Selfish Round Robin CPU Scheduling
Last Updated :
28 Jan, 2024
Prerequisite – Program for Round Robin scheduling
In the traditional Round Robin scheduling algorithm, all processes were treated equally for processing. The objective of the Selfish Round Robin is to give better service to processes that have been executing for a while than to newcomers. It’s a more logical and superior implementation compared to the normal Round Robin algorithm.
What is the Selfish Round Robin scheduling algorithm?
The Selfish Round Robin (SRR) scheduling algorithm is a modification of the traditional Round Robin algorithm. The objective of SRR is to give better service to processes that have been executing for a while than to newcomers. In SRR, processes in the ready list are partitioned into two lists: NEW and ACCEPTED. The New processes wait while Accepted processes are serviced by the Round Robin. The priority of a new process increases at the rate ‘a’ while the priority of an accepted process increases at the rate ‘b’.
How does SRR scheduling ensure fairness among processes?
A: SRR scheduling ensures fairness among processes by providing each process with an equal amount of CPU time. This is achieved by using a Round Robin approach, where each process is given a time quantum to execute. Once a process completes its time quantum, it is placed at the end of the queue, and the next process is given a chance to execute.
Is SRR scheduling suitable for real-time systems?
A: No, SRR scheduling is not suitable for real-time systems that require strict timing constraints. In such systems, it is essential to ensure that high-priority processes receive CPU time when they need it, which is not possible with SRR scheduling.
Implementation:
- Processes in the ready list are partitioned into two lists: NEW and ACCEPTED.
- The New processes wait while Accepted processes are serviced by the Round Robin.
- Priority of a new process increases at rate ‘a’ while the priority of an accepted process increases at rate ‘b’.
- When the priority of a new process reaches the priority of an accepted process, that new process becomes accepted.
- If all accepted processes finish, the highest priority new process is accepted.
Let’s trace out the general working of this algorithm:-
STEP 1: Assume that initially there are no ready processes, when the first one, A, arrives. It has priority 0, to begin with. Since there are no other accepted processes, A is accepted immediately.
STEP 2: After a while, another process, B, arrives. As long as b / a < 1, B’s priority will eventually catch up to A’s, so it is accepted; now both A and B have the same priority.
STEP 3: All accepted processes share a common priority (which rises at rate b ); that makes this policy easy to implement i.e any new process’s priority is bound to get accepted at some point. So no process has to experience starvation.
STEP 4: Even if b / a > 1, A will eventually finish, and then B can be accepted.
Adjusting the parameters a and b :
-> If b / a >= 1, a new process is not accepted
until all the accepted processes have finished, so SRR becomes FCFS.
-> If b / a = 1, all processes are accepted immediately, so SRR becomes RR.
-> If 0 < b / a < 1, accepted processes are selfish, but not completely.
Example on Selfish Round Robin –
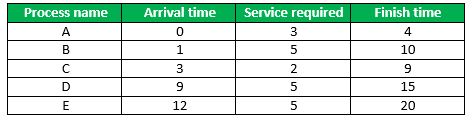
Solution (where a = 2 and b = 1) –
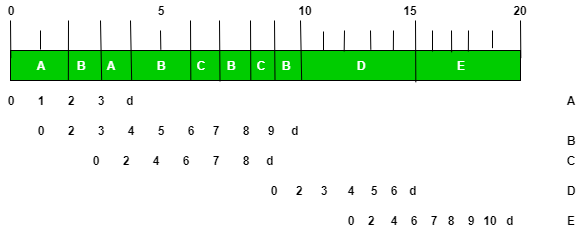
Explanation:
Process A gets accepted as soon as it comes at time t = 0. So its priority is increased only by ‘b’ i.e ‘1’ after each second. B enters at time t = 1 and goes to the waiting queue. So its priority gets increased by ‘a’ i.e. ‘2’ at time t = 2. At this point priority of A = priority of B = 2.
So now both processes A & B are in the accepted queue and are executed in a round-robin fashion. At time t = 3 process C enters the waiting queue. At time t = 6 the priority of process C catches up to the priority of process B and then they start executing in a Round Robin manner. When B finishes execution at time t = 10, D is automatically promoted to the accepted queue.
Similarly, when D finishes execution at time t = 15, E is automatically promoted to the accepted queue.
Advantages:
- Fairness: SRR scheduling ensures fairness among all processes by providing each process with an equal amount of CPU time. This makes it a fairer scheduling algorithm than some other algorithms that prioritize certain processes over others.
- Efficient CPU utilization: SRR scheduling ensures efficient CPU utilization by allowing processes to use only the CPU time they need. This reduces the likelihood of processes being blocked unnecessarily, which can increase overall system throughput.
- Low overhead: SRR scheduling is a simple algorithm that requires little overhead to implement. It is easy to understand and implement, making it a good choice for simple systems.
Disadvantages:
- Selfishness: One of the main disadvantages of SRR scheduling is that it allows processes to be selfish and use all their allotted CPU time, even if they do not need it. This can lead to a situation where some processes hoard CPU time, leading to reduced system performance.
- Poor response time: SRR scheduling can lead to poor response time for interactive processes that require quick user input. This is because these processes may be forced to wait for their quantum of CPU time, even if they only need a small amount of CPU time.
- Poor priority handling: SRR scheduling does not handle process priorities well. All processes are treated equally, regardless of their priority, which can lead to situations where high-priority processes are starved of CPU time.
- Inefficient for real-time systems: SRR scheduling is not suitable for real-time systems that require strict timing constraints. In such systems, it is essential to ensure that high-priority processes receive CPU time when they need it, which is not possible with SRR scheduling.
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...