Snakebite Python Package For Hadoop HDFS
Last Updated :
14 Oct, 2020
Prerequisite: Hadoop and HDFS
Snakebite is a very popular python package that allows users to access HDFS using some kind of program with python application. The Snakebite Python Package is developed by Spotify. Snakebite also provides a Python client library. The protobuf messages are used by the snakebite client library to directly communicate with the NameNode that stores all the Metadata. All the file permission, logs, location where the data blocks are created all comes under metadata. The CLI i.e. the command-line interface is also available in this snakebite python package that is based on the client library.
Let’s discuss how to install and configure the snakebite package for HDFS.
Requirement:
- Python 2 and python-protobuf 2.4.1 or higher is required for snakebite.
The snakebite library can be installed easily with pip.
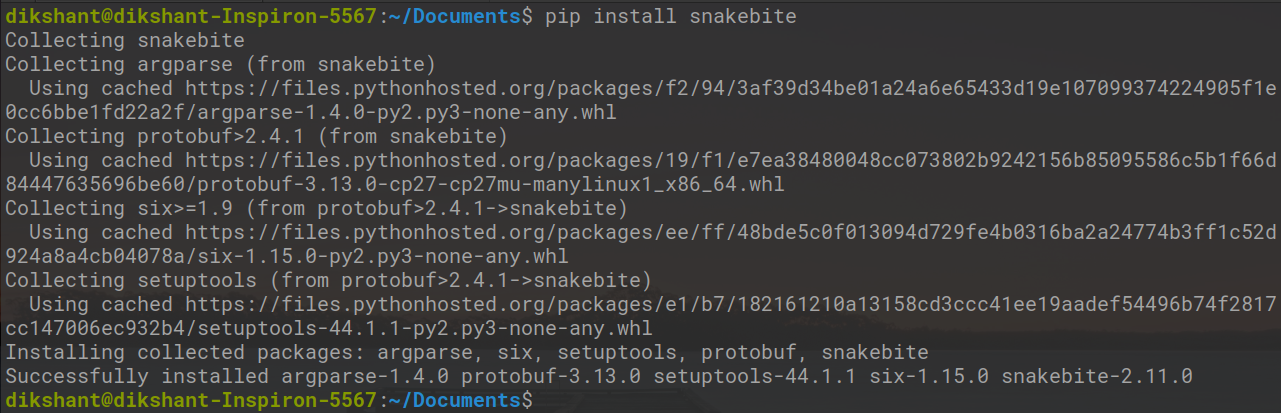
# Make sure you have pip for python version 2 otherwise you will face error while importing module
pip install snakebite
We already have snakebite so the requirement is satisfied.
The Client Library
The client library is built using python and it uses Hadoop RPC protocol and protobuf messages to communicate with the NameNode that handles all the metadata of the cluster. With the help of this client library, the Python applications communicate directly with the HDFS i.e. Hadoop Distributed File System without making any connection with the hdfs dfs using a system call.
Let’s write one simple python program to understand the working of the snakebite python package.
Task: List all the content of the root directory of HDFS using Snakebite client library.
Step1: Create a python file with name list_down_root_dir.py at your desired location in the system.
cd Documents/ # Changing directory to Documents(You can choose as per your requirement)
touch list_down_root_dir.py # touch command is used to create file in linux enviournment.

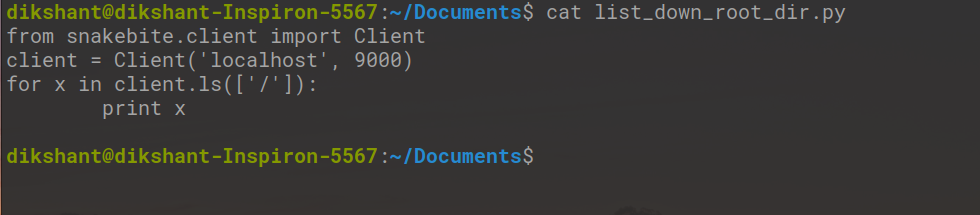
Step2: Write the below code in the list_down_root_dir.py python file.
Python
from snakebite.client import Client
client = Client('localhost', 9000)
for x in client.ls(['/']):
print x
|
Client() method explanation:
The Client() method can accept all the below listed arguments:
- host(string): IP Address of NameNode.
- port(int): RPC port of Namenode.
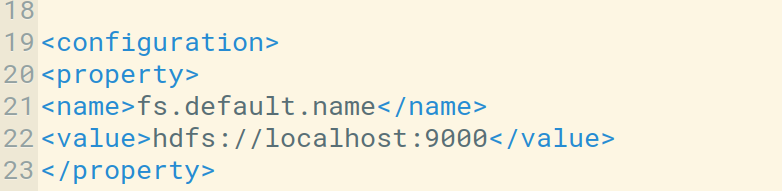
We can check the host and the default port in core-site.xml file. We can also configure it as per our use.
- hadoop_version (int): Hadoop protocol version(by default it is: 9)
- use_trash (boolean): use trash when removing the files.
- effective_use (string): Effective user for the HDFS operations (default user is current user).
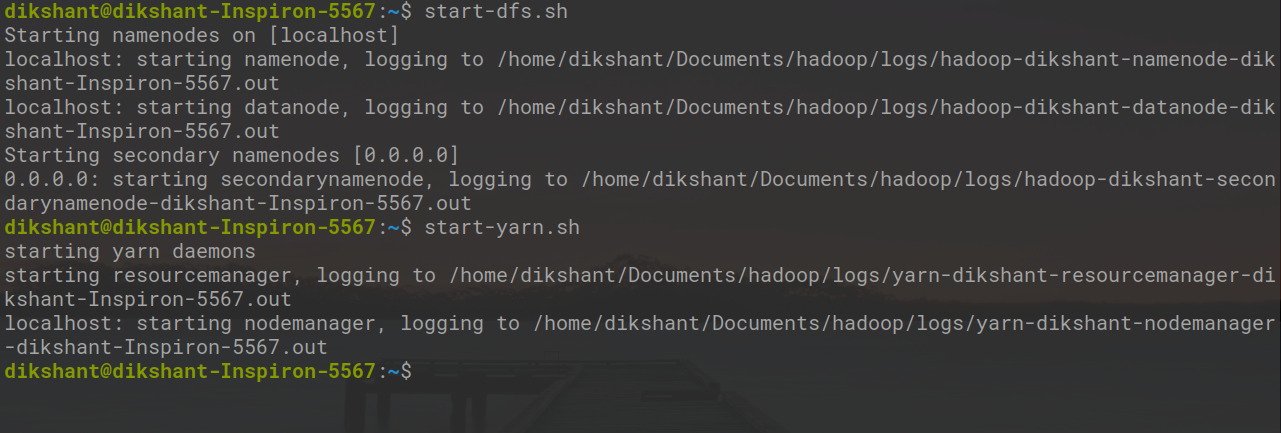
Step3: Start Hadoop Daemon with below command.
start-dfs.sh // start your namenode datanode and secondary namenode
start-yarn.sh // start resourcemanager and nodemanager
Step4: Run the list_down_root_dir.py file and observe the result.
python list_down_root_dir.py
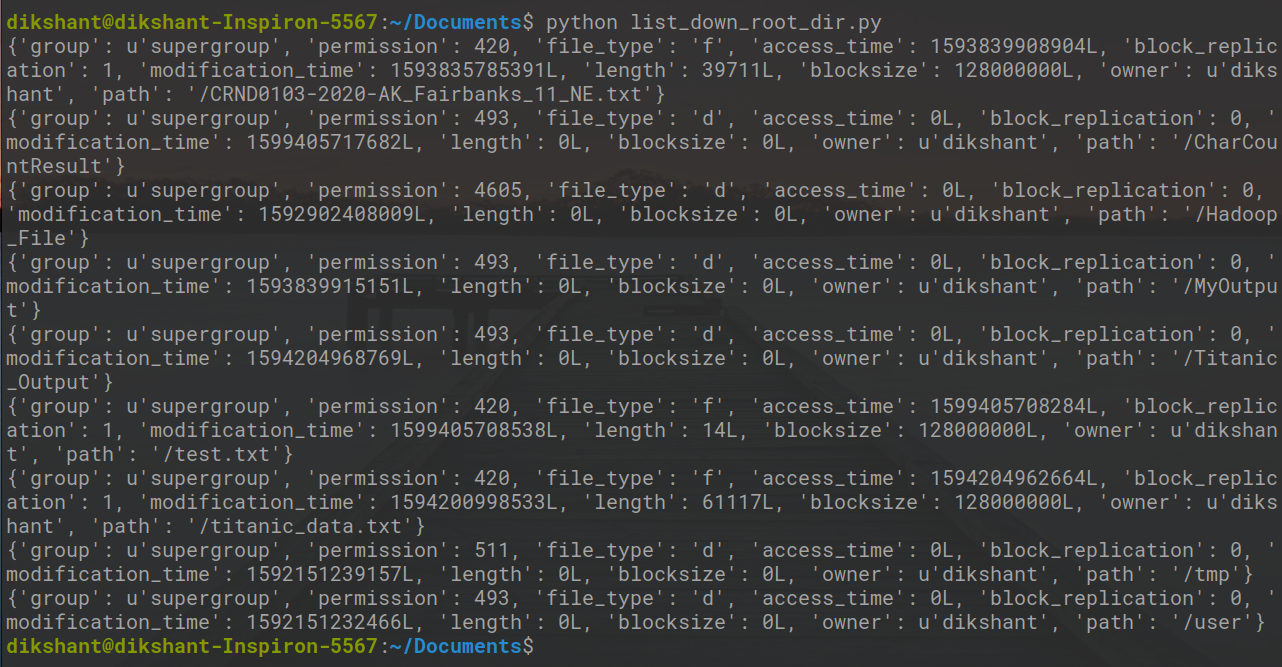
In above image, you can see all the content that is available in root directory of my HDFS.
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...