Machine learning is a field of computer science that gives computers the ability to learn without being explicitly programmed. Supervised learning and unsupervised learning are two main types of machine learning.
In supervised learning, the machine is trained on a set of labeled data, which means that the input data is paired with the desired output. The machine then learns to predict the output for new input data. Supervised learning is often used for tasks such as classification, regression, and object detection.
In unsupervised learning, the machine is trained on a set of unlabeled data, which means that the input data is not paired with the desired output. The machine then learns to find patterns and relationships in the data. Unsupervised learning is often used for tasks such as clustering, dimensionality reduction, and anomaly detection.
What is Supervised learning?
Supervised learning is a type of machine learning algorithm that learns from labeled data. Labeled data is data that has been tagged with a correct answer or classification.
Supervised learning, as the name indicates, has the presence of a supervisor as a teacher. Supervised learning is when we teach or train the machine using data that is well-labelled. Which means some data is already tagged with the correct answer. After that, the machine is provided with a new set of examples(data) so that the supervised learning algorithm analyses the training data(set of training examples) and produces a correct outcome from labeled data.
For example, a labeled dataset of images of Elephant, Camel and Cow would have each image tagged with either “Elephant” , “Camel”or “Cow.”
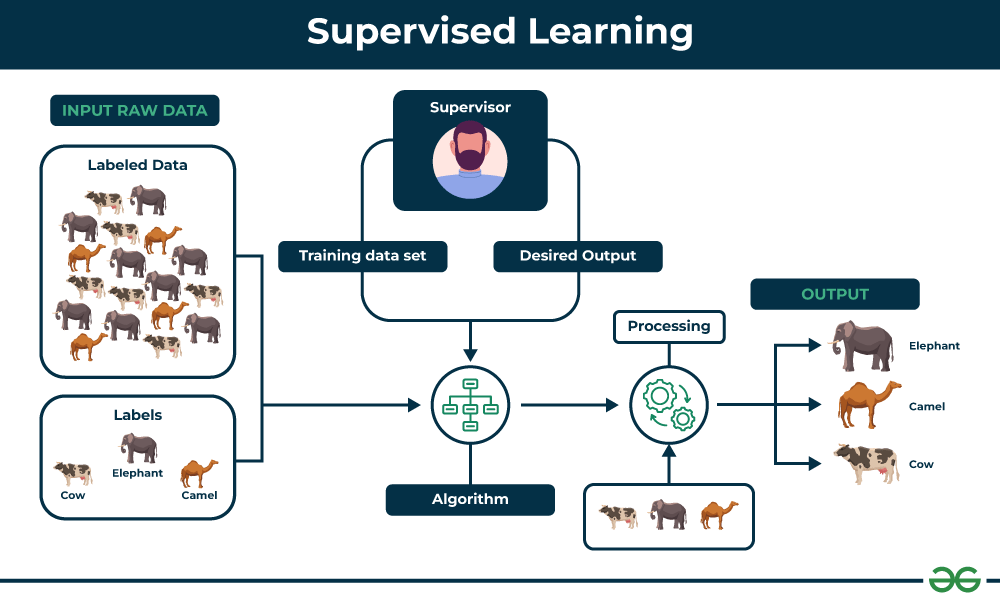
Key Points:
- Supervised learning involves training a machine from labeled data.
- Labeled data consists of examples with the correct answer or classification.
- The machine learns the relationship between inputs (fruit images) and outputs (fruit labels).
- The trained machine can then make predictions on new, unlabeled data.
Example:
Let’s say you have a fruit basket that you want to identify. The machine would first analyze the image to extract features such as its shape, color, and texture. Then, it would compare these features to the features of the fruits it has already learned about. If the new image’s features are most similar to those of an apple, the machine would predict that the fruit is an apple.
For instance, suppose you are given a basket filled with different kinds of fruits. Now the first step is to train the machine with all the different fruits one by one like this:
- If the shape of the object is rounded and has a depression at the top, is red in color, then it will be labeled as –Apple.
- If the shape of the object is a long curving cylinder having Green-Yellow color, then it will be labeled as –Banana.
Now suppose after training the data, you have given a new separate fruit, say Banana from the basket, and asked to identify it.
Since the machine has already learned the things from previous data and this time has to use it wisely. It will first classify the fruit with its shape and color and would confirm the fruit name as BANANA and put it in the Banana category. Thus the machine learns the things from training data(basket containing fruits) and then applies the knowledge to test data(new fruit).
Types of Supervised Learning
Supervised learning is classified into two categories of algorithms:
- Regression: A regression problem is when the output variable is a real value, such as “dollars” or “weight”.
- Classification: A classification problem is when the output variable is a category, such as “Red” or “blue” , “disease” or “no disease”.
Supervised learning deals with or learns with “labeled” data. This implies that some data is already tagged with the correct answer.
1- Regression
Regression is a type of supervised learning that is used to predict continuous values, such as house prices, stock prices, or customer churn. Regression algorithms learn a function that maps from the input features to the output value.
Some common regression algorithms include:
- Linear Regression
- Polynomial Regression
- Support Vector Machine Regression
- Decision Tree Regression
- Random Forest Regression
2- Classification
Classification is a type of supervised learning that is used to predict categorical values, such as whether a customer will churn or not, whether an email is spam or not, or whether a medical image shows a tumor or not. Classification algorithms learn a function that maps from the input features to a probability distribution over the output classes.
Some common classification algorithms include:
- Logistic Regression
- Support Vector Machines
- Decision Trees
- Random Forests
- Naive Baye
Evaluating Supervised Learning Models
Evaluating supervised learning models is an important step in ensuring that the model is accurate and generalizable. There are a number of different metrics that can be used to evaluate supervised learning models, but some of the most common ones include:
For Regression
- Mean Squared Error (MSE): MSE measures the average squared difference between the predicted values and the actual values. Lower MSE values indicate better model performance.
- Root Mean Squared Error (RMSE): RMSE is the square root of MSE, representing the standard deviation of the prediction errors. Similar to MSE, lower RMSE values indicate better model performance.
- Mean Absolute Error (MAE): MAE measures the average absolute difference between the predicted values and the actual values. It is less sensitive to outliers compared to MSE or RMSE.
- R-squared (Coefficient of Determination): R-squared measures the proportion of the variance in the target variable that is explained by the model. Higher R-squared values indicate better model fit.
For Classification
- Accuracy: Accuracy is the percentage of predictions that the model makes correctly. It is calculated by dividing the number of correct predictions by the total number of predictions.
- Precision: Precision is the percentage of positive predictions that the model makes that are actually correct. It is calculated by dividing the number of true positives by the total number of positive predictions.
- Recall: Recall is the percentage of all positive examples that the model correctly identifies. It is calculated by dividing the number of true positives by the total number of positive examples.
- F1 score: The F1 score is a weighted average of precision and recall. It is calculated by taking the harmonic mean of precision and recall.
- Confusion matrix: A confusion matrix is a table that shows the number of predictions for each class, along with the actual class labels. It can be used to visualize the performance of the model and identify areas where the model is struggling.
Applications of Supervised learning
Supervised learning can be used to solve a wide variety of problems, including:
- Spam filtering: Supervised learning algorithms can be trained to identify and classify spam emails based on their content, helping users avoid unwanted messages.
- Image classification: Supervised learning can automatically classify images into different categories, such as animals, objects, or scenes, facilitating tasks like image search, content moderation, and image-based product recommendations.
- Medical diagnosis: Supervised learning can assist in medical diagnosis by analyzing patient data, such as medical images, test results, and patient history, to identify patterns that suggest specific diseases or conditions.
- Fraud detection: Supervised learning models can analyze financial transactions and identify patterns that indicate fraudulent activity, helping financial institutions prevent fraud and protect their customers.
- Natural language processing (NLP): Supervised learning plays a crucial role in NLP tasks, including sentiment analysis, machine translation, and text summarization, enabling machines to understand and process human language effectively.
Advantages of Supervised learning
- Supervised learning allows collecting data and produces data output from previous experiences.
- Helps to optimize performance criteria with the help of experience.
- Supervised machine learning helps to solve various types of real-world computation problems.
- It performs classification and regression tasks.
- It allows estimating or mapping the result to a new sample.
- We have complete control over choosing the number of classes we want in the training data.
Disadvantages of Supervised learning
- Classifying big data can be challenging.
- Training for supervised learning needs a lot of computation time. So, it requires a lot of time.
- Supervised learning cannot handle all complex tasks in Machine Learning.
- Computation time is vast for supervised learning.
- It requires a labelled data set.
- It requires a training process.
What is Unsupervised learning?
Unsupervised learning is a type of machine learning that learns from unlabeled data. This means that the data does not have any pre-existing labels or categories. The goal of unsupervised learning is to discover patterns and relationships in the data without any explicit guidance.
Unsupervised learning is the training of a machine using information that is neither classified nor labeled and allowing the algorithm to act on that information without guidance. Here the task of the machine is to group unsorted information according to similarities, patterns, and differences without any prior training of data.
Unlike supervised learning, no teacher is provided that means no training will be given to the machine. Therefore the machine is restricted to find the hidden structure in unlabeled data by itself.
You can use unsupervised learning to examine the animal data that has been gathered and distinguish between several groups according to the traits and actions of the animals. These groupings might correspond to various animal species, providing you to categorize the creatures without depending on labels that already exist.

Key Points
- Unsupervised learning allows the model to discover patterns and relationships in unlabeled data.
- Clustering algorithms group similar data points together based on their inherent characteristics.
- Feature extraction captures essential information from the data, enabling the model to make meaningful distinctions.
- Label association assigns categories to the clusters based on the extracted patterns and characteristics.
Example
Imagine you have a machine learning model trained on a large dataset of unlabeled images, containing both dogs and cats. The model has never seen an image of a dog or cat before, and it has no pre-existing labels or categories for these animals. Your task is to use unsupervised learning to identify the dogs and cats in a new, unseen image.
For instance, suppose it is given an image having both dogs and cats which it has never seen.
Thus the machine has no idea about the features of dogs and cats so we can’t categorize it as ‘dogs and cats ‘. But it can categorize them according to their similarities, patterns, and differences, i.e., we can easily categorize the above picture into two parts. The first may contain all pics having dogs in them and the second part may contain all pics having cats in them. Here you didn’t learn anything before, which means no training data or examples.
It allows the model to work on its own to discover patterns and information that was previously undetected. It mainly deals with unlabelled data.
Types of Unsupervised Learning
Unsupervised learning is classified into two categories of algorithms:
- Clustering: A clustering problem is where you want to discover the inherent groupings in the data, such as grouping customers by purchasing behavior.
- Association: An association rule learning problem is where you want to discover rules that describe large portions of your data, such as people that buy X also tend to buy Y.
Clustering
Clustering is a type of unsupervised learning that is used to group similar data points together. Clustering algorithms work by iteratively moving data points closer to their cluster centers and further away from data points in other clusters.
- Exclusive (partitioning)
- Agglomerative
- Overlapping
- Probabilistic
Clustering Types:-
- Hierarchical clustering
- K-means clustering
- Principal Component Analysis
- Singular Value Decomposition
- Independent Component Analysis
- Gaussian Mixture Models (GMMs)
- Density-Based Spatial Clustering of Applications with Noise (DBSCAN)
Association rule learning
Association rule learning is a type of unsupervised learning that is used to identify patterns in a data. Association rule learning algorithms work by finding relationships between different items in a dataset.
Some common association rule learning algorithms include:
- Apriori Algorithm
- Eclat Algorithm
- FP-Growth Algorithm
Evaluating Non-Supervised Learning Models
Evaluating non-supervised learning models is an important step in ensuring that the model is effective and useful. However, it can be more challenging than evaluating supervised learning models, as there is no ground truth data to compare the model’s predictions to.
There are a number of different metrics that can be used to evaluate non-supervised learning models, but some of the most common ones include:
- Silhouette score: The silhouette score measures how well each data point is clustered with its own cluster members and separated from other clusters. It ranges from -1 to 1, with higher scores indicating better clustering.
- Calinski-Harabasz score: The Calinski-Harabasz score measures the ratio between the variance between clusters and the variance within clusters. It ranges from 0 to infinity, with higher scores indicating better clustering.
- Adjusted Rand index: The adjusted Rand index measures the similarity between two clusterings. It ranges from -1 to 1, with higher scores indicating more similar clusterings.
- Davies-Bouldin index: The Davies-Bouldin index measures the average similarity between clusters. It ranges from 0 to infinity, with lower scores indicating better clustering.
- F1 score: The F1 score is a weighted average of precision and recall, which are two metrics that are commonly used in supervised learning to evaluate classification models. However, the F1 score can also be used to evaluate non-supervised learning models, such as clustering models.
Application of Unsupervised learning
Non-supervised learning can be used to solve a wide variety of problems, including:
- Anomaly detection: Unsupervised learning can identify unusual patterns or deviations from normal behavior in data, enabling the detection of fraud, intrusion, or system failures.
- Scientific discovery: Unsupervised learning can uncover hidden relationships and patterns in scientific data, leading to new hypotheses and insights in various scientific fields.
- Recommendation systems: Unsupervised learning can identify patterns and similarities in user behavior and preferences to recommend products, movies, or music that align with their interests.
- Customer segmentation: Unsupervised learning can identify groups of customers with similar characteristics, allowing businesses to target marketing campaigns and improve customer service more effectively.
- Image analysis: Unsupervised learning can group images based on their content, facilitating tasks such as image classification, object detection, and image retrieval.
Advantages of Unsupervised learning
- It does not require training data to be labeled.
- Dimensionality reduction can be easily accomplished using unsupervised learning.
- Capable of finding previously unknown patterns in data.
- Unsupervised learning can help you gain insights from unlabeled data that you might not have been able to get otherwise.
- Unsupervised learning is good at finding patterns and relationships in data without being told what to look for. This can help you learn new things about your data.
Disadvantages of Unsupervised learning
- Difficult to measure accuracy or effectiveness due to lack of predefined answers during training.
- The results often have lesser accuracy.
- The user needs to spend time interpreting and label the classes which follow that classification.
- Unsupervised learning can be sensitive to data quality, including missing values, outliers, and noisy data.
- Without labeled data, it can be difficult to evaluate the performance of unsupervised learning models, making it challenging to assess their effectiveness.
Supervised vs. Unsupervised Machine Learning
| Parameters |
Supervised machine learning |
Unsupervised machine learning |
| Input Data |
Algorithms are trained using labeled data. |
Algorithms are used against data that is not labeled |
| Computational Complexity |
Simpler method |
Computationally complex |
| Accuracy |
Highly accurate |
Less accurate |
| No. of classes |
No. of classes is known |
No. of classes is not known |
| Data Analysis |
Uses offline analysis |
Uses real-time analysis of data |
| Algorithms used |
Linear and Logistics regression, Random forest, multi-class classification, decision tree, Support Vector Machine, Neural Network, etc.
|
K-Means clustering, Hierarchical clustering, KNN, Apriori algorithm, etc.
|
| Output |
Desired output is given. |
Desired output is not given. |
| Training data |
Use training data to infer model. |
No training data is used. |
| Complex model |
It is not possible to learn larger and more complex models than with supervised learning. |
It is possible to learn larger and more complex models with unsupervised learning. |
| Model |
We can test our model. |
We can not test our model. |
| Called as |
Supervised learning is also called classification. |
Unsupervised learning is also called clustering. |
| Example |
Example: Optical character recognition. |
Example: Find a face in an image. |
|
Supervision
|
supervised learning needs supervision to train the model.
|
Unsupervised learning does not need any supervision to train the model.
|
Conclusion
Supervised and unsupervised learning are two powerful tools that can be used to solve a wide variety of problems. Supervised learning is well-suited for tasks where the desired output is known, while unsupervised learning is well-suited for tasks where the desired output is unknown.
Frequently asked Question(FAQ’s)
1. What is the difference between supervised and unsupervised machine language?
Supervised and unsupervised learning are two fundamental approaches to machine learning that differ in their training data and learning objectives.
- Supervised learning involves training a machine learning model on a labeled dataset, where each data point has a corresponding label or output value. The algorithm learns to map the input data to the desired output, allowing it to make predictions for new, unseen data.
- Unsupervised learning, on the other hand, deals with unlabeled datasets, where the data points do not have associated labels or output values.
2. What is supervised learning?
Supervised learning is a type of machine learning where the algorithm is trained on a labeled dataset, where each data point has a corresponding label or output value. The algorithm learns to map the input data to the desired output, allowing it to make predictions for new, unseen data.
3. What are common supervised learning algorithms?
Common supervised learning algorithms include:
- Classification: Used to assign categories to data points. Examples include support vector machines (SVMs), logistic regression, and decision trees.
- Regression: Used to predict continuous numerical values. Examples include linear regression, polynomial regression, and ridge regression.
4. What are common unsupervised learning algorithms?
Common unsupervised learning algorithms include:
- Clustering: Grouping data points into clusters based on their similarity. Examples include k-means clustering and hierarchical clustering.
- Dimensionality reduction: Reducing the number of features in a dataset while preserving the most important information. Examples include principal component analysis (PCA) and autoencoders.
5. What is unsupervised learning?
Unsupervised learning is a type of machine learning where the algorithm is trained on an unlabeled dataset, where the data points do not have corresponding labels or output values. The algorithm learns to identify patterns and structures in the data without explicit guidance.
6. When to use supervised learning vs. unsupervised learning?
Use supervised learning when you have a labeled dataset and want to make predictions for new data. Use unsupervised learning when you have an unlabeled dataset and want to identify patterns or structures in the data.
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...