| R(A) |
|
| W(A) |
|
|
W(A) |
| commit |
|
|
R(A) |
|
commit |
This schedule is cascadeless. Since the updated value of A is read by T2 only after the updating transaction i.e. T1 commits.
Example: Consider the following schedule involving two transactions T1 and T2.
| T1 |
T2 |
| R(A) |
|
| W(A) |
|
|
R(A) |
|
W(A) |
| abort |
|
|
abort |
It is a recoverable schedule but it does not avoid cascading aborts. It can be seen that if T1 aborts, T2 will have to be aborted too in order to maintain the correctness of the schedule as T2 has already read the uncommitted value written by T1.
- Strict Schedule:
A schedule is strict if for any two transactions Ti, Tj, if a write operation of Ti precedes a conflicting operation of Tj (either read or write), then the commit or abort event of Ti also precedes that conflicting operation of Tj.
In other words, Tj can read or write updated or written value of Ti only after Ti commits/aborts.
Example: Consider the following schedule involving two transactions T1 and T2.
| T1 |
T2 |
| R(A) |
|
|
R(A) |
| W(A) |
|
| commit |
|
|
W(A) |
|
R(A) |
|
commit |
This is a strict schedule since T2 reads and writes A which is written by T1 only after the commit of T1.
- Non-Recoverable Schedule:
Example: Consider the following schedule involving two transactions T1 and T2.
| T1 |
T2 |
| R(A) |
|
| W(A) |
|
|
W(A) |
|
R(A) |
|
commit |
| abort |
|
T2 read the value of A written by T1, and committed. T1 later aborted, therefore the value read by T2 is wrong, but since T2 committed, this schedule is non-recoverable.
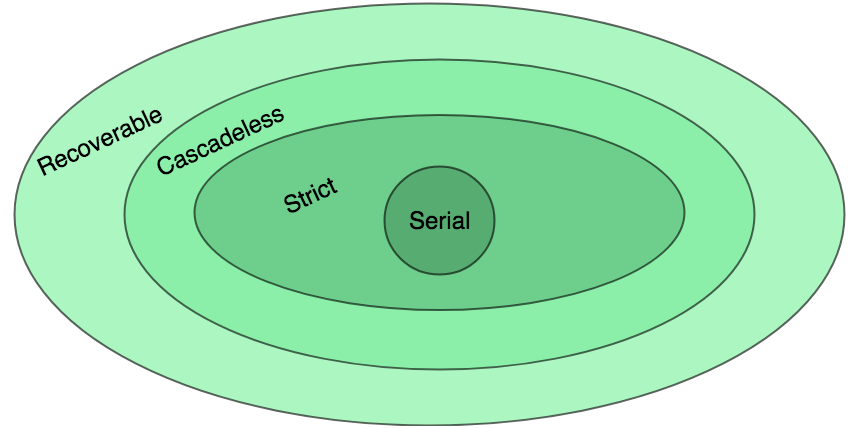
Note – It can be seen that:
- Cascadeless schedules are stricter than recoverable schedules or are a subset of recoverable schedules.
- Strict schedules are stricter than cascadeless schedules or are a subset of cascadeless schedules.
- Serial schedules satisfy constraints of all recoverable, cascadeless and strict schedules and hence is a subset of strict schedules.
The relation between various types of schedules can be depicted as:
Example: Consider the following schedule:
S:R1(A), W2(A), Commit2, W1(A), W3(A), Commit3, Commit1
Which of the following is true?
(A) The schedule is view serializable schedule and strict recoverable schedule
(B) The schedule is non-serializable schedule and strict recoverable schedule
(C) The schedule is non-serializable schedule and is not strict recoverable schedule.
(D) The Schedule is serializable schedule and is not strict recoverable schedule
Solution: The schedule can be re-written as:-
| T1 |
T2 |
T3 |
| R(A) |
|
|
|
W(A) |
|
|
Commit |
|
| W(A) |
|
|
|
|
W(A) |
|
|
Commit |
| Commit |
|
|
First of all, it is a view serializable schedule as it has view equal serial schedule T1 —> T2 —> T3 which satisfies the initial and updated reads and final write on variable A which is required for view serializability. Now we can see there is write – write pair done by transactions T1 followed by T3 which is violating the above-mentioned condition of strict schedules as T3 is supposed to do write operation only after T1 commits which is violated in the given schedule. Hence the given schedule is serializable but not strict recoverable.
So, option (D) is correct.
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...