A data warehouse is a Data management system that is used for storing, reporting, and data analysis. It is the primary component of business intelligence and is also known as an enterprise data warehouse. Data Warehouses are central repositories that store data from one or more heterogeneous sources. Data warehouses are analytical tools built to support decision-making for reporting users across many departments. Data warehouse works to create a single, unified system of truth for an entire organization and store historical data about business and organization so that it could be analyzed and extract insights from it.
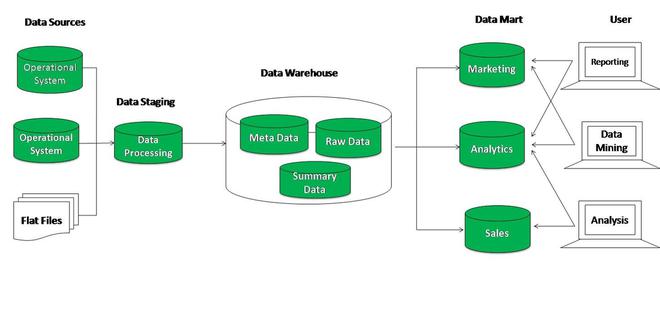
Data Flow through Warehouse Architecture
Previously, organizations had to build lots of infrastructure for data warehousing but today, cloud computing technology has amazingly reduced the efforts as well as the cost of building data warehousing for businesses. Data warehouses and their tools are moving from physical data centers to cloud-based data warehouses. Many large organizations still operate data through the traditional way of data warehousing but clearly, the future of the data warehouse is in the cloud. The cloud-based data warehousing tools are fast, efficient, highly scalable, and available based on pay-per-use.
There are various cloud-based Data Warehousing tools available. So, it becomes difficult to select top Data Warehouse tools according to our project requirements. Following are the top 8 Data Warehousing tools:
1. Amazon Redshift:
Amazon Redshift is a cloud-based fully managed petabytes-scale data warehouse By the Amazon Company. It starts with just a few hundred gigabytes of data and scales to petabytes or more. This enables the use of data to accumulate new insights for businesses and customers. It is a relational database management system (RDBMS) therefore it is compatible with other RDBMS applications. Amazon Redshift offers quick querying capabilities over structured data by the use of SQL-based clients and business intelligence (BI) tools using standard ODBC and JDBC connections. Amazon Redshift is made around industry-standard SQL, with additional practicality to manage massive datasets and support superior analysis and reporting of these data. It helps to work quickly and easily along with data in open formats, and simply integrates with and connects to the AWS scheme. Also query and export data to and from the data lake. No alternative cloud data warehouse tool makes it straightforward to query data and writes data back to the data lake in open formats. It focuses on simple Use and Accessibility. MySQL and alternative SQL-based systems are one in all the foremost well-liked and simply usable interfaces for database management. Redshift’s easy query-based system makes platform adoption and acclimatization a light breeze. It is incredibly quick once it involves loading data and querying it for analytical and reporting functions. Redshift features a massively parallel processing (MPP) design that permits loading data at a very high speed.
2. Microsoft Azure:
Azure is a cloud computing platform that was launched by Microsoft in 2010. Microsoft Azure is a cloud computing service provider for building, testing, deploying, and managing applications and services through Microsoft-managed data centers. Azure is a public cloud computing platform that offers Infrastructure as a Service (IaaS), Platform as a Service (PaaS), and Software as a Service (SaaS). The Azure cloud platform provides more than 200 products and cloud services such as Data Analytics, Virtual Computing, Storage, Virtual Network, Internet Traffic Manager, Web Sites, Media Services, Mobile Services, Integration, etc. Azure facilitates simple portability and genuinely compatible platform between on-premise and public Cloud. Azure provides a range of cross-connections including virtual private networks (VPNs), caches, content delivery networks (CDNs), and ExpressRoute connections to improve usability and performance. Microsoft Azure provides a secure base across physical infrastructure and operational security. Azure App offers a completely managed web hosting service that helps in building web applications, services, and Restful APIs. It offers a variety of plans to meet the requirements of any application, from small to globally scaled web applications. Running virtual machines or containers in the cloud is one of the most popular applications of Microsoft Azure.
3. Google BigQuery:
BigQuery is a serverless data warehouse that allows scalable analysis over petabytes of data. It’s a Platform as a Service that supports querying with the help of ANSI SQL. It additionally has inbuilt machine learning capabilities. BigQuery was declared in 2010 and made available for use there in 2011. Google BigQuery is a cloud-based big data analytics web service to process very huge amount of read-only data sets. BigQuery is designed for analyzing data that are in billions of rows by simply employing SQL-lite syntax. BigQuery can run advanced analytical SQL-based queries beneath big sets of data. BigQuery is not developed to substitute relational databases and for easy CRUD operations and queries. It is oriented for running analytical queries. It is a hybrid system that enables the storage of information in columns; however, it takes into the NoSQL additional features, like the data type, and the nested feature. BigQuery is a better option than Redshift since we have to pay by the hour. BigQuery may also be the best solution for data scientists running ML or data mining operations since they deal with extremely large datasets. Google Cloud also offers a set of auto-scaling services that enables you to build a data lake that integrates with your existing applications, skills, and IT investments. In BigQuery, most of the time is spent on metadata/initiation, but the actual execution time is very small.
4. Snowflake:
Snowflake is a cloud computing-based data warehousing built on top of the Amazon Web Services or Microsoft Azure cloud infrastructure. The Snowflake design allows storage and computes to scale independently, thus customers can use and pay money for storage and computation individually. In Snowflake data processing is simplified: Users will do data blending, analysis, and transformations against varied forms of data structures with one language, SQL. Snowflake offers dynamic, scalable computing power with charges primarily based strictly on usage. With Snowflake, computation and storage are fully separate, and also the storage value is that the same as storing the data on Amazon S3. AWS tried to handle this issue by introducing Redshift Spectrum, which allows querying data that exists directly on Amazon S3; however, it’s not as seamless as Snowflake. With Snowflake, we can clone a table, a schema, or perhaps a database in no time and occupying no extra space. This is often because the cloned table creates pointers that point to the kept data, however, not the actual data. In alternative words, the cloned table solely has data that’s completely different from its original table.
5. Micro Focus Vertica:
Micro Focus Vertica: Micro Focus Vertica is developed to use in data warehouses and other big data workloads where speed, scalability, simplicity, and openness are crucial to the success of analytics. It is a self-monitored MPP database and offers scalability and flexibility that other tools don’t. It is used on commercial hardware, therefore we can scale the database as required. It is designed significantly in-database advanced analytics capabilities to improve query performance over traditional relational database systems and unverified open source offerings. For example, Vertica is a column-oriented relational database; therefore, it might not qualify as a NoSQL database. A NoSQL database is best outlined as being a non-relational, shared-nothing, horizontally scalable database while not ACID guarantees. Vertica differs from normal RDBMS within the approach that it stores data by grouping data at once on disk by column instead of by row, Vertica reads the columns documented by the query, rather than scanning the complete table as row-oriented databases should do. Vertica offers the foremost advanced unified analytical warehouse that allows the organization to stay up with the dimensions and complexness of huge amounts of data volumes. With Vertica, businesses can perform tasks like predictive maintenance, client remembrance, economic compliance and network optimization, and far more.
6. Amazon DynamoDB:
Amazon DynamoDB is a fully managed proprietary NoSQL data warehouse service that supports key-value and document data structures and is obtainable by Amazon.com as a part of the Amazon Web Services portfolio. DynamoDB has an identical data model and encompasses a completely different underlying implementation. A partition key value is used in DynamoDB as input to an enclosed hash function. The output from the hash function determines the partition within which the item is going to be kept. All items with identical partition key values are stored together, in sorted order by sort key value. It offers customers high availability, dependability, and progressive scalability, with no limits on dataset size or request output for a given table. DynamoDB is meant for OLTP use cases high-speed data access wherever you are operative on many records at a time. However, users even have a desire for OLAP access patterns massive, analytical queries over the complete dataset to search out common things, or a variety of orders by day, or different insights. DynamoDB is aligned with the values of Serverless applications: automatic scaling consistent with your application load, pay-per-what-you-use rating, simple to induce started with, and no servers to manage. This makes DynamoDB an awfully common selection for Serverless applications running in AWS.
7. PostgreSQL:
It is an extremely stable database management system, backed by over twenty years of community development that has contributed to its high levels of resilience, integrity, and correctness. PostgreSQL is employed because the primary data store or data warehouse for several web, mobile, geospatial, and analytics applications. SQL Server is a database management system that is especially used for e-commerce and providing different data warehousing solutions. PostgreSQL is a sophisticated version of SQL that provides support to various functions of SQL like foreign keys, subqueries, triggers, and other user-defined varieties and functions. Postgres is a feature-rich database that can handle advanced complicated queries and big databases. MySQL is a less complicated database that is comparatively simple to line up and manage, fast, reliable, and well-understood. PostgreSQL performs well in OLTP/OLAP systems once read/write speeds are needed and intensive data analysis is required. PostgreSQL additionally works well with Business Intelligence applications however is best suited to data warehousing and data analysis applications that require quick read/write operations speed.
8. Amazon S3:
Amazon S3 is object storage engineered to store and retrieves any quantity of data from any place. It is an easy storage service that provides business-leading sturdiness, accessibility, performance, security, and nearly unlimited scalability at very low prices. AWS S3 is a key-value store, one of the foremost classes of NoSQL databases used for accumulating voluminous, mutating, unstructured, or semi-structured data. Features like metadata support, prefixes, and object tags enable users to arrange data consistent with their desires. The S3 object storage cloud service offers subscriber access to similar systems that Amazon uses to run its own websites. Amazon S3 is object storage capable of storing massive objects, up to 5TB in size. S3 allows customers to access, store and download practically any file or object that’s up 5 TB in size with the biggest single upload capped at 5 gigabytes (GB). S3 is often used for storing pictures, videos, logs, and alternative varieties of files. There’s no limit on the number of objects that may be stored in an S3 bucket. Every object in S3 includes a URL that might be used to download the object. S3 provides unlimited storage at a comparatively low cost than DynamoDB; however, scan operations are abundant slower than DynamoDB, although it can perform HTTP queries for the same. Amazon S3 sets the quality once it involves business cloud storage whereas simple use is not a part of that standard but, top-quality security, extreme flexibility, and total integration are.
9. Teradata:
Teradata is one of the admired Relational Database Management systems. It is appropriate for building big data warehousing applications. Teradata accomplishes this with the help of parallelism. Teradata database system is built on Massively Parallel Processing (MPP) architecture. The Teradata system primarily splits the work among its processes and runs them in parallel to reduce workload and also makes sure that the task is accomplished quickly and successfully. Teradata provides real-time, intelligent answers by processing 100% of the appropriate data, despite the volume of the query. Teradata fulfills all the requirements in terms of Integration or ETL with the capabilities of consuming, analyzing and managing the data. Data in an exceeding data warehouse is organized to support analysis instead of processing real-time transactions as in online transaction processing systems (OLTP). Although it is geared towards OLAP. It’s one of the most powerful data integration and analytics database solutions within the market. Teradata is employed or has been utilized in past by most business enterprises. It processes enormous amounts of data very easily. It’s simple to navigate and a sensible graphical user interface helps Business users use it with basic training and query knowledge, however, big data processing is a challenge because of its existing architectures.
10. Amazon RDS:
Amazon Relational Database Service is a cloud data storage service to operate and scale a relational database within the AWS Cloud. Its cost-effective and resizable hardware capability helps us to build an industry-standard relational database and manages all usual database administration tasks. Amazon RDS is a PaaS because it solely provides a platform or a group of tools to manage your database instances. AWS is IaaS; however, the RDS provided by AWS is PaaS. Amazon RDS can manage complicated and long tasks like software installation and upgrades, storage management, replication for high availability and backups for disaster recovery. We can also deploy scalable MySQL servers as per requirement in minutes with cost-effective and resizable hardware capability with the help of Amazon RDS. Amazon RDS has 3 instance classes: Standard, Memory Optimized, and Burstable Performance. These instance classes are comprised of variable combos of C.P.U., memory, storage, and networking capability and provide you with the flexibility to decide on the acceptable mix of resources for the database. In Amazon, RDS supports there are six database engines we can choose from, they are Amazon Aurora, PostgreSQL, MySQL, MariaDB, Oracle info, and SQL Server.
11. IBM Db2 Warehouse:
IBM Db2 Warehouse is an elastic cloud data warehouse that provides independent scaling of data storage and computation. IBM Db2 is a data management product from IBM including Db2 relational database. It is meant to store, analyze and retrieve the data with efficiency. Extremely optimized columns data storage and in-memory process facilitate boost analytics and machine learning burden. IBM Db2 is a well-developed, completely managed Cloud SQL Database-as-a-Service solution alongside Db2 and Oracle PL/SQL compatibility. It is a Relational Database Management System (RDBMS) designed to store, analyze and retrieve the data with efficiency and is highly robust and powerful. Its Data migration processes and therefore the user interface (UI) are clean, intuitive, and simple to work for users of a variety of skill levels. IBM Db2 is now, turning into the AI database that may facilitate in power today’s cognitive applications, assist to modernize AI development, and enabling management of each structured and unstructured data across the physical platform and multi-cloud environments.
12. Oracle Autonomous Warehouse:
Autonomous Data Warehouse is a cloud-based data warehousing service provided by Oracle that removes all the complexities of constructing a data warehouse, data security, and helps in developing data-driven applications. It automates the process of configuring, securing, regulating, scaling, and backing up the data in the data warehouse. It provides a new, comprehensive cloud experience for data storage that’s simple, fast, and elastic. An autonomous data Warehouse is that a complete resolution that uses a converged database providing constitutional support for multi-model data and multiple workloads. It includes inbuilt self-service tools to enhance the productivity of analysts, data scientists, and developers. It independently encrypts information at rest and in motion, protects regulated information; put-ups required security reinforcements and detects threats. Additionally, customers can simply use Oracle data Safe to perform user and privilege analysis, sensitive data discovery and protection, and activity auditing. An autonomous data Warehouse makes it simple to stay data safe from outsiders and insiders. Uniquely, it’s additionally ready to incessantly alter performance standardization and auto-scaling, with no outage time, human interference. This reduces administration effort by more than 80% and allows business groups to work without facilitation from IT.
13. MariaDB:
MariaDB Server is one of the most well-liked ASCII text file relational databases. It’s created by the initial developers of MySQL and absolute to keep the open-source. MariaDB includes a good choice of storage engines, as well as superior storage engines, for operating with alternative RDBMS data sources. MariaDB uses a regular and well-liked querying language. MariaDB runs on many operative systems and supports a good style of programming languages. A bit like MySQL, MariaDB conjointly uses a client/server model with a server program that files requests from client programs. As is typical of client/server computer systems, the server and therefore the client programs will be on completely different hosts. MariaDB shows an improved speed when put next to MySQL. MySQL exhibits a slower speed when put next to MariaDB. With the Memory storage engine of MariaDB, any data operating statement will be executed faster than the standard MySQL storage engine. The memory storage engine of MySQL is slower than the storage engine of MariaDB and it also supports plenty of commands along with interfaces that are more accessible to NoSQL than to SQL.
14. MarkLogic:
MarkLogic is a multi-model NoSQL database that has evolved from its XML database roots to additionally natively store JSON documents and RDF triples for its linguistics data model. It uses a distributed design that may handle many billions of documents and many terabytes of knowledge. Associate in Nursing Operational information Warehouse designed on the MarkLogic Enterprise NoSQL platform not solely improves upon the normal capabilities related to associate in Nursing ODW e.g. ingesting giant amounts of knowledge and creating it out there for question in real-time, however, additionally makes this capability out there for a wider form of data. MarkLogic provides an extremely differentiated product and provides the flexibleness for clients to vary cloud suppliers later if necessary. The planning philosophy behind the evolution of MarkLogic is that storing information is merely a part of the answer. It uses XML and JSON documents in the form of the data models and stores these documents within a transactional repository. It indexes the words and values from every one of the loaded documents, likewise because of the document structure. MarkLogic Data Hub is a set of tools that assist quickly in build an operational information hub on the MarkLogic Server. The operational data hub pattern may be a method of building information hubs that facilitate quick and a lot of agile information integration, whereas permitting period simultaneous interactive access to information.
15. Cloudera:
Cloudera Data Warehousing Platform is that the industry’s 1st enterprise data cloud i.e. multi-functional analytics based on a platform that eliminates silos and speeds up the invention of data-driven insights. It applies consistent security, governance, and metadata in shared data cases. Cloudera’s trendy Data Warehouse powers superior bismuth and data deposit in each on-premises deployment and as a cloud service. Business users will explore and operate on information quickly, run new reports and workloads, or access interactive dashboards while not help from the IT department. Additionally, IT will eliminate the inefficiencies of data silos by consolidating data marts into a climbable analytics platform to raised meet business desires. With its open design, information is accessed by additional users with additional tools, together with data scientists and engineers, providing additional worth at a lower price. Solely Cloudera also offers a modern enterprise platform, tools, and skills that help us to unlock business understanding with machine learning and AI. Cloudera’s trendy platform for machine learning and analytics, optimized for the cloud, enables us to build and deploy AI solutions at scale, with efficiency and firmly, anyplace we would like. Cloudera quick Forward Labs skilled guidance helps you notice your AI future, faster.
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...