Structures of Directory in Operating System
Last Updated :
19 Oct, 2023
A directory is a container that is used to contain folders and files. It organizes files and folders in a hierarchical manner.

Following are the logical structures of a directory, each providing a solution to the problem faced in previous type of directory structure.
1) Single-level directory:
The single-level directory is the simplest directory structure. In it, all files are contained in the same directory which makes it easy to support and understand.
A single level directory has a significant limitation, however, when the number of files increases or when the system has more than one user. Since all the files are in the same directory, they must have a unique name. If two users call their dataset test, then the unique name rule violated.

Advantages:
- Since it is a single directory, so its implementation is very easy.
- If the files are smaller in size, searching will become faster.
- The operations like file creation, searching, deletion, updating are very easy in such a directory structure.
- Logical Organization: Directory structures help to logically organize files and directories in a hierarchical structure. This provides an easy way to navigate and manage files, making it easier for users to access the data they need.
- Increased Efficiency: Directory structures can increase the efficiency of the file system by reducing the time required to search for files. This is because directory structures are optimized for fast file access, allowing users to quickly locate the file they need.
- Improved Security: Directory structures can provide better security for files by allowing access to be restricted at the directory level. This helps to prevent unauthorized access to sensitive data and ensures that important files are protected.
- Facilitates Backup and Recovery: Directory structures make it easier to backup and recover files in the event of a system failure or data loss. By storing related files in the same directory, it is easier to locate and backup all the files that need to be protected.
- Scalability: Directory structures are scalable, making it easy to add new directories and files as needed. This helps to accommodate growth in the system and makes it easier to manage large amounts of data.
Disadvantages:
- There may chance of name collision because two files can have the same name.
- Searching will become time taking if the directory is large.
- This can not group the same type of files together.
2) Two-level directory:
As we have seen, a single level directory often leads to confusion of files names among different users. The solution to this problem is to create a separate directory for each user.
In the two-level directory structure, each user has their own user files directory (UFD). The UFDs have similar structures, but each lists only the files of a single user. System’s master file directory (MFD) is searched whenever a new user id is created.
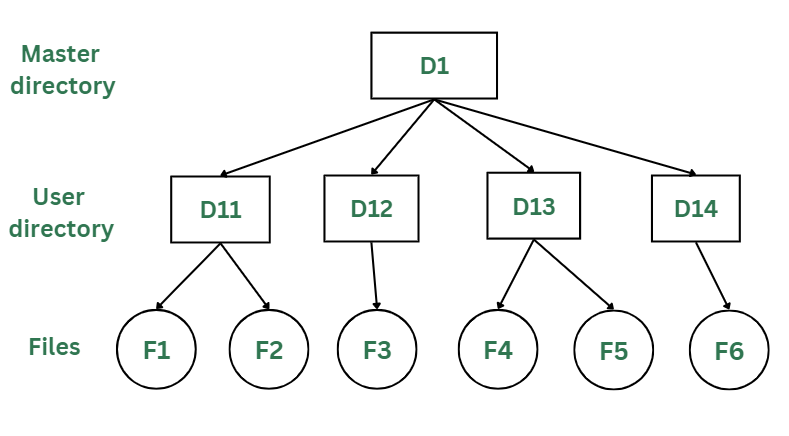
Two-Levels Directory Structure
Advantages:
- The main advantage is there can be more than two files with same name, and would be very helpful if there are multiple users.
- A security would be there which would prevent user to access other user’s files.
- Searching of the files becomes very easy in this directory structure.
Disadvantages:
- As there is advantage of security, there is also disadvantage that the user cannot share the file with the other users.
- Unlike the advantage users can create their own files, users don’t have the ability to create subdirectories.
- Scalability is not possible because one use can’t group the same types of files together.
3) Tree Structure/ Hierarchical Structure:
Tree directory structure of operating system is most commonly used in our personal computers. User can create files and subdirectories too, which was a disadvantage in the previous directory structures.
This directory structure resembles a real tree upside down, where the root directory is at the peak. This root contains all the directories for each user. The users can create subdirectories and even store files in their directory.
A user do not have access to the root directory data and cannot modify it. And, even in this directory the user do not have access to other user’s directories. The structure of tree directory is given below which shows how there are files and subdirectories in each user’s directory.
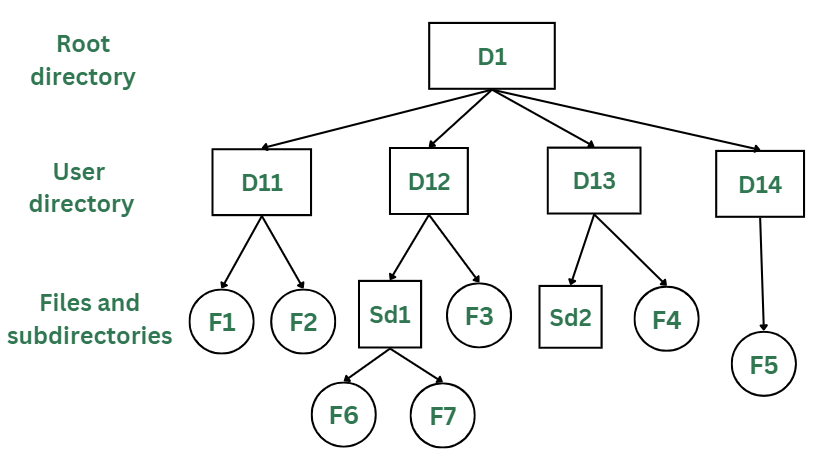
Tree/Hierarchical Directory Structure
Advantages:
- This directory structure allows subdirectories inside a directory.
- The searching is easier.
- File sorting of important and unimportant becomes easier.
- This directory is more scalable than the other two directory structures explained.
Disadvantages:
- As the user isn’t allowed to access other user’s directory, this prevents the file sharing among users.
- As the user has the capability to make subdirectories, if the number of subdirectories increase the searching may become complicated.
- Users cannot modify the root directory data.
- If files do not fit in one, they might have to be fit into other directories.
4) Acyclic Graph Structure:
As we have seen the above three directory structures, where none of them have the capability to access one file from multiple directories. The file or the subdirectory could be accessed through the directory it was present in, but not from the other directory.
This problem is solved in acyclic graph directory structure, where a file in one directory can be accessed from multiple directories. In this way, the files could be shared in between the users. It is designed in a way that multiple directories point to a particular directory or file with the help of links.
In the below figure, this explanation can be nicely observed, where a file is shared between multiple users. If any user makes a change, it would be reflected to both the users.

Acyclic Graph Structure
Advantages:
- Sharing of files and directories is allowed between multiple users.
- Searching becomes too easy.
- Flexibility is increased as file sharing and editing access is there for multiple users.
Disadvantages:
- Because of the complex structure it has, it is difficult to implement this directory structure.
- The user must be very cautious to edit or even deletion of file as the file is accessed by multiple users.
- If we need to delete the file, then we need to delete all the references of the file inorder to delete it permanently.
FAQs on Directory Structure
Q1. What is a root Directory?
Answer:
A root directory is a fundamental concept in directory structure of OS. It is a parent directory that is a top-level directory organised in a hierarchical manner and is represented by a forward slash “/” in a unix like systems & a backslash in windows “\”.
Q2. What is a purpose of a directory structure?
Answer:
The sole purpose of a directory structure is to provide a way to store and oragnised files & data in an efficient manner so that access and management of all the files can be done by the user in the simplest and productive manner.
Q3. What is a sub-directory ?
Answer:
A sub-directory is a directory inside another directory. Inside a directory structure, a user can create many directories inside a directory. These are called sub-directories.
Q4. What are some common directory structures used in Operating System?
Answer:
Most common directory structures used to store and organise files are – Single-Level, Two-Level, tree-like directory structures. Tree structure is generally used in modern personal computers.
Q5. What are most common system calls made while managing files through a directory structure?
Answer:
Following system calls are majorly used :
- mkdir() : this system call is made when creating a new file through GUI or through command line.
- open() : This call is made when opening a file inside a directory structure
- close() : This call is made when we close a file in a directory structure
- unlink() : This call is made to unlike a file from other directories before deleting it
- rmdir : This call is made to remove a directory from a file system.
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...