Types and Part of Data Mining architecture
Last Updated :
22 Jun, 2022
Data Mining refers to the detection and extraction of new patterns from the already collected data. Data mining is the amalgamation of the field of statistics and computer science aiming to discover patterns in incredibly large datasets and then transform them into a comprehensible structure for later use.
The architecture of Data Mining:
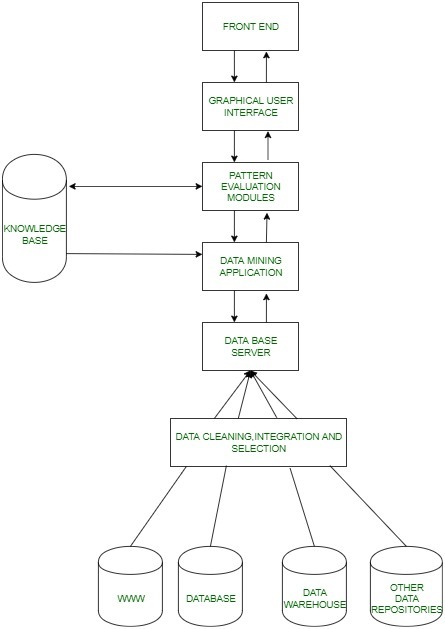
Basic Working:
- It all starts when the user puts up certain data mining requests, these requests are then sent to data mining engines for pattern evaluation.
- These applications try to find the solution to the query using the already present database.
- The metadata then extracted is sent for proper analysis to the data mining engine which sometimes interacts with pattern evaluation modules to determine the result.
- This result is then sent to the front end in an easily understandable manner using a suitable interface.
A detailed description of parts of data mining architecture is shown:
- Data Sources: Database, World Wide Web(WWW), and data warehouse are parts of data sources. The data in these sources may be in the form of plain text, spreadsheets, or other forms of media like photos or videos. WWW is one of the biggest sources of data.
- Database Server: The database server contains the actual data ready to be processed. It performs the task of handling data retrieval as per the request of the user.
- Data Mining Engine: It is one of the core components of the data mining architecture that performs all kinds of data mining techniques like association, classification, characterization, clustering, prediction, etc.
- Pattern Evaluation Modules: They are responsible for finding interesting patterns in the data and sometimes they also interact with the database servers for producing the result of the user requests.
- Graphic User Interface: Since the user cannot fully understand the complexity of the data mining process so graphical user interface helps the user to communicate effectively with the data mining system.
- Knowledge Base: Knowledge Base is an important part of the data mining engine that is quite beneficial in guiding the search for the result patterns. Data mining engines may also sometimes get inputs from the knowledge base. This knowledge base may contain data from user experiences. The objective of the knowledge base is to make the result more accurate and reliable.
Types of Data Mining architecture:
- No Coupling: The no coupling data mining architecture retrieves data from particular data sources. It does not use the database for retrieving the data which is otherwise quite an efficient and accurate way to do the same. The no coupling architecture for data mining is poor and only used for performing very simple data mining processes.
- Loose Coupling: In loose coupling architecture data mining system retrieves data from the database and stores the data in those systems. This mining is for memory-based data mining architecture.
- Semi-Tight Coupling: It tends to use various advantageous features of the data warehouse systems. It includes sorting, indexing, and aggregation. In this architecture, an intermediate result can be stored in the database for better performance.
- Tight coupling: In this architecture, a data warehouse is considered one of its most important components whose features are employed for performing data mining tasks. This architecture provides scalability, performance, and integrated information
Advantages of Data Mining:
- Assists in preventing future adversaries by accurately predicting future trends.
- Contributes to the making of important decisions.
- Compresses data into valuable information.
- Provides new trends and unexpected patterns.
- Helps to analyze huge data sets.
- Aids companies to find, attract and retain customers.
- Helps the company to improve its relationship with the customers.
- Assists Companies to optimize their production according to the likability of a certain product thus saving costs to the company.
Disadvantages of Data Mining:
- Excessive work intensity requires high-performance teams and staff training.
- The requirement of large investments can also be considered a problem as sometimes data collection consumes many resources that suppose a high cost.
- Lack of security could also put the data at huge risk, as the data may contain private customer details.
- Inaccurate data may lead to the wrong output.
- Huge databases are quite difficult to manage.
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...