Short term Memory
Last Updated :
19 Jan, 2023
In the wider community of neurologists and those who are researching the brain, It is agreed that two temporarily distinct processes contribute to the acquisition and expression of brain functions. These variations can result in long-lasting alterations in neuron operations, for instance through activity-dependent changes in synaptic transmission. There is now strong evidence for a complementary process, acting over an intermediate timescale called short-term memory or STM. The process involved in performing tasks requiring temporary storage and manipulation to guide appropriate actions.
Short-term memory, also known as working memory, refers to the temporary storage of information that is being actively used and manipulated in the mind. It is a cognitive system that allows individuals to hold and process information for a short period of time. The information can be in the form of visual, auditory or motor information. The capacity of short-term memory is limited, usually around 7 (+-2) items, and the duration of short-term memory is around 20-30 seconds. The information in short-term memory can be rehearsed or encoded into long-term memory for later recall. The concept of short-term memory is often studied in psychology and cognitive science, and is considered a fundamental aspect of human cognition.
Below are some important issues that should be addressed while studying STM:
- How is neural information selected for storage and temporarily stored in STM for future uses in a temporal sequence of sensorimotor events?
- How can we decide to buffer a large amount of storage if its future use is unknown?
- How can LTM representation of temporal sequence be constructed and how can information selected by STM transferred to LTM?
In this article, we will be discussing LSTM which is a popular use case of STM. We will also be discussed the different variants in LSTM.

Complementary Learning System
In the biological context, the short-term memory is modeled in Hippocampal formation of the Brain, it is present in the complementary learning system of the brain, which contains two parts i.e Hippocampal formation and the neocortex. Here, neocortex acts as traditional long-term memory, but HF rapidly learns distinct observations, forming sparser, non-overlapping, and therefore non-interfering representations, functioning as short-term memory (STM). An architecture inspired by this is Artificial Hippocampal Algorithm, which we discussed in this article.
LSTM
LSTM was proposed by Sepp Hochreiter and Jurgen Schmidhuber in 1990s. The main idea behind this is to correct the failures of RNN in certain situations. It fails to store information for a longer period of time. At times, a reference to certain information stored quite a long time ago is required to predict the current output. But RNNs are absolutely incapable of handling such “long-term dependencies”. Below is the architecture of LSTM:
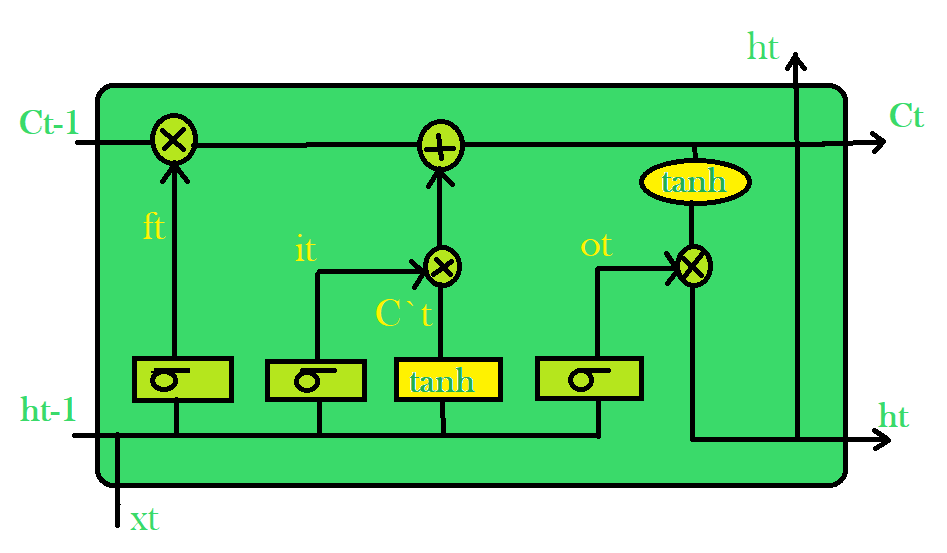
LSTM architecture
Each LSTM cell takes two inputs, the output of the previous cell state Ct-1, the hidden state ht-1, and the input state xt. In the first sigmoid layer, it passed input xt and hidden unit ht-1. The output of this is the forget gate ft. In the next layer, it takes concatenation of input xt and hidden unit ht-1 pass separately through the sigmoid layer and tanh layer and applies pointwise multiplication to combine them, this is the input gate. In the output gate, we only take the sigmoid of the input used in the input gate and apply pointwise multiplication with tanh of cell state. For more details about LSTM please check this article.
In the next section, we will discuss an architecture based on LSTM:
Shallow Attention Fusion & Deep Attention Fusion
Shallow attention fusion treats the LSTM-N (similar to LSTM except memory cell is replaced with memory network) as a separate module that can be readily used in an encoder-decoder architecture, in place of a standard RNN or LSTM. The decoder and encoder both molded by an intra-attention module. Inter attention is triggered when the decoder reads a target token similar to it.

Shallow Attention Fusion
Deep attention fusion combines inter and intra-attention while computing the state update. Here, inter-attention is act as a connection b/w encoder and decoder architecture and unlike the shallow attention fusion, here, the output is generated by decoder instead of intern attention module.

Deep Attention Fusion
IMPORTANT POINTS :
- Short-term memory is a cognitive system that allows individuals to hold and process information for a short period of time.
- The capacity of short-term memory is limited, usually around 7 (+-2) items, and the duration of short-term memory is around 20-30 seconds.
- The information in short-term memory can be rehearsed or encoded into long-term memory for later recall.
- The concept of short-term memory is often studied in psychology and cognitive science, and is considered a fundamental aspect of human cognition.
- Short-term memory is important for a wide range of cognitive tasks such as attention, reasoning, problem-solving, and decision-making.
- The working memory model proposed by Baddeley and Hitch in 1974, proposed that short-term memory is composed of multiple subsystems such as the phonological loop, the visuo-spatial sketchpad, and the central executive
- There are different theories about the nature of short-term memory, such as the modal model and the connectionist model
- The capacity and duration of short-term memory can be improved through techniques such as the method of loci, chunking, and the use of mnemonics.
- Certain factors such as age, stress, sleep deprivation and some medical conditions can affect the function of short-term memory.
- Research in this area is ongoing, and new findings are expected to further our understanding of the cognitive processes involved in short-term memory, and how it can be optimized.
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...