Scraping websites with Newspaper3k in Python
Last Updated :
23 Jan, 2022
Web Scraping is a powerful tool to gather information from a website. To scrape multiple URLs, we can use a Python library called Newspaper3k. The Newspaper3k package is a Python library used for Web Scraping articles, It is built on top of requests and for parsing lxml. This module is a modified and better version of the Newspaper module which is also used for the same purpose.
Installation:
To install this module type the below command in the terminal.
pip install newspaper3k
Step-by-step Approach:
- First we will define a list containing the URLs or assign a single URL.
- We will create an Article object passing in the parameters such as the name of the URL and optional parameters like language=’en’, for English
- We will then download and parse the file.
- Finally, display the data extracted.
Below are some examples based on the above approach:
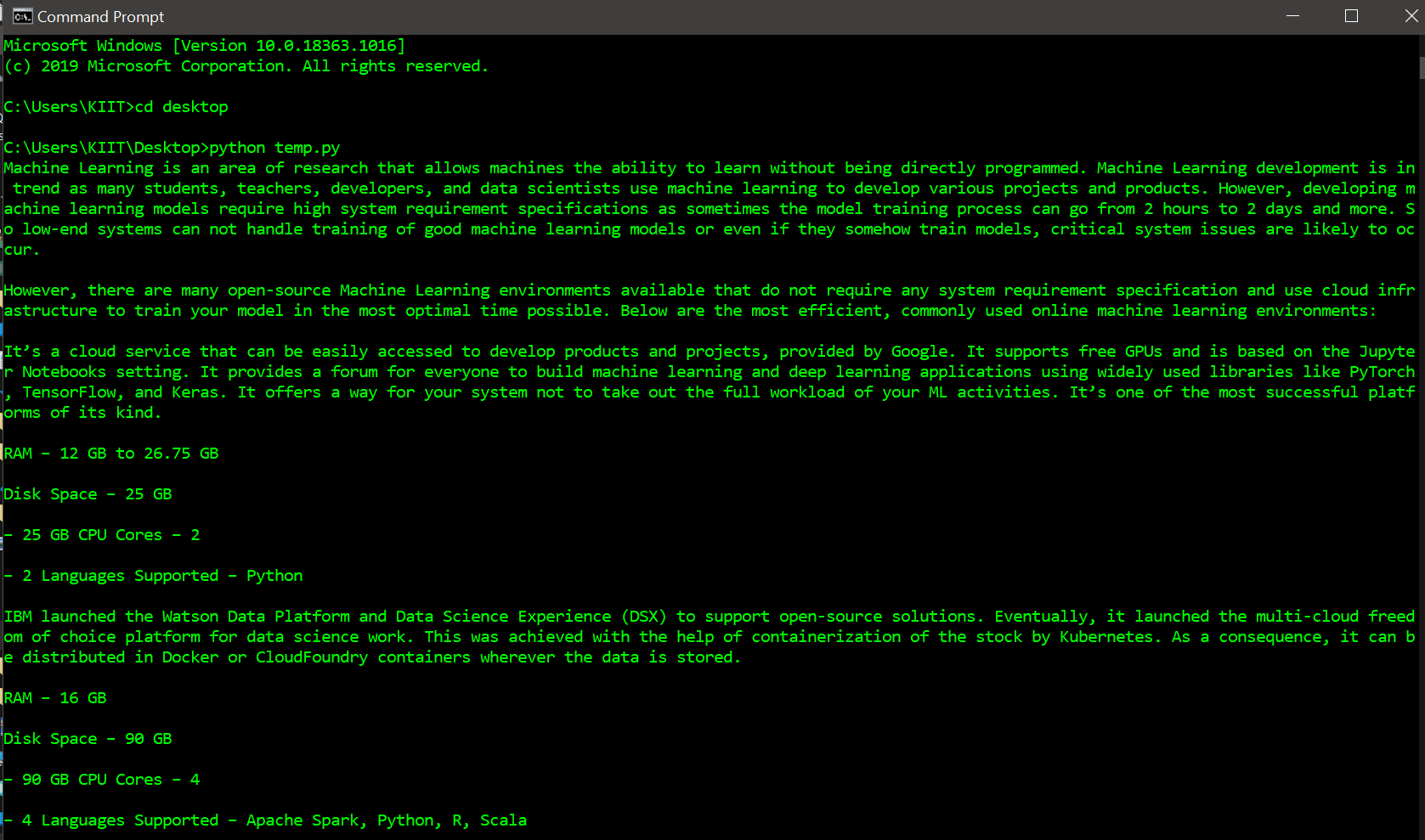
Example 1
Below is a program to scrap data from a given URL.
Python3
import newspaper
url_i = newspaper.Article(url="%s" % (url), language='en')
url_i.download()
url_i.parse()
print(url_i.text)
|
Output:
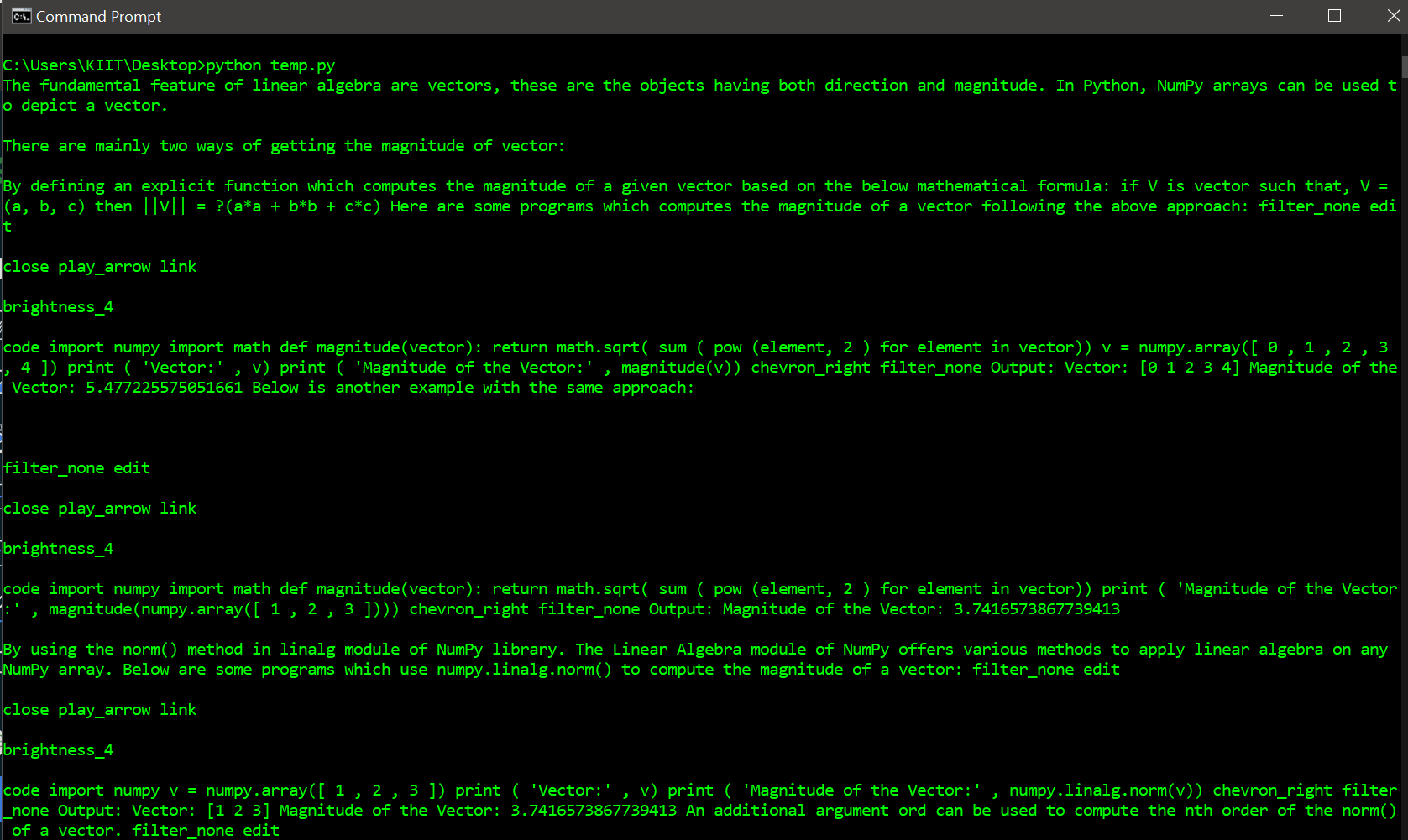
Example 2
Here, we scrap data from multiple URLs and then display it.
Python3
import newspaper
for url in list_of_urls:
url_i = newspaper.Article(url="%s" % (url), language='en')
url_i.download()
url_i.parse()
print(url_i.text)
|
Output:
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...