response.iter_content() – Python requests
Last Updated :
01 Mar, 2020
response.iter_content() iterates over the response.content. Python requests are generally used to fetch the content from a particular resource URI. Whenever we make a request to a specified URI through Python, it returns a response object. Now, this response object would be used to access certain features such as content, headers, etc. This article revolves around how to check the response.iter_content() out of a response object.
How to use response.iter_content() using Python requests?
To illustrate use of response.iter_content(), let’s ping geeksforgeeks.org. To run this script, you need to have Python and requests installed on your PC.
Prerequisites –
Example code –
import requests
print(response)
print(response.iter_content())
for i in response.iter_content():
print(i)
|
Example Implementation –
Save above file as request.py and run using
Python request.py
Output –
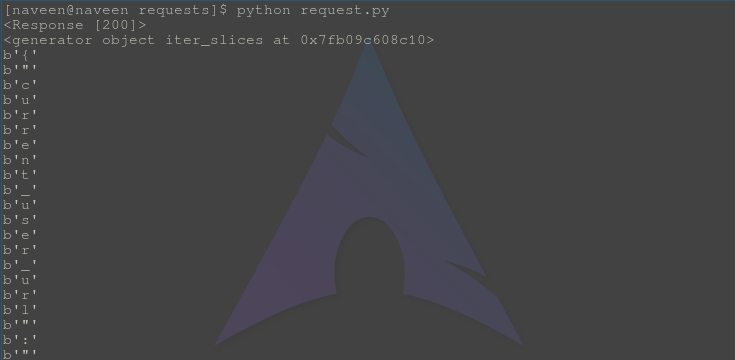
Check that iterator object and iterators at the start of the output, it shows the iterator object and iteration elements in bytes respectively.
Advanced Concepts
There are many libraries to make an HTTP request in Python, which are httplib, urllib, httplib2, treq, etc., but requests is the one of the best with cool features. If any attribute of requests shows NULL, check the status code using below attribute.
requests.status_code
If status_code doesn’t lie in range of 200-29. You probably need to check method begin used for making a request + the url you are requesting for resources.
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...