SQL Server is a versatile database and it is the most used Relational Database that is used across many software industries. In this article, let us see about the SQL Lock table in SQL Server by taking some practical examples. As it is meeting Atomicity(A), Consistency(C), Isolation(I), and Durability(D) requirements it is called a relational database. In order to maintain ACID mechanisms, in SQL Server, a lock is maintained.
By using Azure Data Studio, let us see the concepts of the Lock mechanism by starting with creating the database, table creation, locks, etc. Azure Data Studio works well for Windows 10, Mac, and Linux environments. It can be installed from here.
Database creation :
Command to create the database. Here GEEKSFORGEEKS is the db name.
--CREATE DATABASE <dbname>;
Create Database GEEKSFORGEEKS:
Make the database active
USE GEEKSFORGEEKS;

Once the database is made active, at the top, the database name will be shown
Adding the tables to the database :
Creating a table with Primary Key. Here ID is a PRIMARY KEY meaning each author will have their own ID
CREATE TABLE Authors (
ID INT NOT NULL PRIMARY KEY,
<other column name1> <datatype> <null/not null>,
..........
);
If explicitly “NOT NULL” is specified, that column should have values. If not specified, it is by default “NULL”.

“Authors” named table is created under “GEEKSFORGEEKS” database
Inserting rows in the table :
There will be scenarios like either we can add all columns or few column values to the table. The reason is some columns might require null values by default.
Example 1 :
INSERT INTO <table_name> (column1, column2, column3, ...) VALUES (value1, value2, value3, ...);
Here we are taking into consideration the mentioned columns and hence only their required values are inserted by the above query.
Example 2 :
INSERT INTO <table_name> VALUES (value1, value2, value3, ...);
Here we are not specifying any columns means, all the values to all the columns need to be inserted.
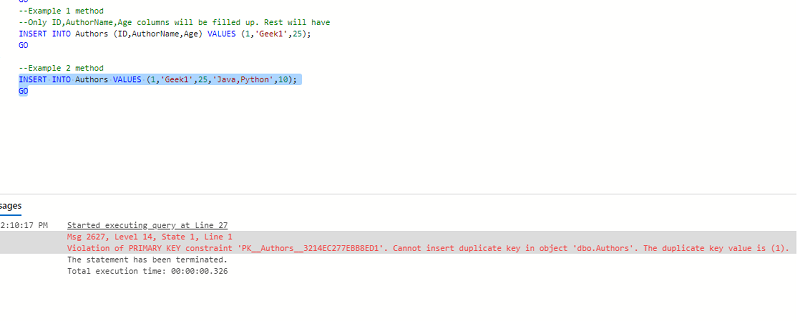
Violation of PRIMARY KEY constraint 'PK__Authors__3214EC277EBB8ED1'.
Cannot insert duplicate key in object 'dbo.Authors'. The duplicate key value is (1).
The above errors occurred in the above screenshot shows that “ID” column is unique and it should not have duplicate values
Now, let us correct that and query the table by using:
SELECT * FROM <tablename>

Clear output for the applied Example 1 and Example 2 methods
It is observed that Row 1 is having ‘Null’ values in the place of ‘Skillsets’ and ‘NumberOfPosts’ column. The reason is as we have not specified values for those columns, it has taken default Null values.
SQL Server is a relational database, data consistency is an important mechanism, and it can be done by means of SQL Locks. A lock is established in SQL Server when a transaction starts, and it is released when it is ended.. There are different types of locks are there.
- Shared (S) Locks: When the object needs to be read, this type of lock will occur, but this is not harmful.
- Exclusive (X) Locks: It prevents other transactions like inserting/updating/deleting etc., Hence no modifications can be done on a locked object.
- Update (U) Locks: More or less similar to Exclusive lock but here the operation can be viewed as “read phase” and “write phase”. Especially during the read phase, other transactions are prevented.
- Intent Locks: When SQL Server has the shared (S) lock or exclusive (X) lock on a row, then the intent lock is on the table.
- Regular intent locks: Intent exclusive (IX) , Intent shared (IS), and Intent update (IU).
- Conversion locks: Shared with intent exclusive (SIX), Shared with intent update (SIU), and Update with intent exclusive (UIX).
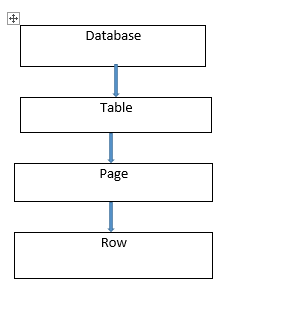
Lock hierarchy starts from Database, then table, then row.
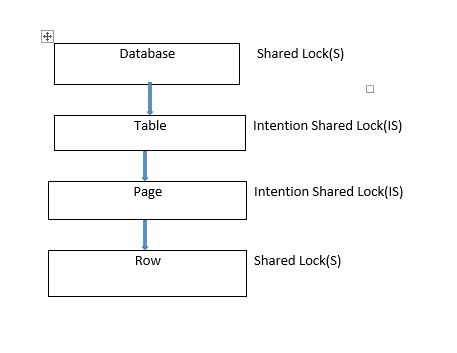
The shared lock on a database level is very much important as it prevents dropping of the database or restoring a database backup over the database in use.
Lock occurrences when there is a “SELECT” statement is issued.
During DML statement execution i.e. either during insert/update/delete.
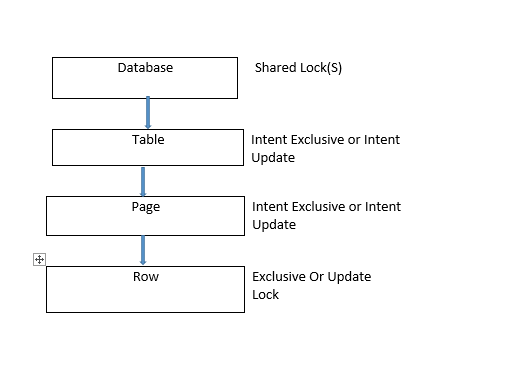
With our example, let us see the locking mechanisms.
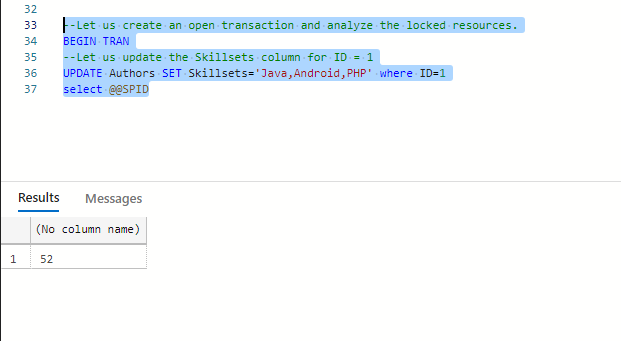
--Let us create an open transaction and analyze the locked resource.
BEGIN TRAN
Let us update the Skillsets column for ID = 1
UPDATE Authors SET Skillsets='Java,Android,PHP' where ID=1
select @@SPID
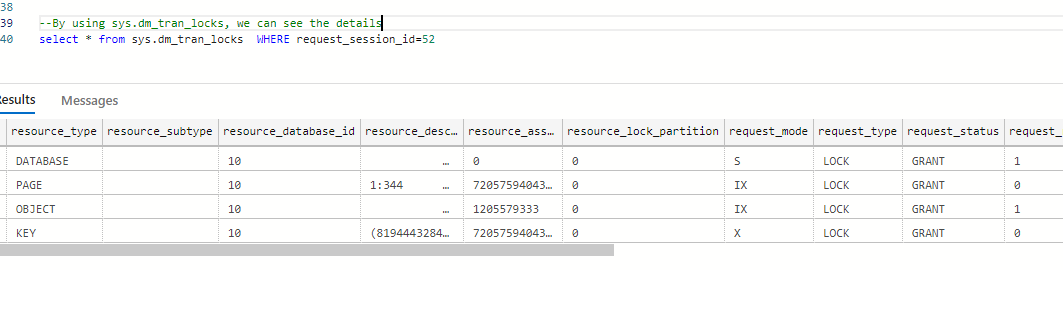
select * from sys.dm_tran_locks WHERE request_session_id=<our session id. here it is 52>
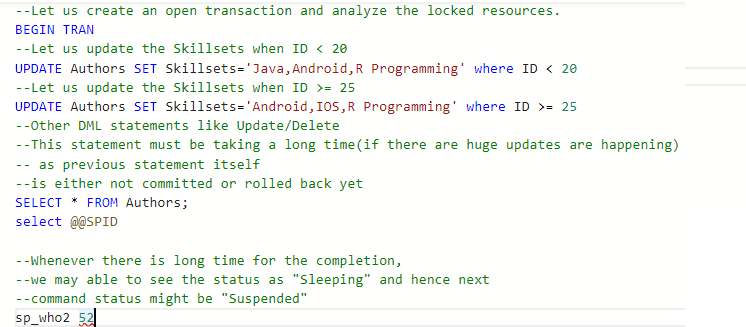
Let us insert some more records(nearly around 100 records) into the table and then using a transaction, let us update few columns as well as parallel apply the select query also
--Let us create an open transaction and analyze the locked resources.
BEGIN TRAN
--Let us update the Skillsets when ID < 20
UPDATE Authors SET Skillsets='Java,Android,R Programming' where ID < 20
--Let us update the Skillsets when ID >= 25
UPDATE Authors SET Skillsets='Android,IOS,R Programming' where ID >= 25
--Other DML statements like Update/Delete. This statement must be taking a long time
--(if there are huge updates are happening) as previous statement itself
--is either not committed or rolled back yet
SELECT * FROM Authors;
select @@SPID
Actually when the earlier command transaction are not yet complete(if there are huge records at least 100 records) and update is happening on each and every row and before completion of it, if we are proceeding for another set of commands like “select”
Then there are possibilities of the status will be “Awaiting” (Queries which are executing) and “Suspended” (Queries which are halt)
How to overcome the so far running process?
KILL <spid> -> Kill the session
(Or) Inside a transaction, after each query, apply
COMMIT -> TO COMMIT THE CHANGES
ROLLBACK -> TO ROLLBACK THE CHANGES
By doing this process, we are enforcing the operation either to get committed or rolled back(depends upon the requirements, it has to be carried out)
But unless we know that the entire process is required or not, we cannot either commit or rollback the transaction.
Alternative way :
By using NOLOCK with SELECT QUERY, we can overcome
SELECT * FROM Authors WITH (NOLOCK);
For SELECT statement status using the sp_who2 command. The query runs without waiting for the UPDATE transaction to be completed successfully and release the locking on the table,
SELECT * FROM Authors WITH (READUNCOMMITTED);
--This way also we can do
Conclusion :
SQL Locks are much important for any RDBMS. SQL Server handles them in the mentioned ways.
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...