“Computers are able to see, hear, and learn. Welcome to the future.”
Machine Learning is the future. According to Forbes, Machine learning patents grew at a 34% Rate between 2013 and 2017 and this is only set to increase in coming times. Moreover, a Harvard Business review article called a Data Scientist as the “Sexiest Job of the 21st Century” (And that’s incentive right there!!!).

Machine Learning Algorithms
In these highly dynamic times, there are various machine learning algorithms developed by data scientists to solve complex real-world problems. These algorithms are highly automated and self-modifying as they continue to improve over time with the addition of an increased amount of data and with minimum human intervention required. So this article deals with the Top 10 Machine Learning algorithms for data science.
What is Machine Learning Algorithms?
Machine learning algorithms are programs that can easily learn and understand the hidden patterns in the data, predict future outcomes, and self-improve their performance from past experiences.
There are different ML algorithms based on task requirements, like linear regression, which is used to build prediction models, or k-nearest neighbor (KNN), which is used for classification solutions.
We have provided you with the top 10 machine learning algorithms for beginners to cover a wide variety of functionalities in data science and machine learning. Let’s look at some popular machine learning algorithms you can learn in 2024.
What are the Most Popular Machine Learning Algorithms in 2024?
The Best Machine Learning(ML) Algorithms are mentioned below, these algorithms can be used for tasks like classification, prediction, model building, etc.
- Naïve Bayes Classifier Algorithm
- K Means Clustering Algorithm
- Support Vector Machine Algorithm
- Apriori Algorithm
- Linear Regression Algorithm
- Logistic Regression Algorithm
- Decision Trees Algorithm
- Random Forests Algorithm
- K Nearest Neighbours Algorithm
- Artificial Neural Networks Algorithm
Types of Machine Learning Algorithms
Machine learning algorithms can be classified into 4 different types, namely:
- Supervised Learning
- Semi-supervised learning
- Unsupervised Learning
- Reinforcement Learning
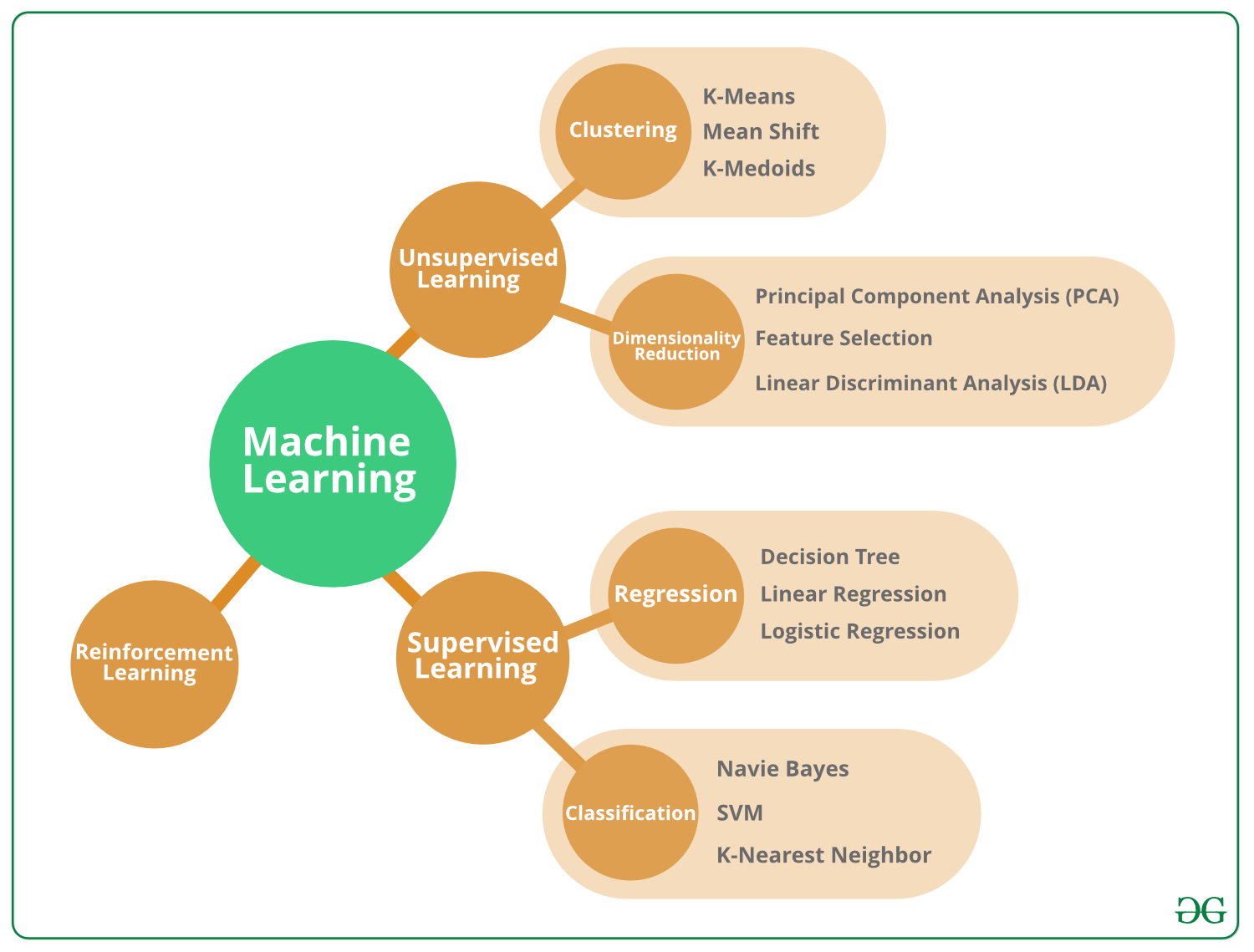 Supervised Learning Algorithms:
Supervised Learning Algorithms:
In supervised learning model, the algorithms learn from labeled data. We give input and the corresponding correct output to the algorithm, the algorithm then trains on this given dataset to predict output from unlabeled data.
Some of the supervised learning algorithms are:
- Decision tree
- SVM
- K-nearest neighbor
- linear regression
Real-life Example:
Imagine a teacher supervising a class. The teacher already knows the correct answers, but the learning process doesn’t stop until the students learn the answers as well (poor kids!). This is the essence of supervised machine learning algorithms.
Here, the algorithm is the student that learns from a training dataset and makes predictions that are corrected by the teacher. This learning process continues until the algorithm achieves the required level of performance.
Unsupervised Learning Algorithms:
In unsupervised learning model, the algorithm trains on unlabeled data with no knowledge of the output.
Some unsupervised learning algorithms include:
Real-life Example:
In this case, there is no teacher for the class, and the poor students are left to learn for themselves! This means that for unsupervised machine learning algorithms, there is no specific answer to be learned, and there is no teacher. The algorithm is left unsupervised to find the underlying structure in the data and learn more and more about the data itself.
Also Read: Difference between Supervised and Unsupervised Learning
Semi-Supervised Learning Algorithms:
In semi-supervised learning model, the algorithm uses a hybrid approach that requires using labeled data and unlabeled data for training. It trains using the labeled data and then gets additional information to increase its understanding and performance using unlabelled data.
Real-life Example:
In this case, imagine a teacher teaching a class, but a few students have books and some don’t. The teacher can easily guide students with books but she also has to teach students without books.
Here, the algorithm learns from a very small data set to find the hidden pattern and then applies the learning to the bigger data set. The teacher has to notice the behavior, discussions, and problem-solving methods of students without books and try to find more insights using students without books to teach them.
Reinforcement Learning Algorithms:
In reinforcement learning model, the algorithm directly interacts with the environment and is given a reward for a correct response and a penalty for a wrong decision. The algorithm learns from its mistakes to improve performance.
Real-life Example:
Well, here are hypothetical students who learn from their mistakes over time (that’s like life!). So the reinforcement machine learning algorithms learn optimal actions through trial and error. This means that the algorithm decides the next action by learning behaviors that are based on its current state and that will maximize the reward in the future.
Learn in-demand skills with our Machine Learning Self-Paced Course. Learn from data by delving into the topics like Regression, NLP, Clustering, and a lot more. Gain more skills with projects based on real-world applications. So, this is the high time, if you want to sharpen your machine learning skills and become an expert in Machine Learning.
Top 10 Machine Learning Algorithms
There are specific machine learning algorithms that were developed to handle complex real-world data problems. So, now that we have seen the types of machine learning algorithms, let’s study the best machine learning algorithms that exist and are actually used by data scientists.
1. Naïve Bayes Classifier Algorithm
What would happen if you had to classify data texts such as a web page, a document, or an email manually? Well, you would go mad! But thankfully, this task is performed by the Naïve Bayes Classifier Algorithm.
This algorithm is based on the Bayes Theorem of Probability(you probably read that in math), and it allocates the element value to a population from one of the categories that are available. It is a machine learning algorithm for classification and comes under supervised learning.

where y is a class variable and X is a dependent feature vector (of size n) where:

An example of the Naïve Bayes Classifier Algorithm usage is for email spam filtering. Gmail uses this algorithm to classify an email as spam or not spam.
2. K-Means Clustering Algorithm
Let’s imagine that you want to search for the term “date” on Wikipedia. Now, “date” can refer to a fruit, a particular day, or even a romantic evening with your love!!! So Wikipedia groups the web pages that talk about the same ideas using the K-Means Clustering Algorithm (since it is a popular algorithm for cluster analysis).
The K-means clustering algorithm, in general, uses K number of clusters to operate on a given data set. In this manner, the output contains K clusters with the input data partitioned among the clusters(As pages with different “date” meanings were partitioned).
3. Support Vector Machine Algorithm
The Support Vector Machine Algorithm is used for classification or regression problems. In this, the data is divided into different classes by finding a particular line (hyperplane), which separates the data set into multiple classes. The Support Vector Machine Algorithm tries to find the hyperplane that maximizes the distance between the classes (known as margin maximization), as this increases the probability of classifying the data more accurately.
An example of the Support Vector Machine Algorithm is for the comparison of stock performance for stocks in the same sector. This helps in managing investment-making decisions by financial institutions.
4. Apriori Algorithm
The Apriori Algorithm generates association rules using the IF_THEN format. This means that if event A occurs, then event B also occurs with a certain probability. For example, if a person buys a car, then they also buy car insurance. The Apriori Algorithm generates this association rule by observing the number of people who bought car insurance after buying a car.
An example of the Apriori Algorithm usage is for Google auto-complete. When a word is typed in Google, the Apriori Algorithm looks for the associated words that are usually typed after that word and displays the possibilities.
5. Linear Regression Algorithm
The Linear Regression Algorithm shows the relationship between an independent and a dependent variable. It demonstrates the impact on the dependent variable when the independent variable is changed in any way. So the independent variable is called the explanatory variable, and the dependent variable is called the factor of interest.
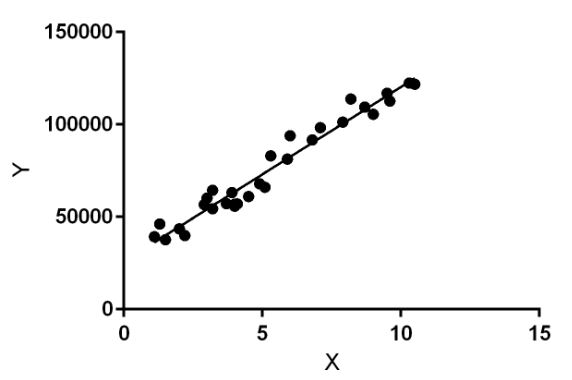
An example of the Linear Regression Algorithm usage is for risk assessment in the insurance domain. Linear regression analysis can be used to find the number of claims for customers of multiple ages and then deduce the increased risk as the customer’s age increases.
6. Logistic Regression Algorithm
The Logistic Regression Algorithm deals in discrete values, whereas the linear regression algorithm handles predictions with continuous values. So, logistic regression is suited for binary classification, wherein if an event occurs, it is classified as 1 and if not, it is classified as 0. Hence, the probability of a particular event occurrence is predicted based on the given predictor variables.
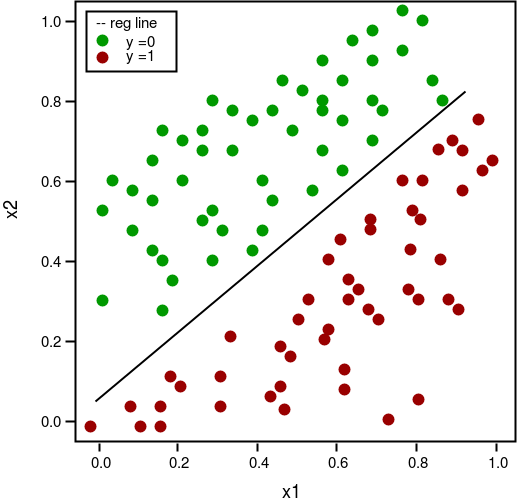
An example of the Logistic Regression Algorithm’s usage is in politics to predict if a particular candidate will win or lose a political election.
7. Decision Trees Algorithm
Suppose that you want to decide on the venue for your birthday. So many questions factor in your decision, such as “Is the restaurant Italian?”, “Does the restaurant have live music?”, “Is the restaurant close to your house?” etc. Each question has a YES or NO answer contributing to your decision.
This is what happens in the Decision Trees Algorithm. Here, all possible outcomes of a decision are shown using a tree-branching methodology. The internal nodes are tested on various attributes, the branches of the tree are the outcomes of the tests and the leaf nodes are the decisions made after computing all of the attributes.
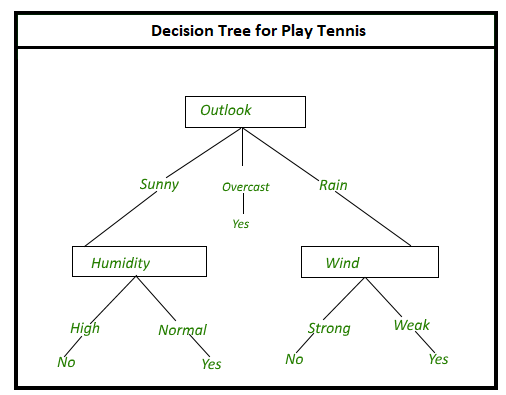
An example of the Decision Trees Algorithm usage is in the banking industry to classify loan applicants by their probability of defaulting on said loan payments.
8. Random Forests Algorithm
The Random Forests Algorithm handles some of the limitations of the Decision Trees Algorithm, namely that the accuracy of the outcome decreases when the number of decisions in the tree increases.
So, in the Random Forests Algorithm, there are multiple decision trees that represent various statistical probabilities. All of these trees are mapped to a single tree known as the CART model. (Classification and Regression Trees). In the end, the final prediction for the Random Forests Algorithm is obtained by polling the results of all the decision trees.
An example of the Random Forests Algorithm usage is in the automobile industry to predict the future breakdown of any particular automobile part.
9. K-Nearest Neighbours Algorithm
The K-Nearest Neighbours Algorithm divides the data points into different classes based on a similar measure such as the distance function. Then a prediction is made for a new data point by searching through the entire data set for the K most similar instances (the neighbors) and summarizing the output variable for these K instances. For regression problems, this might be the mean of the outcomes and for classification problems, this might be the mode (most frequent class).
The K Nearest Neighbours Algorithm can require a lot of memory or space to store all of the data but only performs a calculation (or learns) when a prediction is needed, just in time.
10. Artificial Neural Networks Algorithm
The human brain contains neurons that are the basis of our retentive power and are sharp(At least for some of us!). So, Artificial Neural Networks try to replicate the neurons in the human brain by creating nodes that are interconnected to each other. These neurons take in information through another neuron, perform various actions as required, and then transfer the information to another neuron as output.
An example of Artificial Neural Networks is Human facial recognition. Images with human faces can be identified and differentiated from “non-facial” images. However, this could take multiple hours depending on the number of images in the database whereas the human mind can do this instantly.
Summary
These top 10 machine learning algorithms are very essential to learn if you want to start a career in Data Science or Machine Learning. The algorithms are very important problem-solving tools and are asked in machine learning job interviews.
We have discussed about machine learning algorithms, their types, and the top 10 best machine learning algorithms in 2024. Each algorithm serves a different purpose, but each one of them is very important.
After reading this article you will have a complete idea of top machine learning algorithms, and you will want to practice these algorithms to prepare for your exams, interviews, etc.
More on Machine Learning
Here are some more articles on Machine learning, to help you develop top machine-learning skills:
FAQs – Top 10 ML Algorithms
Q1. What is the fastest machine learning algorithm?
Some of the fastest machine learning algorithms are:
- Linear regression
- K-nearest neighbor
- Naive-Bayes
- Stochastic Gradient Descent (SGD)
- Decision Trees
Q2. Which is the most used machine learning model?
Some of the most commonly used machine learning models are:
- Linear Regression
- Logistic Regression
- Random Forests
- Decision Trees
Q3. What are the 5 popular algorithms of machine learning?
5 popular machine algorithms are:
- Linear Regression
- Random Forests
- Support Vector Machines (SVMs)
- K-means Clustering
- Decision Tree
Q4. Which ML algorithm is best for prediction?
Linear regression is one of the most commonly used machine learning algorithms used for predictive model building. There are also other ML algorithms used for prediction like decision trees, support vector machines(SVM), neural networks, and gradient boosting methods.
Q5. What are the three types of machine learning algorithms?
Three Types of Machine Learning algorithms are:
- Supervised Learning
- Unsupervised Learning
- Reinforcement Learning
Q6. Which algorithm is more efficient in machine learning?
Depending on the type of task, there can be different machine learning algorithms that are fast and efficient. Some fastest and efficient machine learning algorithms are:
- Random Forests
- XGBoost
- Linear Regression
- K-nearest Neighbor(KNN)
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...