Web Scraping Tables with Selenium and Python
Last Updated :
11 Dec, 2023
Selenium is the automation software testing tool that obtains the website, performs various actions, or obtains the data from the website. It was chiefly developed for easing the testing work by automating web applications. Nowadays, apart from being used for testing, it can also be used for making tedious work interesting. Do you know that with the help of Selenium, you can also extract data from the table on the website? The answer is Yes, we can easily scrap the table data from the website. What you need to do in order to scrape table data from the website is explained in this article.
Approach to be followed:
Let us consider the simple HTML program containing tables only to understand the approach of scraping the table from the website.
HTML
<!DOCTYPE html>
<html>
<head>
<title>Selenium Table</title>
</head>
<body>
<table border="1">
<thead>
<tr>
<th>Name</th>
<th>Class</th>
</tr>
</thead>
<tbody>
<tr>
<td>Vinayak</td>
<td>12</td>
</tr>
<tr>
<td>Ishita</td>
<td>10</td>
</tr>
</tbody>
</table>
</body>
</html>
|
Browser Output:

Follow the below-given steps:
Once you have created the HTML file, you can follow the below steps and extract data from the table from the website on your own.
- First, declare the web driver
driver=webdriver.Chrome(executable_path=”Declare the path where web driver is installed”)
- Now, open the website from which you want to obtain table data
driver.get("Specify the path of the website")
- Next, you need to find rows in the table
rows=1+len(driver.find_elements_by_xpath("Specify the altered path"))
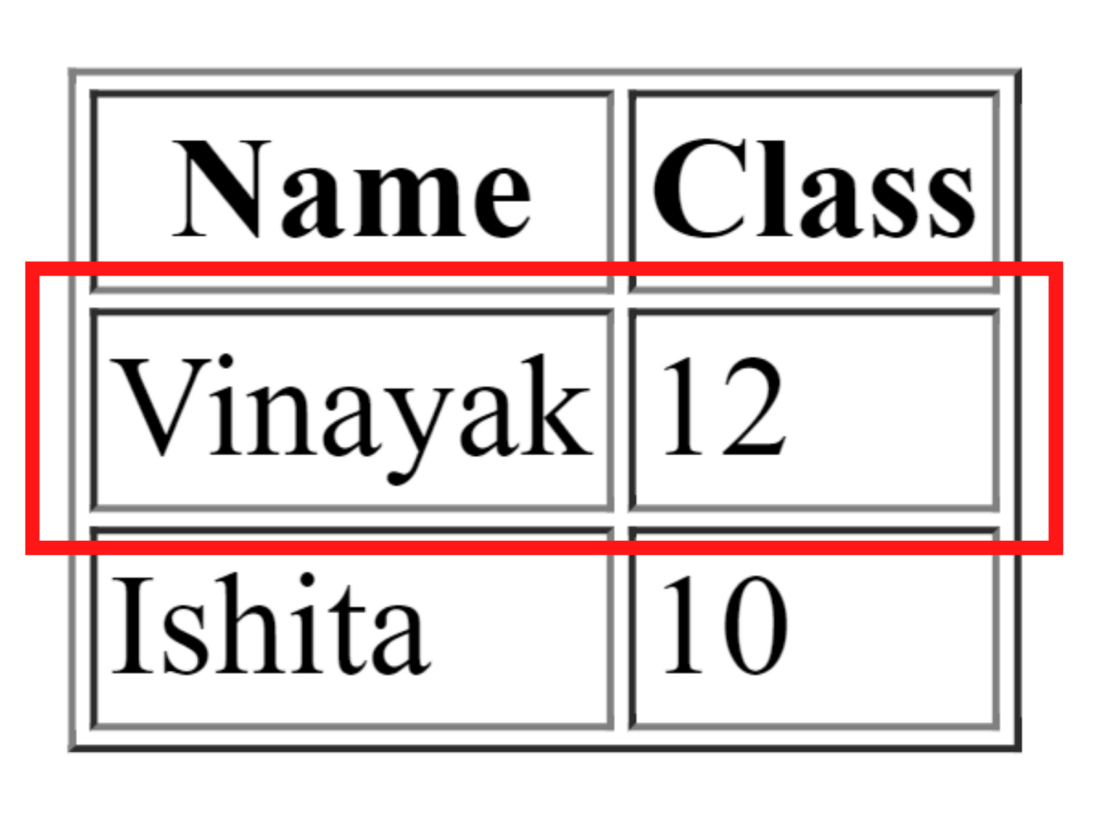
Here, the altered xpath means that if xpath of the row 1 is /html/body/table/tbody/tr[1] then, altered xpath will be /html/body/table/tbody/tr What needs to be done here is to remove the index value of table row.
NOTE: Remember to add 1 to the row’s value for the table header as it was not included while calculating the table rows.
- Further, find columns in the table
cols=len(driver.find_elements_by_xpath("Specify the altered path"))
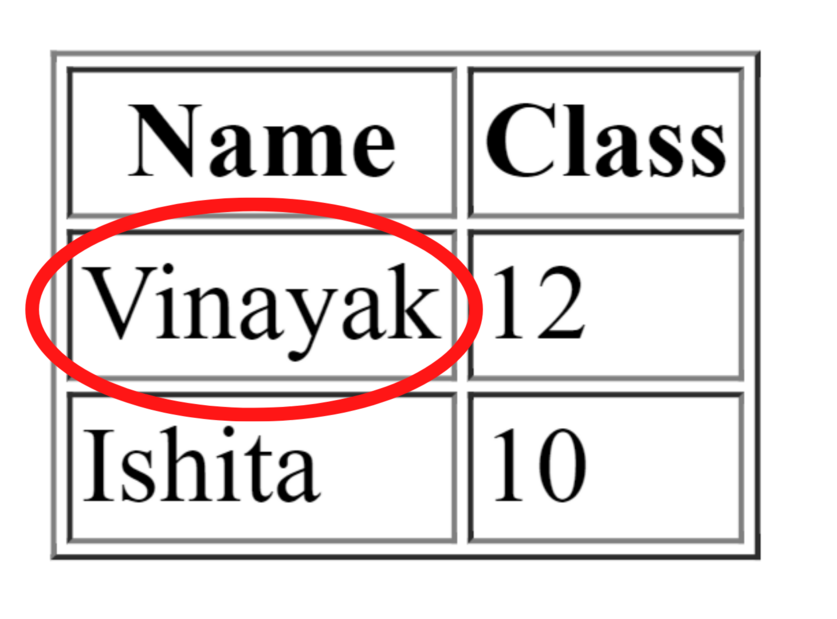
Here, the altered xpath means that if xpath of the column showing output Vinayak is /html/body/table/tbody/tr[1]/td[1] then, altered xpath will be /html/body/table/tbody/tr/td What needs to be done here is to remove the index value of table row and table data.
- Moreover, obtain data from each column of the table body
for r in range(2, rows+1):
for p in range(1, cols+1):
value = driver.find_element_by_xpath("Specify the altered path").text
Here, the altered xpath means that if xpath of the column showing output Vinayak is /html/body/table/tbody/tr[1]/td[1] then, altered xpath will be /html/body/table/tbody/tr[“+str(r)+”]/td[“+str(p)+”] What needs to be done here is to add the str(r) and str(p) for the index value of table row and table data respectively.
- Finally, print data of the table
print(value, end=' ')
print()
How to scrape table data from the website in Selenium?
As we have now seen the approach to be followed to extract the table data while using the automation tool Selenium. Now, let’s see the complete example for the scraping table data from the website. We will use this website to extract its table data in the given below program.
Python
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
driver = webdriver.Chrome(
executable_path="C:\selenium\chromedriver_win32\chromedriver.exe")
driver.get(
sleep(2)
rows = 1+len(driver.find_elements(By.XPATH,
"/html/body/div[3]/div[2]/div/div[1]/div/div/div/article/div[3]/div/table/tbody/tr"))
cols = len(driver.find_elements(By.XPATH,
"/html/body/div[3]/div[2]/div/div[1]/div/div/div/article/div[3]/div/table/tbody/tr[1]/td"))
print(rows)
print(cols)
print("Locators "+" Description")
for r in range(2, rows+1):
for p in range(1, cols+1):
value = driver.find_element(By.XPATH,
"/html/body/div[3]/div[2]/div/div[1]/div/div/div/article/div[3]/div/table/tbody/tr["+str(r)+"]/td["+str(p)+"]").text
print(value, end=' ')
print()
|
Further, run the python code using:
python run.py
Output:
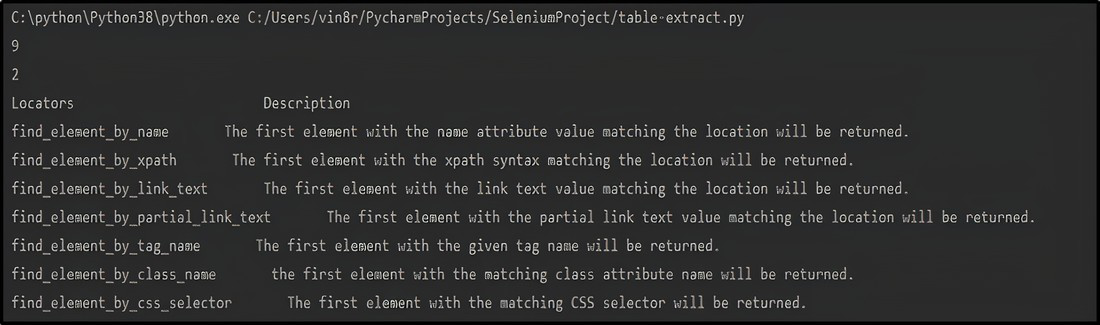
Browser Output:
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...