Scrap Dynamic Content using Docker and Selenium
Last Updated :
20 Mar, 2024
Web scraping is a process of extracting data from websites. This data can be used for various purposes such as research, marketing, analysis, and much more. However, not all websites are created equal, and some websites have dynamic content that requires special handling to scrape. In this article, we will explore how to scrape Dynamic content using Docker and Selenium.
Scrap Dynamic Content using Docker and Selenium
Dynamic websites use JavaScript to load content dynamically, making it difficult to scrape using traditional web scraping techniques. To scrape dynamic content, we need to use a browser automation tool like Selenium. Selenium allows us to automate a browser and interact with the web page just like a user would. This allows us to wait for dynamic content to load and scrape it when it appears.
However, setting up Selenium can be a challenging task. It requires a web driver, which is a separate executable that interacts with the browser. It also requires the correct version of the browser to be installed on the system. This can lead to compatibility issues and make it challenging to set up Selenium across multiple systems.
This is where Docker comes in. Docker allows us to create a container that has all the necessary dependencies, including the web driver and the browser. This container can be run on any system that supports Docker, making it easy to set up Selenium across multiple systems.
Required Modules:
pip install selenium
File Structure:
Here, the geek folder in the image below it is the name of the virtual environment.
Project Structure
To scrap dynamic content using Docker and Selenium, we need to follow the following steps:
Step 1:Install Docker: The first step is to install Docker on your system. You can download and install Docker from the official website.
Step 2: The next step is to create a Dockerfile. A Dockerfile is a text file that contains instructions for building a Docker image. In this file, we need to specify the base image, install the necessary dependencies, and copy our scraping code into the container.
Step 3:Create Requirements.txt File.
Step 4: Paste the below text in Dockerfile.
In this step, we are using the official Python 3.9 image as the base image. We then install the necessary dependencies, including the Chrome web driver, and copy our scraping code into the container. Finally, we set the command to run our scraping code.
FROM python:3.9
RUN CHROMEDRIVER_VERSION=`curl -sS chromedriver.storage.googleapis.com/LATEST_RELEASE` && \
mkdir -p /opt/chromedriver-$CHROMEDRIVER_VERSION && \
curl -sS -o /tmp/chromedriver_linux64.zip http://chromedriver.storage.googleapis.com/$CHROMEDRIVER_VERSION/chromedriver_linux64.zip && \
unzip -qq /tmp/chromedriver_linux64.zip -d /opt/chromedriver-$CHROMEDRIVER_VERSION && \
rm /tmp/chromedriver_linux64.zip && \
chmod +x /opt/chromedriver-$CHROMEDRIVER_VERSION/chromedriver && \
ln -fs /opt/chromedriver-$CHROMEDRIVER_VERSION/chromedriver /usr/local/bin/chromedriver
# Install Google Chrome
RUN curl -sS -o – https://dl-ssl.google.com/linux/linux_signing_key.pub | apt-key add – && \
echo “deb http://dl.google.com/linux/chrome/deb/ stable main” >> /etc/apt/sources.list.d/google-chrome.list && \
apt-get -yqq update && \
apt-get -yqq install google-chrome-stable && \
rm -rf /var/lib/apt/lists/*
RUN apt-get update && apt-get install -y \
unzip \
curl \
gnupg \
&& rm -rf /var/lib/apt/lists/*
RUN curl -sS -o – https://dl-ssl.google.com/linux/linux_signing_key.pub | apt-key add
RUN echo “deb http://dl.google.com/linux/chrome/deb/ stable main” >> /etc/apt/sources.list.d/google-chrome.list
RUN apt-get -y update
RUN apt-get install -y google-chrome-stable
WORKDIR /app
COPY requirements.txt .
RUN pip install -r requirements.txt
COPY scrap.py .
CMD [ “python”, “scrap.py” ]
Step 5: Create a scrap.py file.
We also need to write the scraping code that will be executed inside the Docker container. This code will use Selenium to automate a browser and scrape dynamic content from a website.
Python3
from selenium import webdriver
from selenium.webdriver.common.by import By
option = webdriver.ChromeOptions()
option.add_argument("--disable-gpu")
option.add_argument("--disable-extensions")
option.add_argument("--disable-infobars")
option.add_argument("--start-maximized")
option.add_argument("--disable-notifications")
option.add_argument('--headless')
option.add_argument('--no-sandbox')
option.add_argument('--disable-dev-shm-usage')
driver = webdriver.Chrome(options=option)
headlines = driver.find_elements(By.CLASS_NAME, "indicate-hover")
print("i am running")
for headline in headlines:
print(headline.text)
print("i am closed")
driver.quit()
|
Step 5: Build the Docker image
Once we have created the Dockerfile and the requirements.txt file, we can build the Docker image using the following command
docker build -t news-app .
This command will build the Docker image using the Dockerfile and the requirements.txt file in the current directory. The -t flag specifies the name of the image and the. specifies the build context.
Step 6: Run the Docker Container
Once we have built the Docker image, we can run the Docker container using the following command:
docker run news-app
Output:

docker command output
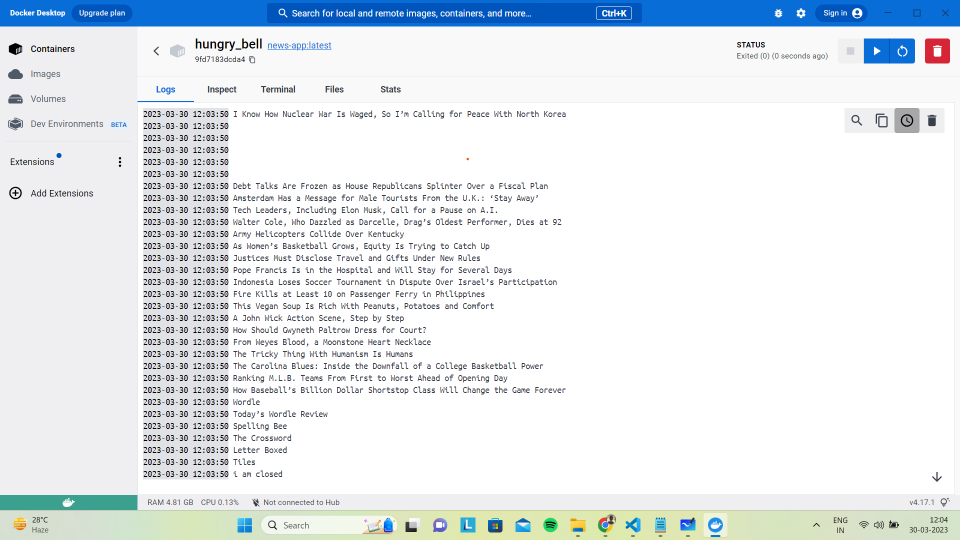
Docker Daemon output
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...