Replace negative values with latest preceding positive value in Pandas DataFrame
Last Updated :
23 May, 2021
In this article, we will discuss how to replace the negative value in Pandas DataFrame Column with the latest preceding positive value.
While doing this there may arise two situations –
- Value remains unmodified if no proceeding positive value exists
- Value update to 0 if no proceeding positive value exists
Let’s discuss these cases in detail.
Case 1: Value remain unmodified if no proceeding positive value exists
A variable is declared to store the latest preceding positive value initialized with some large negative integer. An iteration of the data frame is then performed column-wise.
- In case the value is negative, it is replaced with the preceding value positive variable if it exists otherwise, it remains unmodified.
- And, in case the value is positive, the preceding positive value variable is updated.
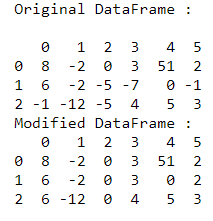
Example:
Python3
import pandas as pd
df = pd.DataFrame([[8, -2, 0, 3, 51, 2],
[6, -2, -5, -7, 0, -1],
[-1, -12, -5, 4, 5, 3]])
print("Original DataFrame : \n")
print(df)
prec_val = -999
for i in range(df.shape[1]):
prec_val = -999
for j in range(df.shape[0]):
cell = df.at[j, i]
if(cell < 0):
if(prec_val != -999):
df.at[j, i] = prec_val
else:
prec_val = df.at[j, i]
print("Modified DataFrame : ")
print(df)
|
Output:
Case 2: Value update to 0 if no proceeding positive value exists
This approach uses the concept of data frame masking in order to replace the negative values of the data frame. The values are traversed from left to right column-wise, in a top to bottom manner. In this approach, initially, all the values < 0 in the data frame cells are converted to NaN.
Pandas dataframe.ffill() method is used to fill the missing values in the data frame. ‘ffill’ in this method stands for ‘forward fill’ and it propagates the last valid encountered observation forward. The ffill() function is used to fill the missing values along the index axis that is specified. This method has the following syntax :
Syntax: DataFrame.ffill(axis=None, inplace=False)
Parameters:
- axis – {0, index 1, column}
- inplace : If True, fill in place.
This is followed by the fillna() method to fill the NA/NaN values using the specified value. Here, we fill the NaN values by 0, since it is the lowest positive integer value possible. All the negative values are thus converted to positive ones. This approach can work on data frames, that don’t have any string values stored. In case there are no preceding positive values, then the negative value is replaced by 0.
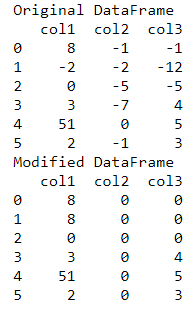
Python3
import pandas as pd
data_frame = pd.DataFrame({'col1': [8, -2, 0, 3, 51, 2],
'col2': [-1, -2, -5, -7, 0, -1],
'col3': [-1, -12, -5, 4, 5, 3]})
print("Original DataFrame")
print(data_frame)
data_frame = data_frame.mask(data_frame.lt(
0)).ffill().fillna(0).astype('int32')
print("Modified DataFrame")
print(data_frame)
|
Output:
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...