In this article, we will see how to use crawling with Scrapy, and, Exporting data to JSON and CSV format. We will scrape data from a webpage, using a Scrapy spider, and export the same to two different file formats.
Here we will extract from the link http://quotes.toscrape.com/tag/friendship/. This website is provided by the makers of Scrapy, for learning about the library. Let us understand the above approach stepwise:
Step 1: Create scrapy project
Execute the following command, at the terminal, to create a Scrapy project –
scrapy startproject gfg_friendshipquotes
This will create a new directory, called “gfg_friendshipquotes”, in your current directory. Now change the directory, to the newly created folder.

The folder structure of ‘gfg_friendshipquotes’ is as displayed below. Keep the contents of the configuration files as they are, currently.


Step 2: To create a spider file, we use the command ‘genspider ‘. Please see that genspider command is executed at the same directory level, where scrapy.cfg file is present. The command is –
scrapy genspider spider_filename “url_of_page_to_scrape”
Now, execute the following at the terminal:
scrapy genspider gfg_friendquotes “quotes.toscrape.com/tag/friendship/”
This should be created, a spider Python file, called “gfg_friendquotes.py”, in the spiders folder as:

The default code of the gfg_friendquotes.py file is as follows:
Python
import scrapy
class GfgFriendquotesSpider(scrapy.Spider):
name = 'gfg_friendquotes'
allowed_domains = ['quotes.toscrape.com/tag/friendship/']
def parse(self, response):
pass
|
Step 3: Now, let’s analyze the XPath expressions for required elements. If you visit the link, http://quotes.toscrape.com/tag/friendship/ it looks as follows:
URL of the page that we will scrape
We are going to scrape the friendship quotes titles, authors, and tags. When you right-click on Quotes, block it, and select Inspect option, one can notice they belong to class “quote”. As you hover over the rest of the quote blocks, one can notice that all the quotes, in the webpage, have the CSS class attribute as “quote”.
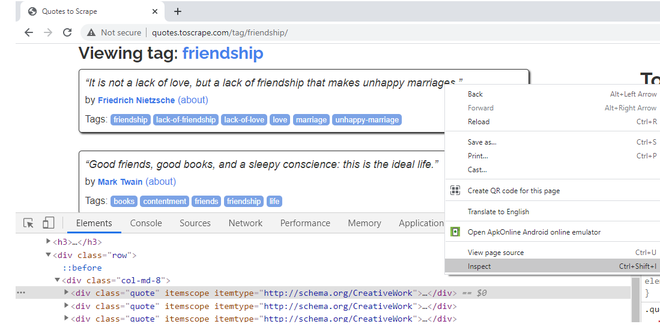
Right-Click, Inspect, check CSS attributes of first Quote block
To extract, the text of the quote, right-click on the first quote, and, say Inspect. The title/text of the quote, belongs to the CSS class attribute, “text”.
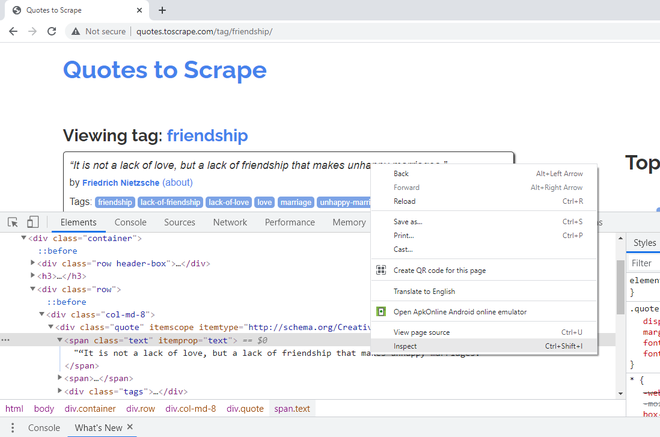
Right-Click first Title, Inspect, check CSS class attributes
To extract the author name of the quote, right-click on the first name, and, say Inspect. It belongs to the CSS class “author”. There is an itemprop CSS attribute, defined here as well with the same name. We will use this attribute in our code.
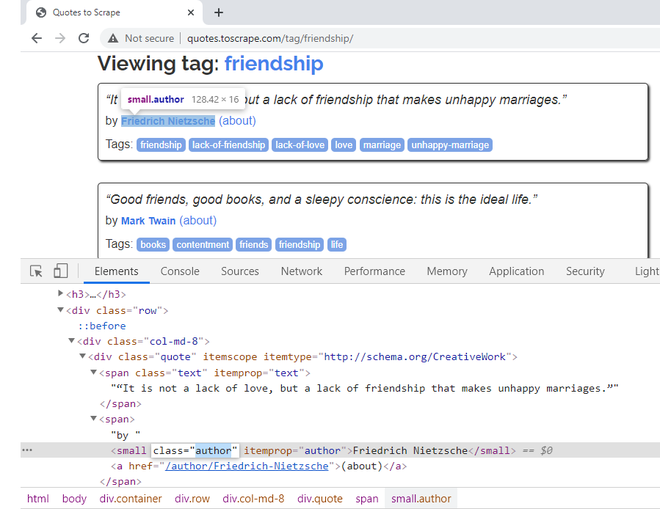
Right-Click on author name to get its CSS attributes
Step 7: To extract the tags of the quote, right-click on the first tag, and, say Inspect. A single tag belongs to the CSS class “tag”. Together, they have an itemprop CSS attribute, “keywords” defined. They also have a “content” CSS attribute, with all the tags in one line. If you observe, the actual text of tags is present inside <a>, hyperlink elements. Hence, fetching from the “content” attribute would be easier.
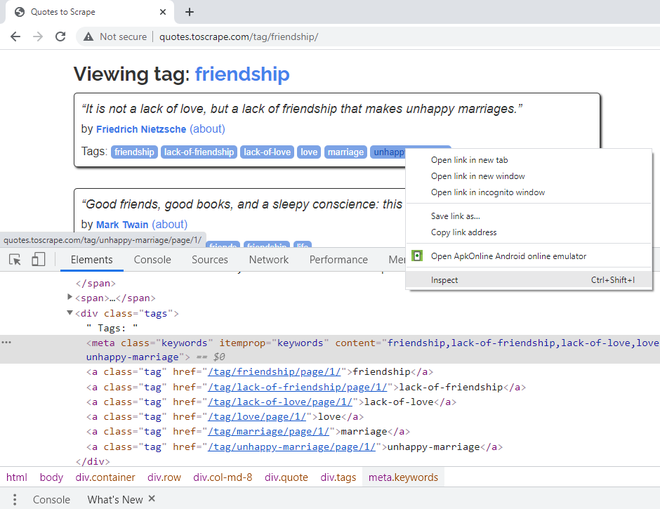
Right-Click on Tags to get its CSS attributes
The final code, for the spider file, after including the XPath expressions, is as follows –
Python3
import scrapy
class GfgFriendquotesSpider(scrapy.Spider):
name = 'gfg_friendquotes'
allowed_domains = ['quotes.toscrape.com/tag/friendship/']
def parse(self, response):
quotes = response.xpath('//*[@class="quote"]')
for quote in quotes:
title = quote.xpath('.//*[@class="text"]/text()').extract_first()
author = quote.xpath(
'.//*[@itemprop="author"]/text()').extract_first()
tags = quote.xpath(
'.//*[@itemprop="keywords"]/@content').extract_first()
yield {'Text': title,
'Author': author,
'Tags': tags}
|
Scrapy allows the extracted data to be stored in formats like JSON, CSV, XML etc. This tutorial shows two methods of doing so. One can write the following command at the terminal:
scrapy crawl “spider_name” -o store_data_extracted_filename.file_extension
Alternatively, one can export the output to a file, by mentioning FEED_FORMAT and FEED_URI in the settings.py file.
Creating JSON file
For storing the data in a JSON file, one can follow any of the methods mentioned below:
scrapy crawl gfg_friendquotes -o friendshipquotes.json
Alternatively, we can mention FEED_FORMAT and FEED_URI in the settings.py file. The settings.py file should be as follows:
Python
BOT_NAME = 'gfg_friendshipquotes'
SPIDER_MODULES = ['gfg_friendshipquotes.spiders']
NEWSPIDER_MODULE = 'gfg_friendshipquotes.spiders'
ROBOTSTXT_OBEY = True
FEED_FORMAT = "json"
FEED_URI = "friendshipfeed.json"
|
Output:

Using any of the methods above, the JSON files are generated in the project folder as:
The extracted data, exported to JSON files
The expected JSON file looks as follows:
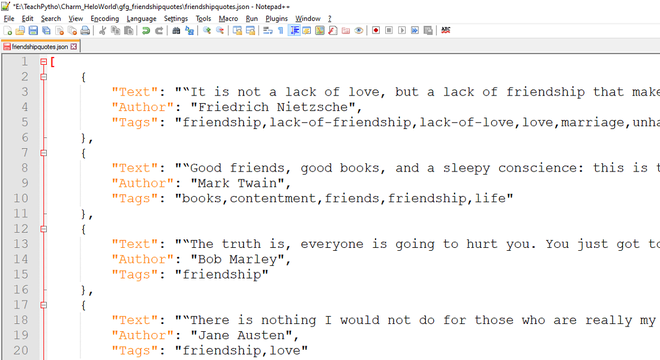
The Exported JSON data, crawled by spider code
Creating CSV file:
For storing the data in a CSV file, one can follow any of the methods mentioned below.
Write the following command at the terminal:
scrapy crawl gfg_friendquotes -o friendshipquotes.csv
Alternatively, we can mention FEED_FORMAT and FEED_URI in the settings.py file. The settings.py file should be as follows:
Python
BOT_NAME = 'gfg_friendshipquotes'
SPIDER_MODULES = ['gfg_friendshipquotes.spiders']
NEWSPIDER_MODULE = 'gfg_friendshipquotes.spiders'
ROBOTSTXT_OBEY = True
FEED_FORMAT = "csv"
FEED_URI = "friendshipfeed.csv"
|
Output:

The CSV files are generated in the project folder as:
The exported files are created in your scrapy project structure
The exported CSV file looks as follows:

The Exported CSV data, crawled by spider code
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...